



Следует отметить, что пока отсутствуют и эффективные алгоритмы анализа полутоновых изображений (ПТИ), методы четкого выделения признаков, без которых никакие усложнения решающих правил не дадут требуемого эффекта. При этом наиболее информативным элементом ПТИ является его контурное представление.
Важнейшей особенностью задач распознавания является то, что наблюдения X I,J неизбежно подвержены случайным возмущениям, непредсказуемый вероятностный характер которых сказывается на всех стадиях, начиная от процесса получения самих измерений и кончая вычислением значений функции ![]() . Взаимодействуя между собой, указанные возмущения приводят к тому, что наблюдения X I,J неизбежно оказываются реализациями случайных величин, функция
. Взаимодействуя между собой, указанные возмущения приводят к тому, что наблюдения X I,J неизбежно оказываются реализациями случайных величин, функция ![]() становится случайной величиной. Отсюда видно, что разработка теории распознавания неизбежно связана с исследованием случайных отображений, что оказывается возможным только на основе статистических методов.
становится случайной величиной. Отсюда видно, что разработка теории распознавания неизбежно связана с исследованием случайных отображений, что оказывается возможным только на основе статистических методов.
Классификация включает все процессы, заканчивающиеся указанием некоторого класса (или принадлежности классу) для рассматриваемого объекта или данных. Результат распознавания тоже можно представить как подобное указание класса - в таком смысле распознавание образов является одной из разновидностей классификации. В тех случаях, когда каждый класс содержит только один объект, классификация эквивалентна идентификации. Специфика конкретных задач распознавания связана с числом m распознаваемых образов, а также с характером сведений о частотах w и вероятностях P (u) получения измерения от j-го образа. В практической деятельности обычно точно неизвестна та или иная функция распределения и можно лишь априорно указать параметрический класс, к которому принадлежит распределение. Поэтому обучающая выборка при распознавании образов получила очень широкое применение. Наибольшее влияние на способ распознавания оказывают вид распределения P (u) и точность исходных данных о них. При этом рассматриваются три ситуации: полностью описанные классы; использование обучающих выборок; отсутствие априорных сведений о P (u) [2,3].
Классификация в случае, когда распределения P(u) классов определены полностью базируется на лемме Неймана-Пирсона, байесовских решениях, минимаксных решениях, методах максимального правдоподобия. Лемма Неймана-Пирсона указывает, что в достаточно широком классе ситуаций среди всех возможных критериев с ошибкой первого рода a, наиболее мощным, т.е. имеющим наименьшую ошибку второго рода b, является критерий отношения правдоподобия, основанный на статистике
![]() (1)
(1)
где L - функционал правдоподобия.
При этом при ![]() принимается гипотеза H1, а при
принимается гипотеза H1, а при ![]() принимается гипотеза H2. Таким образом R - пространство возможных значений X с помощью (1) разбивается на две непересекающиеся области [3]:
принимается гипотеза H2. Таким образом R - пространство возможных значений X с помощью (1) разбивается на две непересекающиеся области [3]:
![]() - область принятия гипотезы H1;
- область принятия гипотезы H1;
![]() - область принятия гипотезы H2.
- область принятия гипотезы H2.
В общем случае отыскание минимаксного решения - довольно трудная задача. Однако облегчает положение результат Вальде, устанавливающий соответствие между минимаксным и байесовским решениями [4]. Наряду с критерием отношения правдоподобия на практике широко используются правила классификации, критические области которых находятся путем минимизации функции потерь при данных ограничениях на границе критической области.
Анализ байесовской системы обработки сигналов сводится к вычислению минимального значения среднего риска, т.е. байесовского риска, который является мерой качества работы оптимальной системы. Минимаксные решения и риски определяют синтез и анализ систем обработки сигналов, оптимальных по минимаксному решению с использованием критерия Байеса, Неймана-Пирсона, Вальда. Вычисления с помощью метода максимального правдоподобия довольно дорогостоящи, поэтому предприняты попытки его реализации на аналоговых ЭВМ. К достоинствам метода следует отнести невысокие требования к памяти ЭВМ. Для каждого класса требуется хранить вектор средних значений и верхнюю треугольную часть обратной матрицы.
