



Интеллектуальные системы (ИС) принятия решений находят применение во множестве областей: промышленности, медицине, научно-исследовательской деятельности, образовании. В настоящее время подобные системы всё чаще используются для решения задач в критических областях, что влечет за собой повышение требований к их надёжности. Особую роль при этом играет обеспечение качества баз знаний интеллектуальных систем, являющихся центральным звеном ИС, в то же время способы их отладки на сегодняшний день всё ещё не формализованы. В большинстве случаев отладкой занимаются эксперты, что влияет на увеличение стоимости разработки и не гарантирует отсутствия ошибок в базах знаний.
В литературе описаны различные подходы для отладки баз знаний проверки корректности и полноты баз знаний [2–4]. Некоторые ошибки в знаниях могут быть выявлены только в процессе тестирования. К таким относятся ошибки, связанные с противоречивостью самой предметной области, например ошибки вида «забывание об исключении» [1]. В то же время ряд ошибок, связанных со структурой знаний, так называемые структурные ошибки, могут быть обнаружены и исправлены на стадии статической отладки базы знаний.
Отсутствие структурных ошибок не гарантирует отсутствия ошибок в знаниях, однако повышает эффективность принятия решений за счет приведения базы знаний в состояние статической корректности [1] и соответствующего уменьшения времени на принятие решения. Поэтому первым этапом отладки базы знаний должна быть статическая отладка.
В работах [7–11] приведены некоторые структурные ошибки в базах знаний и описаны алгоритмы их обнаружения, однако формализация ошибок имеется лишь частично. Среди наиболее известных автоматизированных средств верификации необходимо отметить программное обеспечение NuSMV, прошедшее в своем развитии несколько этапов, позволяющее выявлять ряд структурных ошибок для определенного класса продукционных баз знаний и имеющее в своем составе NuSMV язык программирования [6].
В данной работе обобщается информация о структурных ошибках и предлагаются формальные модели, которые могут быть использованы для автоматической верификации структур баз знаний.
Формализация структурных ошибок в продукционных базах знаний
Наиболее распространённый способ представления баз знаний интеллектуальных систем – продукции. Продукционную базу знаний можно представить в следующем виде:
P = (F, R, G, C, I), (1)
где F – множество фактов о решаемой проблеме; R – множество правил вида
rm: если fi и fj … и fn то fk, (2)
G – множество целей; C – множество разрешенных комбинаций фактов; I – интерпретатор правил, реализующий вывод.
Пусть S – множество входных фактов, т.е. фактов, устанавливаемых пользователем в интеллектуальной системе. S ⊂ F.
База знаний может быть представлена в виде И/ИЛИ графа. Например, пусть база знаний содержит следующие правила:
r1: если s1 и s2, то f1;
r2: если s2 и s3, то f2;
r3: если s3 и s4 и s5, то f3;
r4: если f1, то g1;
r5: если f2 и f3, то g2.
Тогда приведённым правилам соответствует И/ИЛИ граф на рис. 1.
Правило ri вида
если 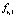 и
и 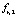 …
… 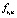 , то
, то 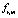 (3)
(3)
можно представить в виде пары:
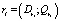 ,
,
где 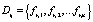 и
и 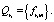
Как видно из представления, 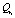 состоит из единственного элемента, далее обозначаемого как
состоит из единственного элемента, далее обозначаемого как 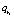 .
.
Пусть L – множество цепочек вывода.
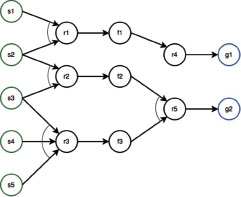
Рис. 1. И/ИЛИ граф базы знаний
Определение 1. Цепочка вывода li – последовательность правил 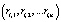 такая, что
такая, что 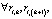
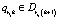 при k = 2, …, (n – 1).
при k = 2, …, (n – 1).
Тогда для графа, приведённого на рис. 1, L = {l1, l2, l3, l4, l5, l6, l7, l8}, где l1 = (r1); l2 = (r2); l3 = (r3); l4 = (r4); l5 = (r5); l6 = (r1, r4); l7 = (r2, r5); l8 = (r3, r5).
