



В настоящее время многие образовательные учреждения испытывают сложности, связанные со своевременным обновлением компьютерного оборудования, а также с установкой и поддержкой программного обеспечения. Выделенных для этих целей финансовых средств часто не хватает для покупки лицензий ПО для каждой рабочей машины учреждения, вследствие чего сильно ограничиваются возможности преподавателей и учащихся. Ввиду отсутствия кадров, достаточно квалифицированных в сфере ИТ, отдельной проблемой также встает вопрос правильной установки данного программного обеспечения.
Для решения описанных выше проблем предлагается создание облачного ресурсного центра (ОРЦ), который реализует услугу DaaS (Desktop as a Service – рабочий стол в качестве сервиса) и предоставляет в аренду конечным пользователям виртуальный рабочий стол с установленным программным обеспечением [2–4, 7]. Пользователям, как правило, не требуется виртуальная машина на продолжительный промежуток времени, поэтому возможно разделение лицензий ПО между ними по времени. Таким образом, несколько образовательных организаций могут совместно использовать одни и те же лицензии, что позволяет экономить денежные средства.
Установка и поддержка программного обеспечения осуществляется на стороне ОРЦ. Пользователи для получения услуги должны отправлять запрос на Web-портал центра с указанием необходимой конфигурации виртуальной машины, количества необходимых машин и времени использования. Так как количество лицензий на программное обеспечение может быть ограничено, то необходимо строго отслеживать, чтобы в нужное для пользователя время в наличии находилось достаточное количество свободных лицензий. Для этих целей был написан REST сервис на языке C++, схема его взаимодействия с остальными компонентами ОРЦ представлена на рис. 1.
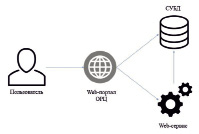
Рис. 1. Схема взаимодействия компонентов ОРЦ
Пользователь может взаимодействовать только с Web-порталом, который, в свою очередь, часть данных получает напрямую из СУБД. Далее, после составления пользователем заявки, портал отправляет запрос к Web-сервису (далее – сервис), чтобы проверить, достаточно ли в наличии свободных лицензий на заданный промежуток времени. Сервис обрабатывает запросы вида
Reqi = (Imagei, VMCounti, tStarti, tEndi),
где Imagei – идентификатор образа, VMCounti – количество виртуальных машин, [tStarti, tEndi] – время работы виртуальных машин, с точностью до минут. Также существуют два варианта обработки запроса: проверка того, хватит ли количества лицензий (CheckLicenses) или проверка и временное бронирование лицензий на ПО (BookLicenses), чтобы дать пользователю время, перед тем как он примет окончательное решение.
Чтобы ответить на запрос, сервис хранит информацию о количестве занятых лицензий для каждого ПО для каждой минуты текущего учебного года. Благодаря такому подходу вычислительная сложность не зависит от количества обработанных заявок и не приводит к замедлению работы с течением времени.
Бронирование лицензий происходит при отправке POST-запроса с необходимыми параметрами, представленными в формате JSON. Всю работу с запросами берёт на себя Crow Framework [6], который, помимо прочего, содержит библиотеку для десериализации JSON. Запросы к сервису помещаются в очередь, после чего обрабатываются отдельными потоками внутри Crow Framework. При инициализации сервиса также можно указывать количество запускаемых потоков.
Для того, чтобы проверить наличие свободных лицензий, необходимо иметь данные о составе дискового образа, то есть информацию о том, какое программное обеспечение на него установлено. Эти сведения не передаются напрямую в сервис, поэтому необходимо извлекать их из базы данных (БД), обращение к которой происходит посредством библиотеки libpqxx [1]. Данная библиотека имеет два основных класса: Connection (подключение к БД) и Transaction (транзакция с запросом). В рамках одного подключения может существовать только одна активная транзакция, что, очевидно, вызывает затруднения для многопоточной обработки запросов. Существует несколько вариантов решения этой проблемы:
1. Одно подключение на всё приложение. Этот вариант реализуется довольно просто – с помощью расстановки блокировок перед использованием подключения. Недостаток данного решения заключается в поочередном взаимном ожидании потоков, что может сильно замедлять работу.
2. Создание нового подключения на каждый запрос. Этот способ убирает зависимость между запросами, однако и у него есть очень слабые стороны. Во-первых, установка соединения между базой данных и сервисом является медленной операцией. Во-вторых, чрезмерное количество соединений с базой данных может привести к замедлению работы базы данных в целом, увеличению времени отклика на другие запросы. И, в-третьих, данное решение не позволяет в полной мере использовать заранее подготовленные запросы, в которых план выполнения в БД строится один раз, а вызывается многократно.
