


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
AUTOMATIZATION OF CUSTOMER INQUIRY PROCESSING

Введение
Качество обслуживания клиентов для современного бизнеса, независимо от того, какая категория товаров или услуг предлагается, выступает одним из наиболее значимых факторов, определяющих успех и позиции на конкурентном рынке [1, 2]. Ведущим инструментом, позволяющим грамотно выстраивать взаимоотношения с клиентами, зачастую является система обратной связи. С одной стороны, она позволяет своевременно реагировать на рекламации и решать задачи тактического назначения, не давая конфликтным ситуациям усугубляться. А с другой, формировать стратегические управленческие решения на основе собранной статистики [3]. Если положительные отзывы в основном влияют на формирование репутационного поля, то отзывы негативного плана, помимо этого, могут приводить к реальным потерям и оттоку важных клиентов [4, 5]. К сожалению, существующие у большинства компаний традиционные методы обработки обращений часто связаны с ручной работой, высокой нагрузкой на сотрудников и риском ошибок, что приводит к затягиванию решения проблем. Помимо этого, без специализированных инструментов часто не удается сразу определить приоритетность и категорию каждого обращения. Нередко система обратной связи имеет недостаточную интеграцию с внутренними процессами компании, что может приводить к ненамеренному игнорированию негативных отзывов [6]. Многие организации не имеют инструментов для комплексного анализа обратной связи, а без него невозможно выявить системные проблемы и своевременно принимать управленческие решения. В связи с этим возникает необходимость разработки и внедрения автоматизированных систем, способных анализировать отзывы с использованием современных методов анализа текста (например, машинного обучения), классифицировать обращения и автоматизировать маршрутизацию процессов решения проблем. На актуальность такой разработки также указывает использование инструментов автоматизации обратной связи как крупными частными корпорациями (например, чат-боты и виртуальные ассистенты Tele2 и Sberbank) [7], так и учреждениями государственного сектора [8]. Нередко подобного рода системы встречаются в автоматизированных системах обучения [9–11].
Цель исследования – моделирование процессов для автоматизированной системы обработки клиентских обращений и подбор наиболее эффективных моделей машинного обучения для определения тональности обратной связи.
Материалы и методы исследования
В рамках данного исследования проведено экспериментальное сравнение характеристик трех алгоритмов для задачи определения тональности (sentiment analysis): BERT, DistilBERT и TextBlob. Оценка их эффективности осуществлялась с использованием метрики F1-score на трех различных наборах данных. В качестве исходных материалов использовался Yelp Review Polarity Dataset1 – сбалансированный набор данных, содержащий 598 000 текстовых отзывов, которые оставляли пользователи о различных предприятиях сферы услуг: отрицательные (1 и 2 звезды) и положительные (3 и 4 звезды). Вторым источником данных выступал Amazon Product Reviews Dataset2 – набор отзывов на товары с платформы Amazon, включающий 142 млн объектов и характеризующийся большим разнообразием тем и форматов отзывов. Третьим датасетом был выбран Rotten Tomatoes Reviews Dataset (Movie Review Sentence Polarity Dataset)3, который содержит короткие текстовые фрагменты из кинорецензий, численностью 10 662 примеров, и из-за небольшой средней длины предложений (около 21 слова) удобен для оценки эффективности моделей в условиях дефицита контекста. Моделирование бизнес-процессов автоматизированной обработки отзывов проводилось с помощью BPMN-диаграмм и диаграмм последовательности (Sequence Diagram) в нотации UML, что позволило более структурированно описать все этапы обработки и взаимодействие системных компонентов.
