



В современном мире уже давно наблюдается тенденция к распространению и доступности данных. В обиход входят такие концепции, как «open data», «open access» и «open source». Научная сфера деятельности также не стоит в стороне, а принимает самое активное участие в распространении и популяризации знаний для всех желающих. На текущий момент благодаря концепции «open access» в сети Интернет доступно огромное количество полнотекстовых научных работ для их последующего изучения без какого-либо ограничения для конечного пользователя. Как правило, доступ к таким данным обеспечивается через веб-сайт с удобным интерфейсом и наличием поисковой строки. Но несмотря на всё это, процесс поиска нужной информации среди огромного количества научных статей и публикаций становится весьма трудоемким, а классический поиск не позволяет решить эту проблему в полной мере.
Для решения таких проблем были разработаны специальные рекомендательные системы, которые с помощью определённых алгоритмов позволяют предоставить не только релевантный результат для поискового запроса, но и сделать результат выдачи пертинентным, то есть спрогнозировать потребность пользователя в определенной информации [1]. Реализация рекомендательных систем базируется на алгоритмах машинного обучения, где задачу по выдаче похожей информации можно свести к решению задачи классификации. В качестве входных данных для алгоритма классификации выступает определённый набор признаков, который описывает сам объект для классификации. Этап подготовки такого набора признаков является одним из самых важных. Когда речь заходит о работе с текстовыми данными, то возникают вопросы о подготовке и выделении таких признаков. Как правило, очень многое зависит от конкретной предметной области и самих объектов, для которых решается задача классификации [2].
В рамках научно-образовательного процесса выделяют два основных объекта: автор и научная статья. Для каждого объекта формируется свой профиль, в рамках которого выполняется дальнейшая аналитическая работа, связанная с определением приоритетных научных направлений, выявлением научных коллективов, проведением различных наукометрических исследований и прочее. Как правило, для построения научного профиля автора или профиля научной статьи используется явный набор признаков, указанный либо самим автором о себе, либо указанный в параметрах научной статьи [3]:
? для автора – указанные им личные данные, научные интересы, перечень его публикаций, научные достижения и производные значения.
? для научной статьи – ключевые слова, наукометрические показатели, язык, тематика, периодическое издание и производные значения.
Целью данной работы является дополнение и расширение профиля научной статьи путем извлечения из аннотации признака, отвечающего за тип научного результата. Данный признак будет использоваться наряду с другими признаками и будет подаваться на вход как перечень входных параметров для алгоритмов классификации. Дополненный набор признаков должен привести к повышению точности работы рекомендательной системы и сокращению заведомо нерелевантных данных в рекомендательном наборе.
Гипотеза о типе научного результата
Под типом научного результата понимаются представленные в научной статье выводы и заключения. Описываемый подход будет базироваться на принципах потребности пользователя в определенном типе научного результата, который ему необходимо получить исходя из его конкретных нужд и задач.
Основным предположением будет то, что каждый пользователь может нуждаться либо в теоретической информации, либо в практической. Два данных класса могут служить верхнеуровневым представлением типа научного результата, который был получен в рамках научной статьи. Но потребность пользователя может не ограничиться только разделением на теорию и практику. Возможно, ему потребуется некоторая конкретика результата в зависимости от того, какую цель он преследует. Можно сформулировать гипотезу о потребностях пользователя следующим образом:
? Пользователь хочет ознакомиться с предметной областью и ее основами.
? Пользователь хочет понять, в каком направлении развивается интересующая его область и какие есть проблемы.
? Пользователь хочет понять, каких результатов уже удалось добиться на текущий момент времени.
? Пользователь хочет понять, что уже опробовано и готово к использованию.
Данную гипотезу можно представить в виде следующей схемы по типам научного результата исходя из потребности пользователя (см. рис. 1).
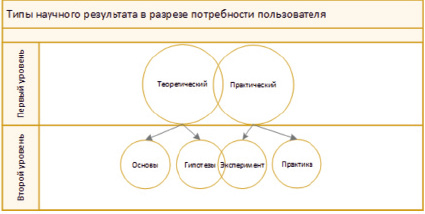
Рис. 1. Гипотеза о типах научного результата
Предлагаемый метод
В данной работе задача будет состоять в том, чтобы разделить научные статьи по двум типам: теоретический и практический. Решение этой задачи состоит из нескольких этапов.
1. Подготовка текстовых данных. Одним из главных шагов в работе с текстовыми данными является подготовка и очистка текста для последующего анализа, а также некоторые подходы по преобразованию текстов в иные структуры [4]. Обработка текста включает в себя удаление стоп-слов, удаление редких слов, лемматизацию, удаление специальных символов и ряд других действий. В данной работе применялась лемматизация, удалялись небуквенные символы и отбрасывались слова длиной менее трех символов.
2. Определение значимых словосочетаний. Данный шаг включает в себя два дополнительных действия [5]: генерацию словосочетаний и оценку полученных словосочетаний. Для того, чтобы словосочетания отражали научный результат, было введено ограничение, что одно из слов в словосочетании должно быть причастием. Соответственно, слова с такой частью речи не подвергались лемматизации, но приводились к единой форме с помощью расстояния Левенштейна. В работе использовались словосочетания с количеством слов равным два и три. При формировании словосочетаний учитывался тот факт, что два значащих слова могут находиться не только рядом, но и на некотором расстоянии друг от друга. При генерации словосочетаний было использовано «окно» равное трем.
