



В настоящие время в интернете появляется все больше форумов, социальных сетей и блогов. В них люди общаются, решают различные проблемы. Эти данные могут содержать информацию, которая неприемлема для детей и подростков или была бы интересна спецслужбам.
В этой связи активно развиваются технологии модерации пользовательских постов. В том числе поиск таких нарушений как, распространение спама, флуда, размещение постов и комментариев не по теме, но существуют и более серьезные нарушения, например, такие как разжигание межнациональной розни, обсуждение и организация антиобщественных мероприятий, пропаганда насилия и т.д. В связи с неуклонным ростом размещаемой пользователями информации выполнять модерацию в основном человеческими силами становится все труднее. Для решения этой проблемы существует ряд разработок как зарубежных, так и отечественных [1-3].
В рамках магистерской диссертации «Разработка мультиагентной системы (МАС) для сбора текстовой информации в социальной сети» [4] автором ведется работа по проектированию и реализации МАС, с учетом многоядерной архитектуры компьютера и использования КЭШ памяти. Мультиагентная система анализирует объем КЭШ памяти и подстраиваться под возможности компьютера, а если система имеет несколько ядер, то разные агенты смогут работать на раздельных ядрах. Это совершенно новый подход в разработки системы, который ранее не применялся.
Наиболее распространенное определение МАС – это система, образованная несколькими взаимодействующими интеллектуальными агентами. Мультиагентные системы могут быть использованы для решения таких проблем, которые сложно или невозможно решить с помощью одного агента [5]. При этом важно, что интеллектуальный агент – программа, самостоятельно выполняющая задание, в течение длительных промежутков времени и взаимодействующая с другими агентами.
Применение агентного подхода значительно упрощает разработку программного обеспечения (ПО), поскольку новые агенты могут использовать в своей работе других агентов, путем наследования их функций и свойств или же просто посылая им свои запросы, а также упрощается процесс размещения ПО в условиях сети. Происходит это за счет автоматизации процессов перемещения программного кода, его установки и конфигурирования[6].
Разработанная автором модель МАС включает следующие компоненты.
Агенты: агент-собиратель, агент-исследователь, агент-диагностик, агент-очиститель; базы данных: временная БД, база знаний (БЗ), БД «грязных» страниц, на которых найдены слова или выражения из базы знаний.
Одним из главных агентов является поисковый робот, или агент-собиратель. Он посещает социальные сети, форумы и блоги, и найденные ссылки сохраняет во временную базу данных.
Временная база данных – это база, в которой хранятся ссылки собранные из интернета и подлежащие дальнейшей обработки другими агентами.
Оптимизация работы агента-собирателя и его взаимодействия с временной базой данных, использует многоядерность компьютера и КЭШ память. В статье на примере тестов показаны, особенности и »тонкие моменты», которые необходимо учитывать при разработке приложений, обрабатывающих большие объемы данных.
Для обеспечения терминологической однозначности ниже приведен ряд определений.
Кэш память – это сверхбыстрая память, являющейся буфером между контроллером системной памяти и процессором. В этом буфере сохраняются блоки данных, с которыми процессор работает в данный момент, тем самым значительно уменьшается количество обращений процессора к медленной системной памяти и увеличивая общую производительность процессора.
Контроллер памяти – цифровая схема, управляющая потоком данных к и от оперативной памяти.
Операти́вная па́мять – энергозависимая часть системы компьютерной памяти, в которой временно хранятся данные и команды, необходимые процессору для выполнения им операции. По быстродействию оперативная память находится на втором месте после КЭШ памяти.
Простейшая схема взаимодействия процессора с КЭШ памятью и оперативной памятью представлена на рисунке 1.
Кэш память бывает первого, второго и третьего уровней. В мультиагентной системе используется только второй уровень. В КЭШ память второго уровня изначально передаются все данные, для обработки центральным процессором. На втором уровне из данных строятся цепочка инструкций, а на первом уровне «зеркально» строятся внутренние команды процессора, которые учитывают особенности процессора, регистры. В отличии от КЭШ памяти первого уровня, КЭШ память второго уровня для процессора имеет огромное значение, именно поэтому процессоры с наибольшим объемом КЭШа второго уровня показывают высокую производительность.
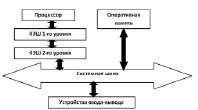
Рис. 1. Схема взаимодействия процессора с энергозависимой памятью
Все данные загружаются в КЭШ второго уровня, именно поэтому мультиагентная система напрямую работает с ней. На рисунке 2 показано, как процессор обращается сначала к КЭШ памяти первого уровня, а затем к КЭШ памяти второго уровня, и если данные не найдены, то к оперативной памяти.
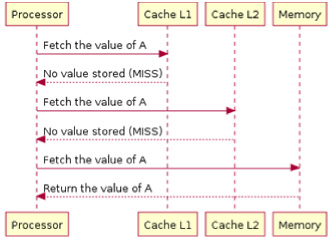
Рис. 2. Обращение процессора к КЭШ памяти
Впервые КЭШ память второго уровня появилась на процессорах i80486 и была равна 512 килобайт. На более современных компьютера размер КЭШа больше, но даже при размере в 512 Кбайт процессор сможет обработать достаточно много информации.
Ниже приведены тесты на компьютере, который имеет 3 ядра и каждое ядро имеет 512 килобайт КЭШ памяти второго уровня.
Размер одного текстового символа равен 1 байт, 512 килобайт это 524288 байта. В рамках разработки мультиагентной системы было проведено исследование среднего размера ссылки в интернете, и выявлено, что средний размер равен 55 символов. Из вышеизложенного следует, что для загрузки целой таблицы в КЭШ память ее размер не должен превышать 9000 записей, но для поднятия быстродействия разрабатываемой системы агент-собиратель будет обрабатывать несколько таблиц одновременно в разных потоках, поэтому размер таблицы будет ограничен 1000 записями.
Рассмотрим тесты, которые показывают, что если в 100 таблиц по 1000 записей вносить изменения в несколько потоков, то это окажется намного быстрее, чем работа с одной таблицей на 100000 записей.
На рис. 3 показана схема теста, в котором, агент, используя один поток, взаимодействует с базой данных, содержащей одну таблицу на 100000 записей. Агент производит запись 100000 строк по 55 символ, так как средний размер ссылки равен этому значению.
После работы агента появляется сообщение о количестве секунд затраченных на запись (рис. 4). На рис. 5 показана степень загруженности процессора (в %).
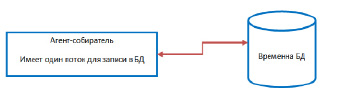
Рис. 3. Взаимодействие агента-собирателя с временной БД
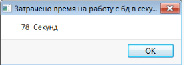
Рис. 4. Затраченное время на запись

