



Реалии современного мира ставят задачи совершенствования самых разных систем, связанные с усложнением и ускорением протекающих процессов, повышением требований к качеству результатов. Сказанное относится ко многим сферам жизни и деятельности человека, что актуализирует поиск новых общенаучных подходов к изучению и совершенствованию сложных систем. Одним из таких подходов стал кластерный подход, который относится к сферам экономики, управления, информатики, различных точных наук. Общенаучное понимание кластера позволяет вести речь о том, что кластер – это объединение нескольких однородных элементов, которое может рассматриваться как самостоятельная единица, обладающая определенными свойствами.
Исследователи отмечают, что понятие кластера впервые было определено в статистике, где возникла необходимость выделения и описания совокупностей однородных элементов [5]. В дальнейшем это понятие стало использоваться в экономических теориях (производственный кластер), при описании физических объектов, явлений и процессов (особые группы атомов или молекул, элементарных частиц, звёздных скоплений), в лингвистике и др. Данный термин прочно вошел в теорию и практику информационных технологий, где ведется речь про кластеры как единицы хранения данных, подмножества результатов поиска, группы компьютеров, объединённых в единый вычислительный ресурс. В настоящей статье проводится анализ кластеров именно последнего типа, описываются перспективные направления использования кластеров для построения технической инфраструктуры электронной информационно-образовательной среды.
Рассматриваемый нами кластер – это группа компьютеров, объединённых высокоскоростными каналами связи, представляющая с точки зрения пользователя единый аппаратный ресурс. Физически такой кластер может представлять собой два или более компьютера, объединенных в единую систему высокого уровня доступности посредством специального программного и аппаратного обеспечения. Внутренняя организация кластера предполагает согласованную работу всех узлов для достижения поставленной цели. Такими целями могут быть высокая устойчивость (High Availability, HA), высокая вычислительная способность (High Performance, HP), распределение нагрузки (Network Load Balancing, NLB) [1].
Кластеры высокой устойчивости (отказоустойчивые кластеры, кластеры высокой доступности) гарантируют минимальное время простоя за счёт аппаратной избыточности. Это используется для создания отказоустойчивых систем хранения данных, выполнения ответственных приложений, создания сервисов обслуживания большого числа клиентов.
Кластеры высокой вычислительной способности (вычислительные кластеры) обеспечивают уменьшение времени расчетов за счёт распределения задачи между многими узлами сети. Важным в такой конфигурации оказывается и наличие высокопроизводительных каналов связи между узлами кластера, позволяющих обмениваться информацией параллельно выполняемым процессам. Если условие по наличию высокоскоростных линий связи не выполняется, то речь можно вести про грид-системы распределенных вычислений, которые также позволяют решать задачи высокой вычислительной сложности, однако применимы не во всех ситуациях.
В некоторой степени схожие задачи, связанные с усилением общей вычислительной мощности, решают кластеры распределения нагрузки. Такого рода кластеры позволяют распределять поступающие запросы между многими узлами сети. Помимо улучшения общей производительности системы здесь решается задача и повышения надежности, так как выход из строя отдельного узла кластера не приводит к нарушению работоспособности всей кластерной сети.
Как видим, кластерные системы разных видов обеспечивают как повышение производительности, так и надежности вычислений. Эти качества востребованы при создании технической инфраструктуры электронной информационно-образовательной среды, предполагающей наличие центрального ресурса, обеспечивающего деятельность большого числа людей. Такими ресурсами могут выступать сервисы образовательной организации, предназначенные для коллективной работы с образовательными материалами, тестирования знаний, учёта образовательных результатов, планирования занятий и др. Перспективным направлением таких сервисов является создание системы виртуального окружения обучающихся, когда рабочая среда выполнена в виде виртуальной машины и следует за пользователем в компьютерной сети [3, 4].
В целях разработки и апробации кластерной платформы такой системы на факультете математики, информатики и физики Волгоградского государственного социально-педагогического университета нами был проведен эксперимент по созданию учебного кластера для облачной платформы виртуальных машин. Данный кластер относится к разряду отказоустойчивых. Модель частного облака, реализованная на основе кластера, позволяет обеспечить одновременную работу большого числа виртуальных машин, гибко планировать загрузку оборудования в зависимости от потребностей их использования, гарантировать высокую доступность сервиса, его устойчивость к аппаратным проблемам.
В качестве основы экспериментального кластера были выбраны две одинаковые машины с процессором Intel Core i3 и оперативной памятью в 4 Гб. Данные машины были соединены в единую сеть пропускной способностью в 1 Гб/с, а также обеспечены дополнительными адаптерами для подключения к внешней сети (локальная сеть факультета, а также доступ к сети Интернет).