Во втором случае распределения P(u) неизвестны, но о них в той или иной степени можно судить по обучающим выборкам, каждая из которых является совокупностью измерений, выполненных для известного объекта. Теоретические результаты классификации при наличии обучающих выборок базируются на основе дискриминантного анализа (ДА).
В третьем случае отсутствует и обучающая выборка.
Первая мера быстрее в реализации, вторая более точная. Как правило, кластерные алгоритмы требуют больших затрат машинного времени. Общее время T0, необходимое для выполнения кластерного анализа составит:
![]() (2)
(2)
где n - число кластеров;
N - число точек;
a - время, затрачиваемое на выполнение операции сложения для сравнения;
M - время, затрачиваемое на умножение.
Из (2) видно, что затраты времени быстро возрастают с увеличением объемов классифицируемой выборки.
Для определения сравнительного качества различных способов разбиения заданной совокупности элементов на классы вводится так называемый функционал качества разбиения Q(S), определяемый на множестве всех возможных разбиений. Функционалом он называется потому, что чаще всего разбиение S задается набором дискриминантных функций ![]() Тогда под наилучшим разбиением S* понимается то разбиение, на котором достигается экстремум выбранного функционала качества. Выбор того или иного функционала качества, как правило, осуществляется весьма произвольно и опирается скорее на эмпирические и профессионально-интуитивные соображения, чем на какую-либо строгую формализованную систему. При этом рассматриваются два случая определения функционала качества:
Тогда под наилучшим разбиением S* понимается то разбиение, на котором достигается экстремум выбранного функционала качества. Выбор того или иного функционала качества, как правило, осуществляется весьма произвольно и опирается скорее на эмпирические и профессионально-интуитивные соображения, чем на какую-либо строгую формализованную систему. При этом рассматриваются два случая определения функционала качества:
функционал качества разбиения при заданном числе классов;
функционал качества разбиения при неизвестном числе классов.
Пусть исследователем уже выбрана метрика d в пространстве Пр(X) и пусть 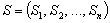 некоторое функциональное разбиение наблюдений
некоторое функциональное разбиение наблюдений ![]() на заданное число классов
на заданное число классов ![]() .
.
За функционал качества часто берутся следующие характеристики:
- сумма ("взвешенная") внутриклассовых дисперсий
![]() (3)
(3)
- весьма широко используемая в задачах кластер-анализа в качестве критериальной оценки разбиения;
- сумма попарных внутриклассовых расстояний между элементами
![]()
либо
![]()
где d - метрика в пространстве признаков, в большинстве ситуаций приводит к тем же наилучшим разбиениям, что и (3) и тоже используется для сравнения кластер-процедур.
Обобщенная внутриклассовая дисперсия Q3(S) является как известно, одной из характеристик степени рассеивания многомерных наблюдений одного класса (генеральной совокупности) около своего "центра тяжести". Следуя обычным правилам вычисления выборочной ковариационной матрицы W1, отделив по наблюдениям, попавшим в какой-то один класс s1, получим:
![]() (4)
(4)
где под det A понимается "определитель матрицы A", а элементы wqm(l) выборочной ковариационной матрицы W1 класса s1 подсчитываются по формуле
![]() (5)
(5)
q, m = 1, 2,..., p,
где ![]() - γ-я компонента многомерного наблюдения xi ;
- γ-я компонента многомерного наблюдения xi ; ![]() - среднее значение γ-й компоненты, подсчитанное по наблюдениям l -го класса.
- среднее значение γ-й компоненты, подсчитанное по наблюдениям l -го класса.
Встречается и другой вариант использования понятия обобщенной дисперсии как характеристики качества разбиения, в котором операция суммирования Wl по классам заменена операцией умножения:
![]() (6)
(6)
Как видно из формул (4) и (5) функционал Q3(S) является средней арифметической (по всем классам) характеристикой обобщенной внутриклассовой дисперсии, в то время как функционал (6) пропорционален средней геометрической характеристике тех же величин. Использование функционалов Q3(S) и Q4(S) является особенно уместным в тех ситуациях, при которых исследователь в первую очередь задается вопросом: не сосредоточены ли наблюдения, разбитые на классы S1,S2,...,Sl в пространстве размерностью, меньшей, чем P.
