



Информационно-терминологический базис (ИТБ) на котором основана ЛСК-методика представляет собой совокупность лексически связанных компонентов (ЛС-компонентов), структура которых описывается как:
ЛС-компонент = {МЛ-компонент (основная лексема), МЛ-компонент (связанная лексема №1), МЛ-компонент (связанная лексема №2),...} [2]
МЛ-компонент (основная лексема) = {термин яз_1, термин яз_2,..., термин яз_N, частота яз_1, частота яз_2,..., частота яз_N, сочетание 1_яз_1, сочетание 1_яз_2,..., сочетание 2_яз_1, сочетание 2_яз_2,..., сочетание K_яз_N, частота 1_яз_1, частота 1_яз_2,..., частота 2_яз_1, частота 2_яз_2,..., частота K_яз_N}.
Лексему, связанную со всеми без исключения лексемами ЛС-компонента ИТБ принято называть основной лексемой, лексемы же, имеющие только одну связь - связанными лексемами.
Построение ИТБ для ЛСК-методики - задача неоднозначная и многоатрибутивная. Здесь необходимо учитывать требования, которые предъявляются специалистами от лингвистики к структуре ИТБ, количеству ЛС-компонентов, качеству и скорости построения ИТБ.
На сегодняшний момент существует два вида алгоритмов формирования ЛС-компонентов: нисходящие алгоритмы (Н-алгоритмы) и восходящие алгоритмы (В-алгоритмы). Их принципиальное отличие состоит в способе включения в ЛС-компонент связанных лексем.
Оба алгоритма состоят из 3 общих фаз:
- ИТБ упорядочивается по убыванию, согласно критерия:
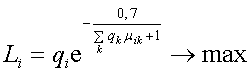 (1)
(1)
где qi - относительная частота, выражающая долю лексической единицы в тексте, подвергшемуся статистической обработке при составлении частотного словаря, 0<qi <1,
μik - относительная частота сочетания i-ой и k-ой лексем, отражает силу ассоциативной связи.
2. Определение оптимального числа основных лексем kmax.
2.1.Перебор числа основных лексем n.
2.2. Поиск связанных лексем.
2.3 Вычисление функции качества ИТБ как совокупности ЛС-компонентов от числа основных лексем:
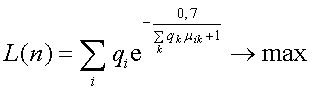 (2)
(2)
Определение оптимального количества основных лексем и структуры ЛС-компонентов путем максимизации функции качества L(n).
3. Формирование ИТБ для kmax (п. 2.2).
Рассматриваемые алгоритмы имеют различия в п. 2.2, в случае Н-алгоритма поиск связанных лексем осуществляется непосредственно при переборе основных лексем с учетом данных о их лексических связях; в случае В-алгоритма - поиск осуществляется путем перебора связанных лексем j и нахождения наилучших сочетаний:
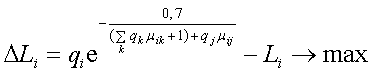 (3)
(3)
Тесты показывают, что при увеличении объема ИТБ в n раз, время исполнения алгоритмов возрастает в геометрической прогрессии, причем для В-алгоритма это время возрастает в n раз быстрее [3]. Несмотря на большую разницу по времени исполнения, В-алгоритмы формируют более качественную структуру ИТБ; операция формирования ИТБ производится только один раз, и показатель качества много важнее.
Недостатком В-алгоритмов так же является то, что заранее невозможно предугадать сколько именно основных лексем будет в ИТБ. В случае, когда разработчик выставляет жесткие требования к количеству основных лексем (ЛС-компонентов) или когда важно время исполнения (очень большие объемы ИТБ), следует использовать Н-алгоритмы формирования ЛС-компонентов, в противном случае, предпочтение следует отдавать В-алгоритмам.
СПИСОК ЛИТЕРАТУРЫ:
- Карасева М.В., Лесков В.О. Системные аспекты методики обучения иностранной лексике, посредством построения внутриязыковых ассоциативных полей // Вестник Университетского Комплекса, 9(23), 2007. - С. 110 - 119
- Ковалев И.В., Ступина А.А., Суздалева Е.А. Информационно-алгоритмическое обеспечение мультилингвистической технологии обучения //Современное образование: массовость и качество: Материалы региональной научно-методической конференции. ‑ Томск, 2001 ‑ с.98-99.
- Лесков В.О. Комплекс программного моделирования КПМ v.1.0 -М.:ВНТИЦ, 2008 - №50200802242.
Библиографическая ссылка
Лесков В.О. ДВА ПОДХОДА К ФОРМИРОВАНИЮ ЛЕКСИЧЕСКИ СВЯЗАННЫХ КОМПОНЕНТОВ // Современные наукоемкие технологии. 2008. № 12. С. 29-30;URL: https://top-technologies.ru/ru/article/view?id=24335 (дата обращения: 01.07.2026).