Следующим этапом стал выбор программного обеспечения для создания кластера. Одним из условий выбора такого ПО было его свободное распространение, что сузило круг возможных операционных систем преимущественно различными дистрибутивами Linux. Проведенный анализ показал, что могут использоваться не все такие дистрибутивы (даже серверные версии известных систем). Выбор был остановлен на CentOS 7, дистрибутив которого имел в своем составе необходимые пакеты, совместимые с другим программным обеспечением, использовавшимся при построении кластера [8].
После установки ОС потребовалось подготовить общий диск для хранения образов виртуальных машин. Для создания такого диска использовался LVM (Logical Volume Manager), который добавляет уровень абстракции между физическими дисками и файловой системой. Это в итоге позволяет создать файловую систему, где можно добавлять или удалять физические диски, не меняя логических разделов. Раздела размером 80 Гб оказалось достаточно для запуска на кластере 4–5 виртуальных машин. Созданные тома размером 80 Гб использовались для создания общего логического диска кластера.
Следующий шаг – это репликация томов с помощью DRBD (Distributed Replicated Block Device). DRBD – это блочное устройство, предназначенное для построения отказоустойчивых кластерных систем на операционной системе Linux. DRBD занимается полным отражением (mirroring) по сети всех операций с блочным устройством, что можно считать сетевой реализацией RAID-1 [7]. Драйвер DRBD, однако, может реплицировать каждый диск только между двумя узлами, а это означает, что при подключении нового узла необходимо выстраивать лестничное или древовидное реплицирование.
При использовании DRBD возникает необходимость в использовании специальных файловых систем, поддерживающих распределенную блокировку – DLM (Distributed Lock Manager). DLM позволяет специализированным приложениям и утилитам, таким как вышеупомянутый драйвер DRBD, синхронизировать доступ к ресурсам. На данный момент наиболее известные файловые системы, поддерживающие распределенную блокировку – OCFS2 и GFS2. Выбор был сделан в пользу второй, так как она показала хорошую совместимость с CentOS.
Для управления распределением ресурсов кластера использовался Pacemaker – набор утилит от ClusterLabs, который позволяет гибко распределять ресурсы по узлам кластера, следить за их доступностью, запускать отказавшие ресурсы и др. Pacemaker, таким образом, представляет собой центр управления кластером, который отслеживает и реагирует на происходящие события (присоединение и выход узлов из состава кластера, отказ ресурсов и др.). Pacemaker старается поддерживать идеальное состояние кластера и шаг за шагом выполнять действия для его достижения, такие как перемещение ресурсов, остановку и завершение работы узлов. Также он в случае отказа может посылать удалённым узлам сигналы завершения работы, пытаясь максимально обезопасить и продолжить работу остального кластера.
Неотъемлемой частью Pacemaker является демон, осуществляющий мониторинг доступности узлов в кластере. Для выполнения работы был выбран Corosync. Он обеспечивает основные функции, требующиеся для любой HA-системы, например запуск и остановку сервисов, мониторинг доступности узлов в кластере и передачу прав владения общим IP-адресом между узлами кластера, следит за состоянием конкретного сервиса (или сервисов) по интерфейсу Ethernet [6].
Помимо стандартных операций (start, stop, monitor), Pacemaker может выполнять и другие операции, значительно расширяющие возможности кластера. Это:
1. Миграция, которая позволяет осуществлять перенос ресурса с одного узла на другой. Такая миграция может осуществляться в процессе работы виртуальной машины без обрыва сетевых соединений. Время осуществления миграции составляет приблизительно 0,05 секунды, что совершенно незаметно для пользователя. Учитывая данное качество, такую миграцию называют «живой».
2. Клонирование, обеспечивающее возможность запуска одного ресурса на множестве узлов. Механизм клонирования предполагает, что на каком-либо из узлов, где запущен исходный ресурс, запускается и ресурс-клонировщик, который осуществляет запуск исходного ресурса на другом узле.
3. Отслеживание порядка запуска – построение списка ресурсов, которые должны запускаться и останавливаться в определенном порядке, а также исполняться на одном узле.
Еще один инструмент кластера может быть реализован на основе технологии STONITH. Эта технология позволяет кластеру физически выключать, включать и перезагружать узлы, когда это необходимо (например, при некорректном поведении узла). Технология предполагает, что менеджер кластера регулярно проверяет доступность и целостность узлов. Если по каким-либо причинам узел ведет себя неправильно (не отвечает по сети, не реагирует на запросы или др.), то Pacemaker посылает сигнал на STONITH устройство, тем самым физически устраняя неисправный узел. Это важно, в том числе, для обеспечения целостности системы, т.к. узел при потере соединения с другими начинает вести себя так, будто бы он остался последним узлом в кластере (такое состояние кластера получило название Split-Brain). Соответственно при его работе происходят изменения на жестком диске, изменения в конфигурации системы и др., что зачастую крайне сложно устранить.
Последним этапом создания кластера является настройка гипервизора виртуальных машин. В качестве такого гипервизора был выбран KVM – бесплатная, качественная и стабильная разработка компании Red Hat. KVM обеспечивает виртуализацию для ядра Linux, которая поддерживает платформенно-зависимую виртуализацию на процессорах с аппаратными расширениями [2]. Определяющим фактором при выборе данного гипервизора стала способность живой миграции запущенных виртуальных машин.