Рис. 5 Загрузка процессора
Следующий тест покажет, что если в БД создано 100 таблиц по 1000 записей, то это намного эффективнее работает, так как есть возможность запустить несколько потоков. На рис. 6 показана схема взаимодействия агента-собирателя с временной БД.
Агент имеет 6 поток для взаимодействия с БД. Каждый поток работает только со своей таблицей. Запускается 6 поток, так как это оптимально для данного компьютера. Результаты работы представлены на рис. 7 и 8.
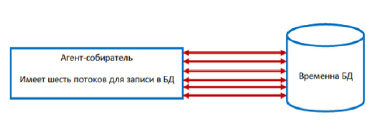
Рис.6. Взаимодействие агента-собирателя с временной БД
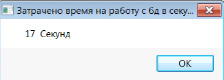
Рис. 7 Время, затраченное на запись

Рис. 8. Загрузка процессора
Из рис. 4 и 7 сразу видна разница в скорости выполнения записи, в 4.5 раза быстрее происходит запись в »малые» таблицы, чем в одну большую. Если посмотреть на рисунок 5, то у второго ядра загрузка, в среднем, составляет 45 процентов, это немного для данного компьютера. Однако, если сравнить данные на рис.8, то у всех 3 ядер, во время записи в таблицы, загрузка 90 процентов, что говорит об оптимальном выборе количества потоков и размере таблиц для данного компьютера.
В разрабатываемой мультиагентной системе во временной базе данных будет создано много таблиц по 1000 записей, для того, чтобы разные потоки могли работать с разными таблицами, тем самым ускоряя работу системы.
Выводы
При разработке приложения, обрабатывающего большие объемы данных, необходимо учитывать составляющие компьютера, в частности КЭШ память и количество ядер. Учитывая данные параметры, можно оптимизировать работу программы в 4-5 раз, что даст возможность обработать больше информации за меньший промежуток времени.
Библиографическая ссылка
Пестряев А.А., Воронова Л.И. МУЛЬТИАГЕНТНАЯ СИСТЕМА. ВЗАИМОДЕЙСТВИЕ АГЕНТА-СОБИРАТЕЛЯ С БАЗОЙ ДАННЫХ // Современные наукоемкие технологии. 2014. № 5-2. С. 214-217;URL: https://top-technologies.ru/ru/article/view?id=34080 (дата обращения: 30.06.2026).