



В настоящее время крупные компании вынуждены хранить очень большое количество информации. Помимо общей системы автоматизированного управления, которая действует на основе законодательных нормативно-правовых актов и в их пределах, в большинстве случаев также создается собственная автоматизированная система управления (АСУ), предназначенная для накопления, хранения, актуализации и обработки систематизированной информации в соответствующих предметных областях и предоставления требуемой информации по запросам пользователей, в том числе о заказчиках для формирования клиентской базы. АСУ характеризуются тем, что они оперируют фактическими сведениями, представленными в виде специальным образом организованных совокупностей формализованных записей данных. Эти записи образуют базу данных системы. Существует специальный класс программных средств для создания и обеспечения функционирования таких фактографических баз данных – системы управления базами данных [2].
Для этого используют кластеры серверов баз данных. Кластеры содержат тысячи серверов, которые могут быть в различных дата-центрах на разных континентах [1, 4].
Для того чтобы работать с таким кластером в команде разработчиков, необходимо автоматизировать его работу. Для этого разрабатывают автоматизированную систему управления кластером.
Технологии шардирования и репликации
Рассмотрим один сервер баз данных, который входит в большой кластер серверов. Каждый сервер в кластере содержит много экземпляров СУБД MySQL [4, 5]. Каждый экземпляр MySQL представляет из себя процесс на сервере, который слушает определенный порт. Каждый процесс – это полноценная СУБД со своим набором данных. Для увеличения производительности системы используют технологию шардирования [7]. Все данные разделяются на части, которые называются шардами. Большие базы данных разбиваются на тысячи шард.
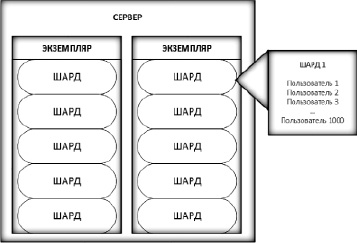
Рис. 1. Пример шардирования
К примеру, при существовании сущности пользователей в базе данных часть пользователей хранится на одной шарде, часть на второй и так далее (рис. 1). Разделение пользователей на шарды происходит с помощью распределения по уникальным идентификаторам пользователей.
Каждый экземпляр MySQL имеет несколько копий данных, которые располагаются на нескольких серверах, которые обычно находятся в разных дата-центрах [3]. Это необходимо для достижения следующих целей:
– высокая доступность;
– высокая производительность.
Для высокой доступности дополнительные копии данных используют при выходе из строя основного сервера. Копии всегда готовы принимать запросы. При расположении копий серверов на различных континентах есть возможность повысить производительность доступа к данным из любого места в мире. Это очень важно для международных сервисов. Этого возможно достичь с помощью репликации типа ведущий/ведомый.
Каждый экземпляр MySQL – это одна из множества реплик. Механизм репликации включает в себя ведущий сервер (мастер) и ведомые серверы (рис. 2).
Все записи происходят на ведущий сервер, а ведомые серверы подписываются на событие записи на ведущий сервер и, как только происходит запись на ведущий сервер, происходит считывание новых данных с ведущего на ведомые серверы. Это позволяет иметь несколько серверов, которые имеют идентичные данные. Следуя из этого, появляется возможность чтения с любого из серверов из множества реплик. Репликация позволяет увеличить производительность чтения данных из баз данных [3, 5, 6, 7].
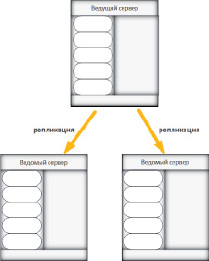
Рис. 2. Ведущий и ведомый серверы
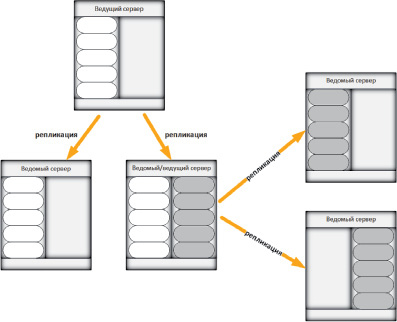
Рис. 3. Совмещение ведомого и ведущего сервера
В самом простом случае мы имеем по одному экземпляру MySQL на одном сервере. Однако в реальной жизни сервер обычно содержит несколько экземпляров MySQL, каждый из которых представляет собой реплику. При этом в одном сервере может содержаться как ведущая реплика, так и ведомая (рис. 3). В итоге получается большая сложная система, которую крайне сложно поддерживать. Как было сказано выше, для поддержки такой системы требуется написание программного модуля для ее управления.
Рассмотрим такую систему более подробно. Эта система умеет производить несколько важных операций [5, 6].
1. Создание копии сервера
Данная операция полностью копирует существующий сервер на другой. Также есть возможность замены сервера. Все данные копируются на новый сервер, а старый сервер освобождается. Сначала система создает новый экземпляр MySQL для выполнения операции. Далее происходит выбор существующей ведущей или ведомой реплики. Все данные из этой реплики переносятся на новый экземпляр MySQL, который был создан на предыдущем этапе. Дополнительно может производиться операция удаления старого сервера. Это называется операцией замены сервера. При выполнении операции замены в конце происходит удаление сервера из системы, с которого происходило копирование (рис. 4). Эта операция характеризуется тем, что она не предусматривает остановку работы и обработки запросов всего множества реплик, и система на протяжении всего времени исполнения этой операции остается работоспособной.