Результаты исследования и их обсуждение
Процесс обработки клиентского отзыва в информационной системе компании реализуется поэтапно, что важно учитывать на всем жизненном цикле разработки. Принимая во внимание обзор существующих решений для автоматизации управления клиентскими запросами в различных областях [9, 12] и видоизменив стандартные схемы реализации таких решений, можно предложить следующий сценарий работы. После того как отзыв поступает в систему, производится его автоматизированный анализ, который осуществляется за счет встроенного модуля машинного обучения. Сам ML-анализатор выполняет задачу по определению тональности отзыва (позитивная, нейтральная, негативная). В зависимости от алгоритма машинного обучения такой модуль может также соотнести отзыв с конкретной категорией и присвоить обращению степень срочности или приоритетности реагирования, указывая это затем в диспетчере задач. В системе также необходимо предусмотреть отдельный модуль для сбора и хранения поступивших обращений, реализованный в виде единой базы данных. Лицам, принимающим решения, доступ к таким данным позволяет отслеживать истории взаимодействия с конкретным клиентом для персонализации предложений, а также проводить комплексный анализ динамики настроений и предпочтений всех клиентов.
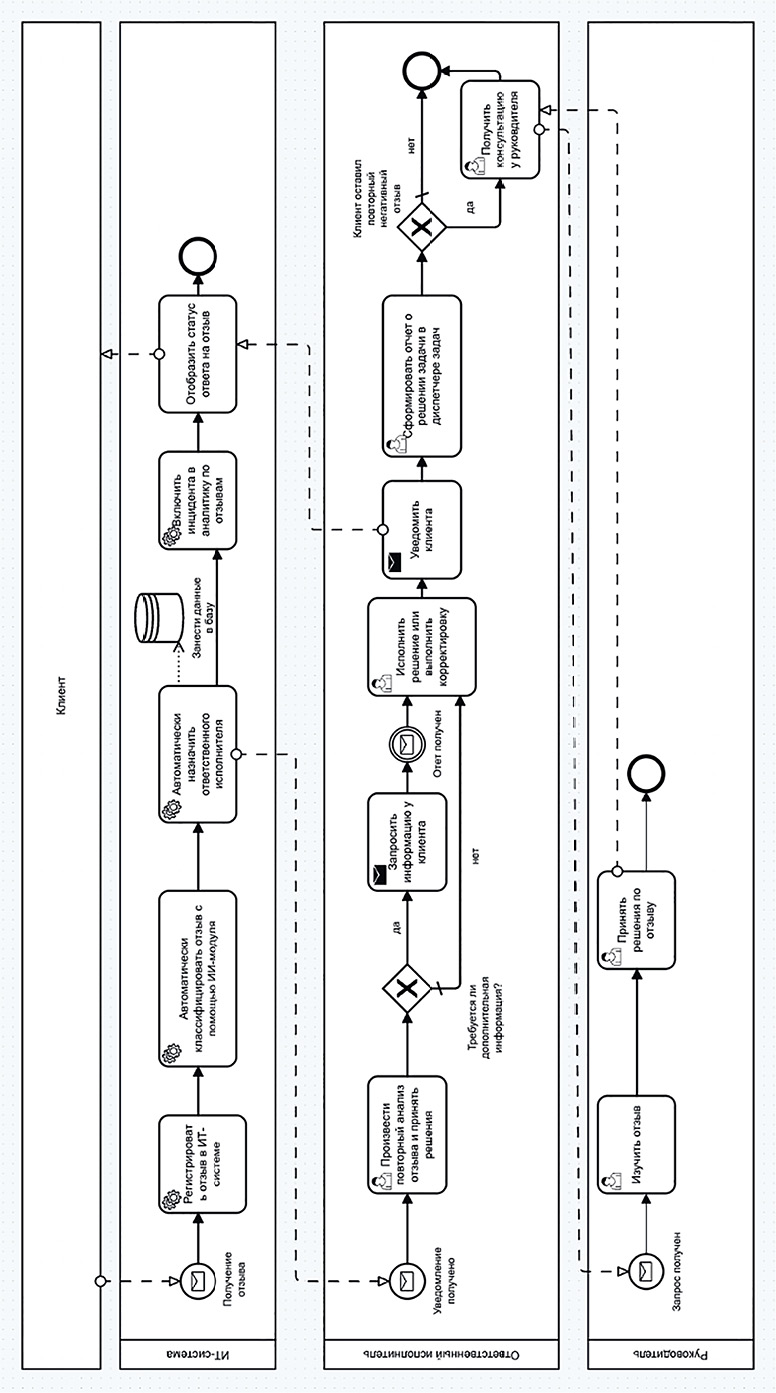
Рис. 1. BPMN диаграмма возможных процессов в автоматизированной системе для обработки отзывов Примечание: составлен авторами по результатам данного исследования
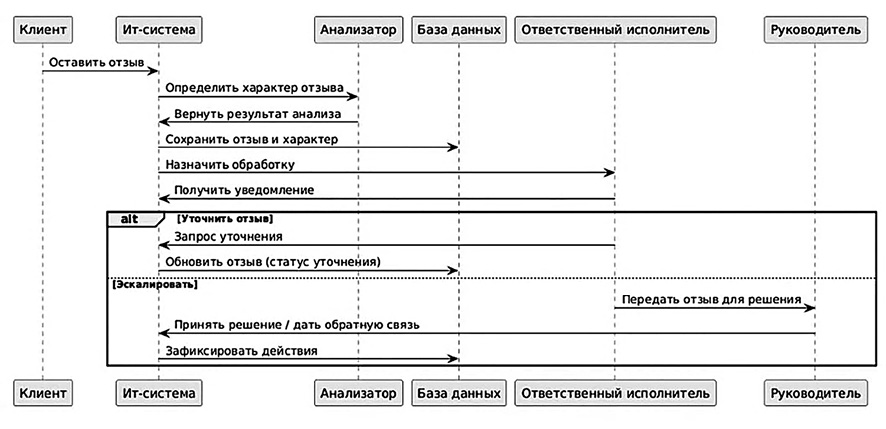
Рис. 2. Модель последовательностей действий компонентов автоматизированной системы обработки отзывов Примечание: составлен авторами по результатам данного исследования
Таблица 1
Сравнение моделей и фреймворков для определения тональности
|
Модель / Фреймворк |
Тип модели |
Преимущества |
Недостатки |
Области использования |
|
BERT |
Трансформер |
Высокая точность, хорошо понимает контекст |
Требует больших вычислительных ресурсов |
Исследовательские проекты |
|
RoBERTa |
Модификация BERT |