3. Пул подключений. Создаётся специальный класс, который хранит в себе список подключений. При обращении к базе извлекается первое свободное подключение, а в случае, когда его нет, ожидается его появление. После выполнения запроса к базе данных подключение возвращается обратно в пул. Таким образом, легко ограничивается количество подключений к базе данных, а для каждого подключения в пуле осуществляется подготовка всех возможных вариантов SQL запросов (их около десятка), и, кроме того, распараллеливается обращение к БД между потоками. Этот способ потребует расширения стандартных классов библиотеки libpqxx и определения размера пула опытным путём. Таким образом, ввиду отсутствия критических недостатков, как в случае первых двух вариантов, для реализации сервиса был использован данный способ.
Для проведения эксперимента сервис и база данных были развёрнуты на одной виртуальной машине (8 ядер 3GHz, 4 GB RAM, 20 GB HHD). Для БД были выделены отдельные четыре ядра, оставшиеся использовались сервисом. Управление ядрами проводилось с помощью программы taskset [5].
С целью имитации клиента было написано два модуля на языке C#: основной (Main) и вспомогательный (VUser). Полная схема работы представлена на рис. 2.
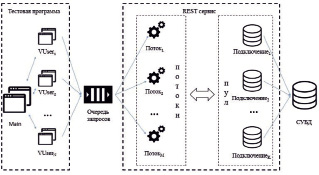
Рис. 2. Структура тестового стенда
Модуль VUser представляет собой отдельного «виртуального пользователя», который отправляет μ запросов в секунду (CheckLicenses или BookLicenses, в зависимости от настройки) в течение T секунд. Каждый запрос, дождавшись своей очереди, начинает обрабатываться одним из M потоков. Получение информации из БД осуществляется с помощью пула, который возвращает любое из свободных в данный момент подключений (общее количество подключений – K).
Основной блок (Main) запускает одновременно N модулей VUser, передавая им параметры μ и T, ожидает их завершения, после чего собирает и обрабатывает результаты (среднее количество запросов в секунду, которое обрабатывалось сервисом, среднее время задержки). Параметрами μ и N можно контролировать интенсивность генерируемых запросов в секунду:
λ = μ*N.
Для того, чтобы исключить влияние некоторых факторов (например, неодновременные старт и завершение всех модулей VUser), при обработке не учитываются первые и последние 10 % времени работы.
В первую очередь было проведено исследование производительности и масштабируемости сервиса с целью оценки зависимости количества обрабатываемых в секунду запросов от количества используемых ядер. Для этого был проведён эксперимент со следующими показателями:
- интенсивность от 1500 запросов до 6500, с шагом в 500 запросов;
- длительность теста – 60 секунд;
- количество выделенных потоков и размер пула подключений – 24;
- количество ядер для сервиса – от одного до четырёх.
Каждый раз вызывалась проверка с блокировкой – BookLicenses. Результаты представлены на рис. 3.
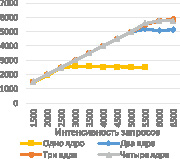
а) б)
Рис. 3. Графики зависимости количества обрабатываемых запросов в секунду (а) и среднего времени ожидания (б) от интенсивности запроса для разного количества ядер
На графиках видно, что количество обработанных запросов в секунду линейно возрастает относительно интенсивности до тех пор, пока не достигает границы возможностей сервиса. При превышении этой точки заявки в очереди сервиса начинают накапливаться, время ожидания начинает расти линейно. Продолжительная нагрузка на сервис может приводить к превышению времени ожидания ответа или к выводу сервиса из работоспособного состояния.
Для того, чтобы сделать вывод о масштабируемости, было проведено сравнение результатов для одногого, двух, трех и четырех ядер. Результаты показали, что на одном ядре сервис может обрабатывать до 2500 запросов в секунду, тогда как на двух – уже около 5000 (прирост производительности в 2 раза). Но если сравнивать два и три ядра, то можно заметить, что разница между ними уже не столь велика – всего около 700 запросов в секунду, между тремя и четырьмя – её практически нет. Это говорит о том, что данный способ не подходит для наращивания производительности и для этой цели следует искать другие методы.
Основные причины задержек в работе сервиса:
1. Блокировки при проверке расписания. Так как потоки могут читать и изменять одни и те же данные, к ним необходим последовательный доступ (пока один запрос обрабатывается, остальные ожидают своей очереди). Время ожидания можно уменьшить, если блокировать ресурсы по частям или использовать потоконезависимые типы данных.