В ситуациях, когда исследователю заранее не известно, на какое число классов подразделяются исходные многомерные наблюдения X1,X2, ,,,, Xn, функционалы качества разбиения Q(S) выбирают чаще всего в виде простых алгебраических комбинаций (суммы, разности, произведения, отношения) двух функционалов l1(S) и l2(S), один из которых l1 является убывающей (невозрастающей) функцией числа классов k и характеризует, как правило, внутриклассовый разброс наблюдений, а второй l2 - возрастающей (неубывающей) функцией числа классов k. Под l2 понимается иногда и некоторая мера взаимного удаления (близости) классов, и мера тех потерь, которые приходится нести исследователю при излишней детализации рассматриваемого массива исходных наблюдений, и величина, обратная так называемой "мере концентрации" всей структуры точек, полученной при разбиении исследуемого множества наблюдений на k классов. Например, предлагается брать
![]() , (7)
, (7)
l2 = ck (S) (8)
где k(S) - число классов, получающихся при разбиении S; c - некоторая положительная постоянная, характеризующая потери исследователя при увеличении числа классов на единицу. Другой вариант функционала качества представляется в виде
![]() (9)
(9)
![]() (10)
(10)
Здесь k (XI, XJ) - потенциальная функция; r (SI, SJ) - мера близости i - го и j - го классов, основанная на потенциале функции.
Очевидно, в первом случае будем искать разбиения S*, минимизирующее значение функционала
![]() (11)
(11)
в то время как во втором случае требуется найти разбиение S*, которое максимизировало бы значение функционала
![]() (12)
(12)
Весьма гибким и достаточно общим подходом, реализующим идею одновременного учета двух функционалов (7) - (12), является подход, основанный на схеме, предложенной А.Н. Колмогоровым. Эта схема опирается на понятие меры концентрации точки, соответствующей разбиению Zτ (S), и средней мере внутриклассового рассеяния lτk (S), характеризующей то же разбиение S.
В том случае, когда точки пространства признаков образуют тесные и далеко расположенные друг от друга скопления, можно пользоваться цепным методом. Однако при достаточно близких друг к другу скоплениях с нечеткими границами такой метод дает неправильные результаты. Ряд итеративных процедур основан на локальной минимизации среднего расстояния от объекта до центра ближайшего к нему скопления. Наилучшим примером такой процедуры может служить адаптированный Боллом и Холлом алгоритм с поиском ближайшего среднего. Главное препятствием, возникающим при использовании процедур типа ближайшего среднего, состоит в определении "правильного" числа классов. С этой целью в работе предложено характеризовать качество автоматической классификации значением некоторого параметра β.
Известно несколько таких параметров. Один из них определяется как отношение меры разброса векторов из одинаковых классов, которые вычисляют по соответствующим матрицам разбросов. Этот параметр характеризует степень разделимости множества объектов. Матрица разбросов точек внутри классов определяется относительно средних значений по формуле
![]() (13)
(13)
где x - вектор признаков,
![]() (14)
(14)
где μ0 - среднее по всей совокупности спектров, вычисляемое по формуле
![]() (15)
(15)
где M - общее число классификации объектов (точечных элементов изображения).
Матрицы разбросов вычисляют с целью оценки разделимости множества объектов. Опираясь на них (13) - (15) определяют параметр β - критерий качества классификации. Среди известных критериев качества классификации заслуживают внимание следующие пять:
![]() (16)
(16)
![]() (17)
(17)
![]() (18)
(18)
![]() (19)
(19)
![]() (20)
(20)
где tr(•) - "след" матрицы, т.е. сумма ее диагональных элементов;
|•| - определитель матрицы.
При использовании параметра β3 (18) минимизируют след матрицы Sb при ограничении trSW=c. В выражении (18) через μ обозначен множитель Лагранжа, а c - постоянная величина.