Оптимизированная версия BERT с улучшенной точностью |
Сложность настройки и обучения |
Коммерческие сервисы NLP |
|
DistilBERT |
Упрощенный BERT |
Быстрее и легче при сохранении качества |
Немного уступает в точности большим моделям |
Бизнес-приложения с ограниченными ресурсами |
|
TextBlob |
Библиотека Python |
Простота использования, наличие базовых возможностей |
Ограниченная точность на сложных отзывах |
Малые и средние проекты, обучение новичков |
|
VADER |
Лексический анализ |
Подходит для соцсетей и коротких сообщений |
Не справляется с иронией и сложным контекстом |
Анализ социальных медиа и маркетинг |
|
FastText |
Встраивание слов |
Быстрая работа, поддержка многих языков |
Меньше внимания к контексту |
Проекты с многими языками |
|
RuBERT |
Русскоязычный BERT |
Высокая точность для русского языка |
Требует настройки под конкретные задачи |
Анализ отзывов в России, локализованные решения |
Примечание: составлена авторами на основе источников [13–15].
В автоматизированной системе по итогам работы ML-модуля должны формироваться задачи для сотрудников (например, обработка жалоб, подготовка ответов, проведение разъяснительной работы или инициирование улучшений). Использование правильного диспетчера задач позволяет также осуществлять мониторинг исполнения автоматически выставленных поручений, а в случае затруднения в принятии решения давать возможность связаться с клиентом, если это CRM-система (Customer Relationship Management), или получить разъяснения у руководителя. Примерный вариант описания бизнес-процессов для такой системы представлен на рис. 1.
Учет всех участников взаимодействия при проектировании автоматизированной системы обработки отзывов, а также последовательность их действий могут быть отражены с помощью диаграммы последовательностей в нотации UML (рис. 2). Это дает разработчику более полное представление о хронологии действий и ключевых модулях системы. На диаграмме в отдельные Lifelines выделены клиент, ИТ-система, ML-анализатор, база данных, ответственный исполнитель и руководитель.