2. Оптимальное соотношение количества потоков и размера пула. Очевидно, что при увеличении числа одновременно работающих потоков будет увеличиваться производительность. Но этот рост ограничен, так как, начиная с определенного числа потоков, затраты на использование и переключение между потоками перестанут быть целесообразными. С размером пула всё гораздо сложнее – требуется не только оптимизация времени работы сервиса, но и работы базы данных. Оптимальные значения находятся экспериментальным путем.
3. Время ответа от базы данных. Из-за необходимости получения дополнительных данных из БД, нагрузка при каждом запросе создается не только на сервис, но и на базу, что ведет к увеличению её времени отклика. В результате производительность может снижаться именно из-за простоя сервиса во время ожидания данных от БД. Существует два способа решения этой проблемы: увеличение ресурсов для базы данных и сокращение количества обращений сервиса. Эффективной мерой в данной ситуации будет отказ от обращения к базе за редко изменяемыми данными и хранение их у себя (с периодическим обновлением).
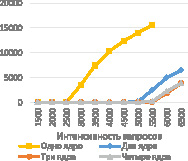
Далее было проведено исследование влияния блокировок потоков на производительность сервиса, в рамках которого вместо функции BookLicenses использовалась CheckLicenses, так как она не изменяет данные в сервисе. Для выявления возможного повышения уровня масштабируемости эксперимент проводился для трех и четырех ядер. Количество потоков и размер пула подключений к БД был оставлен без изменений. Результаты представлены на рис. 4.
Для лучшей визуализации отсутствия прироста в производительности, на рис. 4 также отражены результаты предыдущего эксперимента, взятые из рис. 3. Анализ графиков показал, что внутренние блокировки на данный момент не оказывают заметного влияния на производительность сервиса.
Необходимость следующего эксперимента обусловлена потребностью определения оптимального количества потоков и размера пула подключений к БД. В рамках данного исследования оба параметра изменялись в диапазоне от 4 до 24.
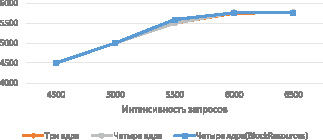
Рис. 4. Графики зависимости количества запросов в секунду при отсутствии блокировки на бронирование от интенсивности запросов для разного количества ядер
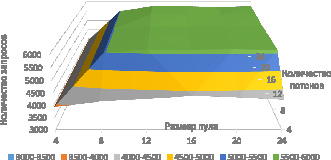
Рис. 5. График зависимости обрабатываемых запросов в секунду от количества потоков и размера пула
Экспериментальное исследование проводилось на четырех ядрах с интенсивностью потока λ = 6500 и использованием запросов с временной блокировкой программного обеспечения (BookLicenses). Результаты представлены на рис. 5.
При увеличении количества потоков и размера пула с 4 до 8 на графике заметно значительное увеличение производительности. В диапазоне от 8 до 12 оно незначительно, от 12 и выше его нет. Если количество потоков меньше размера пула – изменения производительности также не наблюдается, так как часть подключений к базе никогда не используется, аналогично не даёт прироста производительности количество потоков, превосходящее число возможных подключений. Следовательно, идеальное соотношение количества потоков / размера пула подключений для данной конфигурации 12 / 12.
Экспериментальные исследования показали значительное увеличение производительности при использовании двух ядер, вместо одного, при трёх ядрах имелся незначительный дальнейший рост, а при четырёх он отсутствовал. Дальнейшее исследование показало отсутствие влияния блокировок, связанных с синхронизацией потоков. Также было выявлено оптимальное соотношение количества потоков, работающих на выделенных ядрах, и размера пула подключений к базе данных. В будущем планируется провести исследование влияния задержки ответа от БД. Также необходимо снизить загрузку базы данных сервисом, путём хранения редко изменяемых данных в оперативной памяти.
Исследования проведены при финансовой поддержке Министерства образования Оренбургской области (грант № 37 от 30 июня 2016 г.), РФФИ и Правительства Оренбургской области (проект № 16-47-560335), Президента Российской Федерации, стипендии для молодых ученых и аспирантов (СП-2179.2015.5).
Библиографическая ссылка
Пилипенко В.В., Москалева Т.С., Полежаев П.Н. ИССЛЕДОВАНИЕ ПРОИЗВОДИТЕЛЬНОСТИ СЕРВИСА ОБЛАЧНОГО РЕСУРСНОГО ЦЕНТРА ДЛЯ ОТСЛЕЖИВАНИЯ ИСПОЛЬЗОВАНИЯ ЛИЦЕНЗИЙ НА ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ // Современные наукоемкие технологии. 2017. № 3. С. 32-37;URL: https://top-technologies.ru/ru/article/view?id=36612 (дата обращения: 13.06.2026).