Определение 2. Начало цепочки вывода li вида 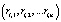 – множество фактов в условии выполнения первого правила,
– множество фактов в условии выполнения первого правила, 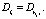
Определение 3. Конец цепочки вывода li вида 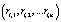 – следствие последнего правила,
– следствие последнего правила, 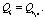
Определение 4. Структурной ошибкой в продукционной базе знаний называется ошибка, обнаружимая в ходе анализа И/ИЛИ графа. Базы знаний, в которых отсутствуют структурные ошибки, являются статически корректными. Классификация структурных ошибок приведена на рис. 2.
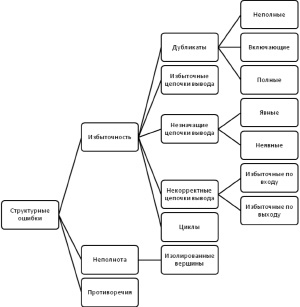
Рис. 2. Классификация структурных ошибок в продукционных базах знаний
Рассмотрим подробнее формальные модели ошибок класса «избыточность».
Определение 5. Правила ri и rj называются дубликатами, если 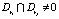 и
и 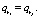
Выделяют 3 вида дубликатов:
- включающие дубликаты;
- полные дубликаты;
- неполные дубликаты.
Определение 6. Правила ri и rj называются включающими дубликатами, если 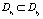 , при этом
, при этом 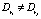 и
и 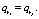 В этом случае правило ri называется включаемым.
В этом случае правило ri называется включаемым.
Для исправления подобной ошибки требуется удалить все правила-дубликаты, кроме включаемого.
Определение 7. Правила ri и rj называются полными дубликатами, если 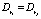 и
и 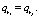
Решением в данном случае является удаление всех дубликатов, кроме одного.
Определение 8. Правила ri и rj называются неполными дубликатами, 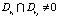 и
и 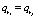 , при этом
, при этом 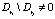 и
и 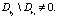
Для исправления ошибки вида «неполные дубликаты» не существует универсального способа, в каждом конкретном случае необходимые изменения определяются экспертом.
Определение 9. Цепочка вывода li называется избыточной, если 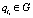 и ¬qlj такой, что
и ¬qlj такой, что 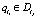 и
и 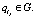
На рис. 3 приведен пример избыточной цепочки вывода l1 = (r1, r2):
r1: если s1 и s2, то f2;
r2: если f1 и f2, то f3;
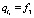 ;
;
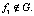
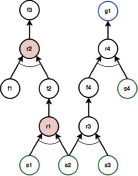
Рис. 3. Избыточная цепочка вывода
Избыточные цепочки вывода могут быть удалены из базы знаний.
Определение 10. li вида 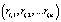 называется незначащей цепочкой вывода, если
называется незначащей цепочкой вывода, если 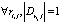 при j = 1, …, n.
при j = 1, …, n.
Выделяют 2 вида незначащих цепочек вывода:
- явные;
- неявные.
Определение 11. Незначащая цепочка вывода li называется явной, если ?rj такое, что 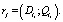
Явные незначащие цепочки вывода могут быть удалены из базы знаний.
Определение 12. Незначащая цепочка вывода li называется неявной, если ¬?rj такое, что 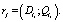
Неявная незначащая цепочка вывода не является критичной ошибкой, однако допускает оптимизацию за счет сведения к предшествующему или последующему правилу.
Определение 13. Сведением к предшествующему правилу rn незначащей цепочки вывода li при условии, что 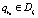 , называется создание правила rm такого, что
, называется создание правила rm такого, что 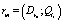 , и удаление li и rn из базы знаний.
, и удаление li и rn из базы знаний.
Определение 14. Сведением к следующему правилу rn незначащей цепочки вывода li при условии, что 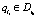 , называется создание правила rm такого, что
, называется создание правила rm такого, что 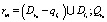 , и удаление li и rn из базы знаний.
, и удаление li и rn из базы знаний.