Параметры β1 (16) и β2 (17) инвариантны по отношению к любому невырожденному линейному преобразованию координат. Параметры β3 (18) и β4 (19) легко вычисляются, но они зависят от выбора системы координат.
При оценке качества классификации при помощи параметра β необходимо по кривой зависимости β от числа классов найти излом. Когда исходные данные искажены шумом и кривая недостаточна гладка, найти излом не так просто. Лучше всего регистрировать изменениям параметра β5 (20), который принимает максимальное значение как раз при "правильном" числе классов. Если число классов равно 1, то ![]()
![]() и
и ![]() . Если же число классов равно общему числу M векторов, то
. Если же число классов равно общему числу M векторов, то 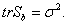
![]() =0, trSb =σ2 Отсюда β5 = 0.
=0, trSb =σ2 Отсюда β5 = 0.
Таким образом, параметр β5, принимает нулевое значение на обоих концах интервала изменения возможного числа классов. Поскольку величина β5 положительная внутри интервала, она принимает в нем по крайней мере одно, а возможно, и несколько максимальных значений. В идеальном случае параметр принимает одно максимальное значение. Соответствующая классификация будет "хорошей" с точки зрения человеческого восприятия [4,5,6].
Величины trSW и trSb, применяемые в оценке качества классификации, неявно задают на множестве размеров классов весовую функцию. Каждый элемент матрицы разброса векторов из одинаковых классов и матрица разброса векторов из разных классов представляют собой взвешенную сумму членов, где весовые коэффициенты равны относительной численности 1/Mk объектов каждого класса. При таком неявном взвешивании справедливо интересное соотношение:
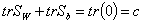 ,
,
где (0) - ковариационная матрица совокупности данных, а c - постоянная величина (сумма общих дисперсий).
Отсюда:
![]() .
.
Дифференцируя правую часть по и приравнивая производную нулю, получим:
![]() (21)
(21)
Таким образом, величина β5 достигает максимального значения при такой классификации, когда trSW (21) равен половине от tr(0).
Анализируя далее параметр , получим:
![]()
При trSW = c /2
![]() (22)
(22)
Таким образом, при максимуме параметра β5 отношение меры разброса векторов из разных кластеров к мере разброса векторов из одинаковых классов становится равна единице (22). Полученное соотношение (22) весьма полезно в задачах, где требуется проводить вычисления в реальном масштабе времени. Без него при поиске максимума параметра β5 требуется проводить дополнительную классификацию при большем на единицу числе классов, что бы убедиться, что параметр β5 начинает уменьшаться и найденное на предыдущем шаге значение действительно максимально.
При ограниченном количестве экспериментальных данных, а это часто встречается в практических задачах, наблюдаются не только неизбежные случайные погрешности величин ![]() но и систематические преувеличения
но и систематические преувеличения ![]() и преуменьшения
и преуменьшения ![]()
Эмпирическое корреляционное отношение систематически дает большую тесноту связи между y и x, причем тем большую, чем меньше количество наблюдений. Для устранения погрешностей вместо эмпирической линии регрессии при расчете показателей ![]() и
и ![]() вводят в рассмотрение теоретическую линию регрессии.
вводят в рассмотрение теоретическую линию регрессии.
Пусть - частная средняя, которая получена из уравнения для теоретической линии регрессии Заменив этой средней эмпирическую среднюю в выражениях для получим:
![]()
![]()
![]()
Воспользуемся уравнением:
![]()
Вместо показателя η можно теперь рассматривать показатель:
![]()
который называется теоретическим корреляционным отношением y по x. Очевидно, что:
![]()
При ![]() и теоретическая линия регрессии параллельна оси абсцисс. Для достаточно большого числа наблюдений это свидетельствует об отсутствии корреляции между y и x. Если
и теоретическая линия регрессии параллельна оси абсцисс. Для достаточно большого числа наблюдений это свидетельствует об отсутствии корреляции между y и x. Если ![]() , то
, то ![]() и все точки поля лежат на теоретической линии регрессии. При большом количестве наблюдений это может свидетельствовать о наличии функциональной зависимости между y и x. Дисперсия перераспределяется между двумя составляющими. В самом деле, исходя из минимального свойства средней арифметической, в каждом столбце корреляционной таблицы имеем:
и все точки поля лежат на теоретической линии регрессии. При большом количестве наблюдений это может свидетельствовать о наличии функциональной зависимости между y и x. Дисперсия перераспределяется между двумя составляющими. В самом деле, исходя из минимального свойства средней арифметической, в каждом столбце корреляционной таблицы имеем:
![]()
а значит, и ![]()
Следовательно, 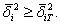
Таким образом, ![]()
т.е. теоретическое корреляционное отношение не больше эмпирического [1].