После генерации словосочетаний необходимо определить, является ли данное словосочетание действительно значимым, а не случайным набором слов. Для решения этой задачи были использованы инструменты для проверки статистических гипотез: t-критерий Стьюдента и критерий Хи-квадрат.
t-критерий Стьюдента вычисляется следующим образом:
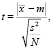 (1)
(1)
где 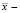 выборочное среднее (вероятность встретить словосочетание), m – ожидаемое значение (произведение вероятностей для каждого слова), s2 – дисперсия (в данном случае примерно соответствует
выборочное среднее (вероятность встретить словосочетание), m – ожидаемое значение (произведение вероятностей для каждого слова), s2 – дисперсия (в данном случае примерно соответствует 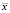 ), N – размер выборки.
), N – размер выборки.
Хи-квадрат вычисляется следующим образом:
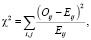 (2)
(2)
где Oij – фактическое количество словосочетаний, Eij – ожидаемое количество словосочетаний.
Выполнив таким образом расчёт представленных значений для каждого словосочетания в исходном наборе научных статей, можно выполнить их фильтрацию в соответствии с табличными значениями вероятности возникновения ошибки. В данном случае использовалась ошибка равная 0,005.
3. Нечеткое разделение данных на классы. Данный шаг подразумевает проведение кластеризации очищенного набора данных на два класса. В качестве алгоритма нечеткой кластеризации будет использоваться алгоритм латентного размещения Дирихле. С помощью данного алгоритма можно провести кластеризацию по словосочетаниям и построить обучающую модель, которая позволит определить вероятность отнесения научной статьи к каждому из двух типов научного результата.
Метод латентного размещения Дирихле основан на вероятностной модели [6]:
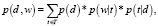 (3)
(3)
где d – документ, w – слово, t – тема, T – множество тем, p(d) – априорное распределение на множестве документов, p(w|t) – условное распределение слова w в теме t, p(t|d) – условное распределение темы t в документе d.
Проведенный эксперимент
Данный эксперимент был выполнен с использованием научных статей из базы данных ВИНИТИ, относящихся к рубрике «Информатика». При подготовке словосочетаний для последующего анализа использовались аннотации научных статей в количестве 5000. Для алгоритма латентного размещения Дирихле количество тем было задано равное двум, что соответствует верхнеуровневому разделению научных статей по типу результата на «Теоретический» и «Практический».
На графиках (см. рис. 2–3) приведены ключевые словосочетания, полученные с использованием представленного метода и отсортированные в порядке убывания по рассчитанной частоте словосочетания по каждому типу результата.
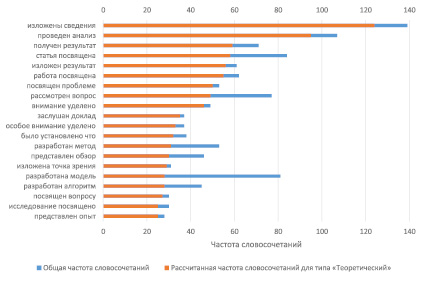
Рис. 2. Топ-20 наиболее релевантных словосочетаний для типа «Теоретический»
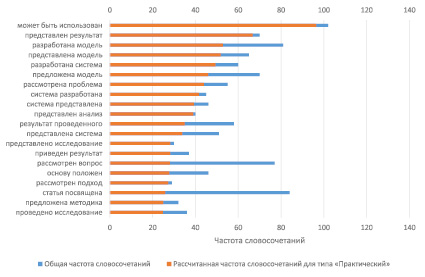
Рис. 3. Топ-20 наиболее релевантных словосочетаний для типа «Практический»
Из представленных графиков видно, что каждый тип результата описан своим набором словосочетаний. Для типа «Практический» отчетливо видны словосочетания, которые отражают именно практический результат, который был достигнут: разработана система, разработана модель, приведен результат и прочее. Для типа «Теоретический» также были выделены словосочетания, которые имеют в большей степени теоретический окрас: посвящено проблеме, рассмотрен вопрос, внимание уделено и прочее.
Однако можно наблюдать и некоторое пересечение похожих словосочетаний. Это связано с тем, что данное словосочетание с разной степенью относится к каждому из типов результата, следовательно, подход на основе нечеткой модели кластеризации в данном случае вполне оправдан. Но для таких словосочетаний необходим отдельный способ обработки и новый тип, который будет включать в себя «шаблонные» фразы и выражения.
Практическое преимущество представленного подхода заключается в том, что для различных направлений научной деятельности используется собственная терминология, индивидуальные обороты и словосочетания. Чтобы охватить каждое научное направление и составить для него свой словарь в ручном режиме – придется прибегнуть к огромному количеству экспертов по разным отраслям науки, что является весьма трудозатратным и малореализуемым.
Заключение
В данной статье был рассмотрен метод, который позволяет выделить новый признак из аннотации научных статей, характеризующий тип результата. На текущий момент данный подход позволяет выделить только два верхнеуровневых типа научного результата. Полученные типы предполагается использовать для уточнения и конкретизации рекомендаций пользователям на основе их поисковых запросов в научных аналитических системах.
При попытке использования данного метода для деления исходных научных статей сразу на вложенные уровни – возникает зашумленность отдельных типов «мусорными» словосочетаниями, и всё это приводит к невозможности однозначной идентификации каждого конкретного типа. В качестве решения представленной проблемы стоит уделить больше внимания специфике фильтрации и обработки текстовых данных, а также использовать другие части речи и учитывать их последовательность в предложении при определении новых типов научного результата [7].
Работа выполнена при поддержке гранта РФФИ № 15-07-08742.
Библиографическая ссылка
Кузнецов И.А. Метод автоматизированной классификации научных статей по типу результата в научных аналитических системах // Современные наукоемкие технологии. 2018. № 2. С. 59-63;URL: https://top-technologies.ru/ru/article/view?id=36907 (дата обращения: 06.07.2026).