Различают 2 типа некорректных цепочек вывода:
- цепочки, избыточные по входу;
- цепочки, избыточные по выходу.
Определение 15. Цепочка вывода li называется избыточной по входу, если 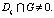
Решением в данном случае является удаление избыточной по входу цепочки.
Определение 16. Цепочка вывода li называется избыточной по выходу, если 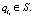
Для исправления ошибки цепочку, избыточную по выходу, требуется удалить.
Определение 17. Цепочка вывода li называется циклом, если 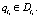
Цикл является критичной ошибкой, однако некорректное правило для удаления не может быть выбрано автоматически, поэтому решение по исправлению должно приниматься экспертом. Частным случаем цикла является простой цикл.
Определение 18. Правило ri называется простым циклом, если 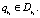
Простой цикл должен быть удален из базы знаний.
Рассмотрим класс ошибок «неполнота».
К данному классу ошибок относятся изолированные вершины.
Определение 19. Вершина 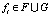 называется изолированной, если ¬?rj такое, что
называется изолированной, если ¬?rj такое, что 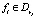 или
или 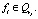
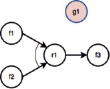
Рис. 4. Изолированная вершина
Вершина g1 на рис. 4 является изолированной, т.к. нет правил, ведущих к ней.
Способ исправления ошибки зависит от типа вершины: если изолированная вершина – входной факт или цель, то необходимо добавить правила; в противном случае вершина может быть удалена из базы знаний.
Рассмотрим класс ошибок «противоречия».
Пусть C – множество разрешенных комбинаций фактов, тогда 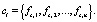
Тогда определим противоречащие цепочки вывода.
Определение 20. Цепочки вывода li и lj называются противоречивыми, если ?fk, такой, что 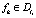 и
и 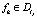 , и ¬?cm такая, что
, и ¬?cm такая, что 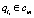 и
и 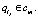
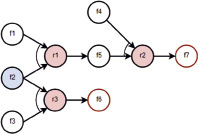
Рис. 5. Противоречивые цепочки вывода
На рис. 5 l1 = (r1, r2) и l2 = (r3) являются противоречивыми:
- 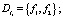
- 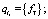
- 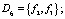
- 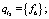
- 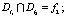
- нет ck = (f6, f7).
Исправление ошибки вида противоречивые цепочки вывода должно производиться экспертом, либо за счет добавления разрешенной комбинации фактов, либо за счет изменения или удаления правил. Отметим, что устранение описанных выше структурных ошибок приводит базу знаний в состояние статической корректности и является необходимым условием отладки, но не гарантирует ошибок иного рода, например, связанных с противоречивостью самой предметной области, обнаружение которых возможно с помощью тестирования [1, 5].
Заключение
В работе приведена классификация структурных ошибок в продукционных базах знаний интеллектуальных систем. Выделено 3 типа структурных ошибок: ошибки класса избыточности, ошибки неполноты и противоречия. К первому типу отнесены дубликаты, избыточные цепочки вывода, незначащие цепочки вывода, некорректные цепочки вывода и циклы. Ошибка вида «изолированные вершины» рассмотрена как ошибка класса неполноты. Противоречия в базах знаний представлены в работе противоречивыми цепочками вывода. Каждая рассмотренная ошибка формализована и снабжена описанием способа её исправления.
Формальная модель структурных ошибок может быть использована в качестве основы для проведения автоматической верификации структуры продукционных баз знаний на этапе статической отладки.
Библиографическая ссылка
Долинина О.Н., Сучкова Н.К., Резчиков А.Ф. ФОРМАЛЬНЫЕ МОДЕЛИ СТРУКТУРНЫХ ОШИБОК В БАЗАХ ЗНАНИЙ ИНТЕЛЛЕКТУАЛЬНЫХ СИСТЕМ // Современные наукоемкие технологии. 2017. № 3. С. 7-11;URL: https://top-technologies.ru/ru/article/view?id=36607 (дата обращения: 15.06.2026).
DOI: https://doi.org/10.17513/snt.36607