2. Создание новой ведущей реплики
Второй важной операцией является создание новой ведущей реплики из ведомой. Для произведения данной операции нужно выбрать целевую ведомую реплику. Приостановить запись на все ведущие реплики. Затем переключить ведомые реплики на репликацию с новой ведущей реплики. После этого перевести предыдущую ведущую реплику в режим ведомой либо удалить ее (рис. 5). Эта операция характеризуется остановкой записи на ведущий сервер на время выполнения операции.
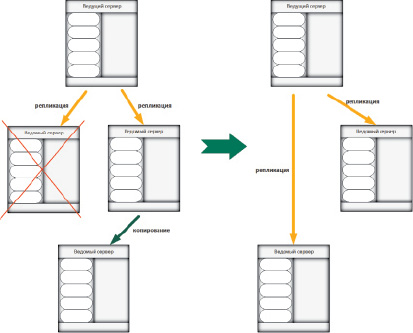
Рис. 4. Создание копии сервера
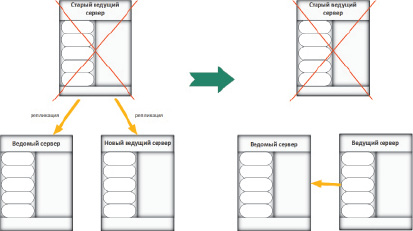
Рис. 5. Создание нового ведущего сервера
В системе управления кластером данные операции проводятся сотни раз в день в огромных кластерах баз данных. Причем все операции производятся в автоматизированном режиме без вмешательства системного администратора в этот процесс. Необходимо лишь изначально настроить конфигурацию системы для корректной работы.
Управление серверами и состояниями
Система управления кластером работает со специальным репозиторием, который хранит все текущие состояния и метаданные для всех экземпляров MySQL, а также все прошедшие и текущие операции копирования реплик и изменения состояния [4, 7]. Репозиторий с метаданными также внедрен в такую же систему масштабирования, поэтому он легко расширяется для поддержания высокой надежности и доступности в кластере. Система управления кластером не имеет каких-либо состояний и хранит лишь состояния других узлов системы.
Рассмотрим ситуацию, когда необходимо добавить новый сервер в систему. Это происходит в несколько шагов:
1. Сбор данных о новом сервере (где он находится, какие аппаратные средства имеет, под управлением какой операционной системы работает и какой версии MySQL).
2. Тестирование нового сервера на возможность корректной работы в системе (проверка жестких дисков, флэш-накопителей).
3. Запись в репозиторий метаданных о сервере.
4. Перевод всех экземпляров сервера в состояние «Начальное состояние».
5. Каждые несколько минут каждый сервер посылает в репозиторий данные о своей работе (регистрация работы).
Существует множество состояний для каждого экземпляра MySQL, среди которых:
1. Эксплуатация: экземпляр принимает трафик извне.
2. Вспомогательный: экземпляр готов к копированию для создания новых серверов для выполнения других задач.
3. Копирование вспомогательного: экземпляр выбран для операции копирования и копирование находится в прогрессе в данный момент.
4. Удаление вспомогательного: временное состояние, экземпляр ждет удаления. В этом состоянии сервер находится обычно не больше нескольких минут.
5. Системный: сервер не участвует в автоматической системе, предназначен для тестирования и наращивания мощностей при необходимости. Может быть переведен из этого состояния только с помощью системного администратора.
6. Начальное состояние: предназначено для только что добавленных серверов в систему.
Изменение состояний в системе возможно при проведении операций, которые были описаны выше. Также в репозитории хранится информация о задачах, которые выполняет конкретный экземпляр MySQL. Это позволяет сделать гибкую автоматизированную систему построения и управления архитектурой, которая рационально использует ресурсы системы, повышая производительность системы в целом и эффективно используя дисковое пространство. Операции копирования позволяют в автоматическом режиме определять заканчивающееся дисковое пространство на определенном сервере и производить перемещение данных на сервер с большим дисковым пространством.
Примеры разрешения часто встречающихся отказов серверов и архитектурных операций
В больших дата-центрах происходят десятки и сотни отказов серверов в день [3]. Есть несколько примеров аварийных ситуаций:
– отказ в работе ведомого сервера;
– отказ в работе ведущего сервера;
– остановка работы одного экземпляра MySQL.
Все нарушения в работе серверов необходимо контролировать в автоматическом режиме ввиду большого объема кластера. При отказе работы ведомого сервера происходит автоматическое выключение сервера из системы. При отказе ведущего сервера одна из его реплик становится ведущей, а отказавший сервер также отключается, как и в предыдущем случае. Аналогичные операции производятся и для отдельного экземпляра сервера БД. Затем система управления кластером пытается восстановить работу отказавших серверов. В случае неудачи информация об этих серверах поступает к системному администратору.
Заключение
Автоматизация управления кластером позволяет добиться намного лучшей производительности всей системы. Без нее работа с кластером, который насчитывает хотя бы сто серверов, практически невозможна. Для поддержания такой системы необходимо большое количество системных администраторов. Учитывая человеческий фактор, работа и поддержка такой системы могут быть нестабильными. Крупные компании самостоятельно реализуют такие системы и успешно эксплуатируют.
Библиографическая ссылка
Чистов В.А., Лукьянченко А.В. АВТОМАТИЗАЦИЯ МАСШТАБИРОВАНИЯ ВЫСОКОНАГРУЖЕННЫХ БАЗ ДАННЫХ MySQL // Современные наукоемкие технологии. 2016. № 6-2. С. 315-319;URL: https://top-technologies.ru/ru/article/view?id=36027 (дата обращения: 02.07.2026).