Подключение к виртуальным машинам, размещённым на созданном кластере, осуществляется посредством протоколов RDP и VNC. Непосредственно в нашей работе мы использовали TightVNC Viewer (доступ из Windows) и Remmina (Linux). Отметим, что всё использованное нами ПО, включая клиенты удалённого доступа для Windows, является свободно распространяемым.
Схематично реализованная модель отказоустойчивого кластера облачной платформы виртуальных машин представлена на рисунке.
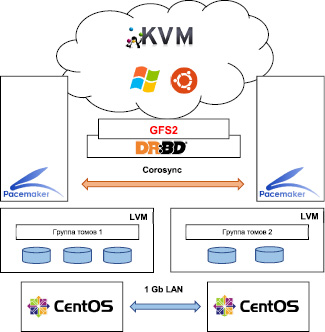
Модель отказоустойчивого кластера облачной платформы виртуальных машин
После установки и настройки всех компонентов кластера нами была проверена его работа в качестве сервера виртуальных машин. В ходе работы было опробовано несколько дистрибутивов разных операционных систем, среди которых были Ubuntu 14.04, Windows XP SP3, а также Windows 7 Professional. Всем представленным ОС было выделено 1 ядро процессора и 1 Гб оперативной памяти.
Нами были получены следующие результаты:
1. ОС Ubuntu установилась и работала в виртуальной среде без выявленных проблем. Драйверы устройств корректно определились в виртуальной среде.
2. С Windows XP возникли проблемы, связанные с невозможностью миграции на другой узел. После миграции система переставала отвечать на любые наши действия. Было решено, что данная ОС не может использоваться в качестве гостевой ОС.
3. Windows 7 работала и стабильно переносила живую миграцию.
Производительность всех этих систем была сравнима с производительностью на традиционной аппаратной платформе, хотя всё же является несколько более низкой.
Опыт, полученный в целом в процессе работы, позволяет утверждать, что выбранный подход к построению вычислительного центра электронной информационно-образовательной среды обладает несколькими важными преимуществами.
1. Отказоустойчивость. Система является работоспособной в случае аппаратных проблем, возникающих на отдельных узлах. Предоставление услуги не прерывается и в случае миграции виртуальных машин.
2. Масштабируемость. В кластер можно добавлять узлы, планируя ресурсы вычислительного центра в соответствии с имеющимися потребностями.
3. Безопасность. Простота тиражирования виртуальных машин в значительной степени исключает проблемы, связанные с учебной установкой программного обеспечения, некорректными действиями учащихся пользователей, заражением вирусами и др.
4. Доступность. Идея работы с виртуальными машинами из любой точки мира, где есть выход в сеть Интернет, стирает грани контактной и дистанционной работы обучающихся, позволяет активно внедрять дистанционные образовательные технологии в практику работы образовательной организации.
5. Экономия средств. Такая экономия достигается за счет возможности запуска на одном узле кластера нескольких виртуальных машин и работы с этими машинами в учебных классах на основе тонких клиентов.
Таким образом, кластерный подход позволил реализовать вычислительный центр для разработки образовательного сервиса в электронной информационно-образовательной среде. Тестовая апробация прототипа экспериментального кластера, параметры настройки программного обеспечения позволяют вести речь, что данный кластер способен обеспечить отказоустойчивую работу с предлагаемыми учебными ресурсами, требуемую производительность за счет распределения нагрузки, позволяет гибко планировать сетевую инфраструктуру в соответствии с увеличением или уменьшением нагрузки на вычислительный центр, экономить средства за счет использования свободного ПО, выполнения нескольких виртуальных машин на одном узле кластера, а также применения простого оборудования в учебных классах. Вместе с тем эксперимент показал, что тщательной проработки требуют вопросы планирования и синхронизации распределенной файловой системы. Необходима также установка и настройка специального оборудования для реализации всех возможностей менеджера кластера для проверки и обеспечения доступности и целостности узлов.
Статья подготовлена при поддержке Российского фонда фундаментальных исследований, проект № 16-47-340969 «Разработка концепции социальной образовательной сети малокомплектных сельских школ на основе кластерного подхода».
Библиографическая ссылка
Жданович Д.П., Сергеев А.Н. РЕАЛИЗАЦИЯ КЛАСТЕРНЫХ МОДЕЛЕЙ ВЫЧИСЛИТЕЛЬНОГО ЦЕНТРА ЭЛЕКТРОННОЙ ИНФОРМАЦИОННО-ОБРАЗОВАТЕЛЬНОЙ СРЕДЫ // Современные наукоемкие технологии. 2017. № 1. С. 36-40;URL: https://top-technologies.ru/ru/article/view?id=36552 (дата обращения: 03.07.2026).