



Тестирование является общепринятой мерой обеспечения качества программного обеспечения, в то же время это очень трудоемкий процесс, который занимает около половины времени работы над проектом [5]. Большие временные затраты на проведение тестирования ведут к повышению стоимости разработки и сопровождения программного продукта и, как следствие, стоимости конечного продукта. Рассматриваемое в данной работе модульное тестирование является одной из затратных компонент тестирования в целом. Таким образом, снижение затрат на модульное тестирование положительно сказывается на процессе в целом. С другой стороны, недостаточное внимание к тестированию может привести к финансовым потерям. Так, согласно отчету Национального института стандартов и технологий США на 2002, неадекватная инфраструктура тестирования программного обеспечения обходилась бюджету в 60 млн долларов [8].
Уменьшению количества времени, затрачиваемого на тестирование, могут служить, автоматические генераторы тестов, однако они еще не нашли широкого применения в индустрии [3]. Другим подходом к сокращению сроков тестирования является применение языков описания тестов [1]. В данной работе описывается средство, которое совмещает оба подхода, пользуясь преимуществами генераторов для ускорения разработки тестовых наборов, а также языков описания тестов для увеличения контроля разработчика над процессом тестирования. Благодаря использованию автоматического генератора тестовых случаев появляется возможность покрытия кода по определенному критерию (например, покрытию инструкций). Таким образом увеличивается шанс найти ошибку, что является конечной целью данного процесса. Это важно вследствие того, что Си является небезопасным языком программирования, и связанный с ним процесс разработки подвержен ошибкам.
Цель исследования
Целью исследования является изучение преимуществ, получаемых при совмещении двух подходов к ускорению процесса модульного тестирования программного обеспечения – генерации входных тестовых данных, с одной стороны, и описания тестовых случаев в виде шаблонов – с другой.
Обзор литературы
История автоматической генерации тестов начинается в 1970-е годы. В эти годы для генерации тестовых случаев начинают применять символьные вычисления [6]. Программа выполняется символьно, то есть вместо конкретных значений переменным присваиваются символьные имена. Во время прохождения по различным путям накапливаются ограничения путей (path condition), включающие переменные, влияющие на поток управления (к которым относятся как формальные параметры процедур, так и глобальные переменные). После этого производится поиск решения для полученных ограничений. Если решение находится, то оно может быть использовано для генерации тестовых случаев на конкретных численных данных.
По техническим причинам первые генераторы тестов, разрабатываемые в 1970-е годы, имели поддержку исключительно целочисленных переменных и одномерных целочисленных массивов [6]. Это существенно снижало возможности применения таких систем при генерации тестов для реальных программ, используемых в индустрии. Выходом стало появление решателей для формул в рамках комбинации теорий (SMT-solver). Формулы выражаются в логике первого порядка, при этом определяются разрешающие процедуры для теорий, описывающих помимо прочего широко распространенные программные объекты, такие как: массивы, битовые векторы, индуктивные типы данных и так далее. Примером такой системы может служить CVC4 [2], используемая в данной работе, которая поддерживает стандарт SMT-LIB2 [7].
Таким образом, в современных генераторах для поиска решений ограничений путей используются внешние SMT-решатели. Среди прочих можно выделить систему KLEE [4], выпущенную в 2008 году, реализованную для промежуточного представления кода (IR-code) низкоуровневой виртуальной машины (LLVM) [9]. KLEE – это интерпретатор IR-кода, виртуальная машина, имеющая собственный стек, кучу и выполняющая символьные процессы (symbolic state). Целевым для системы KLEE является язык Си. Запуск тестов выполняется при помощи инструмента ktest-tool, являющегося частью KLEE, в то время как в предлагаемой авторами системе используется фреймворк CUnit. Необходимо отметить, что KLEE нацелена на полностью автоматизированное использование, что также отличает ее от предложенной системы.
Другим упомянутым способом ускорения процесса тестирования является использование языков описания тестов. Использование языков, описывающих тестовые наборы в виде шаблонов, избавляет разработчика от рутинного написания повторяющегося кода. Примером может служить система template-to-code (t2c), разработанная в ИСП РАН [1], язык которой основан на стандарте XML. Язык системы, предложенной в данной работе, не является реализацией XML, однако данная возможность принципиально реализуема.