Теоретическое корреляционное отношение в определенной степени исправляет систематическую ошибку, свойственную эмпирическому корреляционному отношению. Однако полностью эту систематическую ошибку устранить нельзя. Дело в том, что теоретическая линия регрессии, по которой рассчитывались ![]() и
и ![]() , не является предельной теоретической линией регрессии. Она получена косвенным путем на основе ограниченного количества наблюдений. На теоретическую линию регрессии также влияют случайные факторы, хотя и меньше, чем на эмпирическую. Это связано с тем, что теоретическая линия регрессии, рассчитанная по критерию наименьших квадратов, ближе к точкам реального корреляционного поля, чем предельная теоретическая линия регрессии, так как теоретическая линия регрессии рассчитана именно на основании этих точек. Поэтому ηT, дает нам преувеличенное значение тесноты связи между y и x, хотя это преувеличение в общем случае меньше, чем при использовании эмпирической линии регрессии.
, не является предельной теоретической линией регрессии. Она получена косвенным путем на основе ограниченного количества наблюдений. На теоретическую линию регрессии также влияют случайные факторы, хотя и меньше, чем на эмпирическую. Это связано с тем, что теоретическая линия регрессии, рассчитанная по критерию наименьших квадратов, ближе к точкам реального корреляционного поля, чем предельная теоретическая линия регрессии, так как теоретическая линия регрессии рассчитана именно на основании этих точек. Поэтому ηT, дает нам преувеличенное значение тесноты связи между y и x, хотя это преувеличение в общем случае меньше, чем при использовании эмпирической линии регрессии.
СПИСОК ЛИТЕРАТУРЫ
- Ibrahimova S.R. The mathematical modeling of sustainable development of environmentally hazardous area. ISNET Journal of Space Sciences and Technology. Vol.1., No.1, 2004.
- Ablameiko S.V., Kuleshov A.Ya. Automatic Classification of Gray-Scale-Image Objects by the Autocorrelation Similarity Measure of Their Arc-Approimated Contours //Pattern Recognition and image analysis. 1996.Vol. 6. № 3. pp. 572 - 581.
- Гуревич И.Б. Проблема распознавания изображений. //Распознавание, классификация, прогноз. Математические методы и их применение. М.: Наука, 1989. Вып. 1. С. 280 - 329.
- Катыс Г.П., Пержу В.Л., Ротарь С.П. Методы и вычислительные средства обработки изображений. Кишинев: Штиинца, 1991. 211 с.
- Боричев С.П., Крючков А.Н. Алгоритм фильтрации изображений, использующий параллельные операции сдвига и сложения при свертке изображений с масками преобразований. //Анализ цифровых изображений. Минск: ОИПИ НАН Беларуси, 2002. Вып. 1. С. 7-13.
- Ibrahimova S.R. Methods of remote sounding of the ground with application new information technologies. News of NAS Azerbaijan Republic. 2002, v. XXII, №2-3, pp. 168-173.
- Ibrahimova S.R The methodology of the geographical information system technology using remote sensing data. Proc. Int. Conf. "Nasiraddin Tusi and Modern Astronomy". 4-7 October, 2001, pp.230-235.
Библиографическая ссылка
Ибрагимова С.Р. АЛГОРИТМЫ ТОЧНОЙ КЛАССИФИКАЦИИ АЕРОКОСМИЧЕСКИХ ИЗОБРАЖЕНИЙ // Современные наукоемкие технологии. 2006. № 1. С. 8-13;URL: https://top-technologies.ru/ru/article/view?id=22308 (дата обращения: 23.07.2026).