Материалы и методы исследования
Перейдем к рассмотрению системы и описанию формата выходных файлов, порождаемых на каждом из этапов работы. Система выступает в качестве ассистента разработчика. Ключевой идеей является генерация входных тестовых данных в промежуточное представление, удобное для редактирования и сопровождения разработчиком и дальнейшей генерации тестовых случаев для конкретной библиотеки тестирования.
Архитектура системы
На рис. 1 схематически изображена модель системы, в которую включены файлы и программные средства. Файлы служат для представления данных, а программные средства для преобразования входных файлов в выходные. Рассмотрим каждый из компонентов в отдельности:
– Исходный код – подлежащий тестированию целевой программный код на языке Си;
– Скелетон – файл на внутреннем языке системы, содержащий описание тестовых случаев (см. Раздел 4.3 «Описание языка»);
– Тестовый набор – описание тестовых случаев на языке Си, при этом используется сторонняя библиотека (в данной работе это CUnit);
– Генератор тестовых случаев – на основе исходного кода порождает входные тестовые данные;
– Транслятор – преобразует скелетон в тестовый набор, то есть транслирует тестовые случаи с внутреннего языка описания тестов на язык Си;
– GCC – является сторонним пакетом, необходим для компиляции и компоновки исходного кода и тестового набора для возможности проведения тестирования.
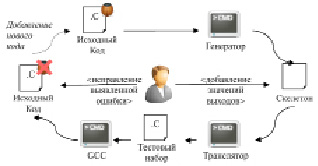
Рис. 1. Рабочий цикл работы с системой
Рассмотрим более детально процесс работы с данной системой. Цикл начинается с добавления разработчиком нового программного кода и завершается исправлением допущенных ошибок (если таковые имеются). Он состоит из последовательности следующих фаз:
1. Генератор на основе исходного кода создает тестовый скелетон.
2. Полученный скелетон редактируется разработчиком тестов, происходит добавление ожидаемых значений выходов к тестовым случаям.
3. Трансляция скелетона в тестовый набор на языке Си с подключением конкретной тестовой библиотеки CUnit.
4. Компиляция и компоновка тестового набора и исходного кода, запуск и анализ результатов, исправление выявленных ошибок разработчиком.
5. При внесении изменений в исходный код процесс повторяется с начала, с шага 1.
Генератор
Генератор порождает входные тестовые данные без добавления соответствующих им выходных данных. Напомним, что входными данными генератора является исходный код, а выходными – тестовый скелетон (см. Раздел 4.3 «Описание языка»). Данный генератор может быть отнесен к классу систематических генераторов по исходному коду [3]. При этом используются символьные вычисления. Генератор просматривает условные операторы if-else и получает решения для двух альтернатив. Первой альтернативой является та ветвь графа потока, которая соответствует прохождению по ветке «true» данного условного оператора. Второй альтернативой является ветвь «false» соответствующего условного оператора. В заголовке стоит некоторое условие (предикат P). Для первой альтернативы данное условие должно быть истинно (что соответствует P), для второй альтернативы оно должно быть ложно (что соответствует ¬P). В процессе работы генератор формирует соответствующее условие P и при помощи внешнего решателя (SMT-solver) находит два решения, при которых истинно либо P, либо ¬P соответственно. Последним шагом работы генератора является порождение соответствующих тестовых случаев.
Описание языка
Язык системы (dtl – declarative testing language) позволяет описывать тестовые наборы в абстрактной форме (тестовые скелетоны). Ниже приведен формат файла в общем виде (рис. 2, а), а также на конкретном примере функции возведения в степень (рис. 2, б).

Рис. 2. a) общий вид тестового скелетона; б) пример тестового скелетона для функции вычисления квадрата числа
Тестовый набор в общем виде представлен для функции, имеющей n входов (формальных параметров функции) и один выход (возвращаемое значение) с описанием m тестовых случаев. Следует обратить внимание на специальные символы «_» и «?», которые можно обнаружить в примере с функцией возведения в степень. Символ «_» может стоять на месте любого из формальных параметров и обозначает произвольное значение. Он используется, если данный параметр не влияет на поток управления. При генерации файла на целевом языке Си для него берется значение по умолчанию (ноль для целых чисел). Символ «?» означает то, что значение выхода не определено. Как было упомянуто ранее, генератор обеспечивает создание только входных данных тестов. В сгенерированном файле для каждого тестового случая, для которого разработчиком не указано конкретное значение выхода, указывается «?», и на фазе трансляции данный тестовый случай пропускается.
Транслятор
Трансляция тестового скелетона в тестовый набор на языке Си является завершающей фазой работы системы (если не учитывать работу сторонних инструментов). После анализа тестового скелетона транслятор инициализирует список тестируемых функций для построения таблицы символов. Далее, для каждой функции порождаются утверждения [assertion], которые компонуются в тестовые случаи. На следующем шаге происходит формирование из тестовых случаев тестового набора. На финальной стадии инициализируется функция «main», в которой прописывается логика инициализации и запуска тестов. Полученный файл затем компилируется и компонуется с тестовым фреймворком CUnit и исходным кодом.
Результаты исследования и их обсуждение
Пример работы
Рассмотрим действие предложенной системы на примере прототипа. Разработанный прототип реализует ключевые возможности, заложенные в представленную модель, однако имеет ряд ограничений, над устранением которых в настоящее время ведется работа. Ключевым ограничением разработанного прототипа является поддержка исключительно целочисленного типа данных. В то же самое время обеспечивается поддержка арифметических и логических операторов, операторов сравнения. Транслятором реализуется имеющаяся в языке возможность описания произвольного числа функций и тестовых случаев. В примере ниже рассмотрен цикл работы с функцией проверки на четность неотрицательного целого числа.
По целевой функции на языке Си (рис. 3, а) генерируется каркас тестирования на языке системы (рис. 3, б), затем разработчик заполняет значения входов (рис. 3, в), после чего каркас транслируется в целевой файл на языке Си, изображенный на рис. 4.
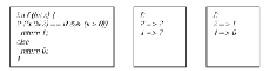
Рис. 3. a) целевой файл; б) сгенерированный тестовый скелетон; в) тестовый скелетон; дополненный разработчиком

Рис. 4. Итоговый выходной файл на языке Си для библиотеки CUnit
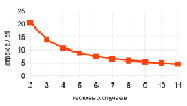
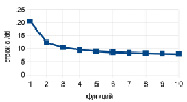
Рис. 5. a) соотношение c/dtl при изменении количества тестовых случаев; б) соотношение c/dtl при изменении числа функций
Экспериментальные исследования
На прототипе были произведены экспериментальные исследования, которые продемонстрировали уменьшение количества строк в файлах, содержащих тестовый набор, за счет использования предложенного авторами гибридного подхода. Это, в свою очередь, сокращает время разработки и сопровождения тестов.
На рис. 5, а показано соотношение строк в тестовом файле на языке Си к файлу на предложенном языке системы. При проведении эксперимента количество функций не менялось, а число тестовых случаев варьировалось в диапазоне от 1 до 10. Далее был проведен эксперимент на тестовых наборах с количеством функций от 1 до 10 соответственно, но с неизменным числом тестовых случаев. Полученное соотношение продемонстрировано на рис. 5, б.
Представленные графики демонстрируют, что при увеличении количества тестовых случаев и функций соотношение строк c / dtl сокращается, но остается довольно высоким, – объем файла на языке Си превышает объем файла на языке системы в несколько раз.
Заключение
Проведенное исследование показало перспективность частично автоматизированной гибридной системы тестирования программ. Генератор обеспечивает покрытие кода тестами по строгому критерию покрытия инструкций. При этом остается возможность написания дополнительных тестов на языке системы, что сокращает время их создания по сравнению с языком Си (однако некоторые тесты не могут быть описаны таким способом). Размер файлов с тестовыми наборами сокращается, их удобнее создавать, инспектировать и сопровождать за счет компактного формата описания тестовых случаев. Как следствие, время разработки программы в целом также сокращается. Несмотря на некоторые ограничения, накладываемые на прототип, экспериментально были продемонстрированы преимущества ее использования (по сравнению с тестированием вручную) при разработке программ на языке Си в лабораторных условиях. В данный момент ведется дальнейшая работа над проектом с целью приближения перспективы промышленного применения предложенной системы.
Библиографическая ссылка
Якимов И.А., Кузнецов А.С. ГИБРИДНЫЙ ПОДХОД К АВТОМАТИЗАЦИИ МОДУЛЬНОГО ТЕСТИРОВАНИЯ ПРОГРАММ НА ЯЗЫКЕ СИ // Современные наукоемкие технологии. 2016. № 2-1. С. 50-54;URL: https://top-technologies.ru/ru/article/view?id=35570 (дата обращения: 01.08.2026).