Отдельного внимания заслуживает процесс отбора алгоритма машинного обучения для ML-анализатора. Как показывает ряд авторов [13–15], в задачах определения тональности, в том числе для отзывов, оставленных на различных платформах клиентами, высокую эффективность демонстрируют DistilBERT, TextBlob, VADER, FastText, RuBERT. Для дальнейшего отбора с целью рекомендации к использованию в автоматизированной системе обработки отзывов было проведено сопоставление этих моделей и фреймворков по ряду параметров. Результаты приводятся в табл. 1.
Исходя из проведенного сравнительного анализа различных моделей и фреймворков, для дальнейшей экспериментальной проверки на данных целесообразнее выбрать BERT, DistilBERT, TextBlob и RuBERT. Однако область применения последней модели ограничивается русскоязычными текстами, и, несмотря на то, что проверка этой модели была бы полезна для отечественных систем, предназначенных для взаимодействия с клиентами, отсутствие реальных (не синтетических) данных в открытом доступе затрудняет ее объективное сравнение с другими моделями. Возможно, сбор данных об отзывах в русскоязычном сегменте с их последующей разметкой мог бы стать отдельной исследовательской задачей и оказать ценную помощь для разработки более точных и релевантных моделей по анализу клиентских настроений.
Как было описано в разделе «Материалы и методы исследования», сравнение моделей производилось на трех различных датасетах (Yelp Review Polarity Dataset, Amazon Product Reviews Dataset и Rotten Tomatoes Reviews Dataset), хорошо зарекомендовавших себя в задачах определения тональности. Значение основных метрик, а также время работы моделей при экспериментальном сравнении приведены в табл. 2.
Результаты работы моделей сопоставлялись по значениям стандартных метрик задачи классификации: Accuracy, Precision, Recall, F1-score (учитывающей баланс точности и полноты предсказаний), а также по времени, затраченному на предсказание и обучение модели. Последний столбец табл. 2 показывает, что TextBlob, основанный на простых правилах и словарях, обладает преимуществом довольно быстрого развертывания и низкой вычислительной сложности, что может быть полезно для ряда прикладных сценариев, где время играет решающую роль. Однако по всем трем метрикам TextBlob демонстрирует самые низкие оценки.
В задачах анализа настроений или определения характера отзыва важна способность модели находить все позитивные примеры без чрезмерных ложных срабатываний, что делает F1-score более информативной, чем остальные метрики по отдельности. Также эта метрика особенно полезна для данных с несбалансированными классами, поскольку обеспечивает более объективную оценку при определении миноритарного класса. Сравнение BERT, DistilBERT и TextBlob по значениям F1-score приведено на рис. 3.
Таблица 2
Оценка качества определения тональности BERT, DistilBERT, TextBlob и время их работы
|
Модель/ фреймворк |
Датасет |
Accuracy |
Precision |
Recall |
F1-Score |
Время на итерацию/ предсказание |
|
DistilBERT |
Yelp Review Polarity |
86,0 % |
87,0 % |
85,0 % |
86,0 % |
0,5 мин / 1,2 мин |
|
Amazon Product Reviews |
87,8 % |
86,2 % |
88,4 % |
87,3 % |
0,6 мин / 1,3 мин |
|
|
Rotten Tomatoes Reviews |
82,5 % |
83,5 % |
80,5 % |
82,0 % |
0,5 мин / 1,2 мин |
|
|
TextBlob |
Yelp Review Polarity |
65,0 % |
60,0 % |
55,0 % |
57,0 % |
4 с / 13 с |
|
Amazon Product Reviews |
73,2 % |
72,5 % |
73,8 % |
73,1 % |
5 с / 15 с |
|
|
Rotten Tomatoes Reviews |
51,0 % |
60,0 % |
48,5 % |
52,5 % |
4 с / 12 с |
|
|
BERT |
Yelp Review Polarity |
88,0 % |
89,0 % |
87,0 % |
88,0 % |
1 мин / 2,5 мин |
|
Amazon Product Reviews |
89,2 % |
88,7 % |
89,8 % |
89,2 % |
1,5 мин / 2,8 мин |
|
|
Rotten Tomatoes Reviews |
87,0 % |
88,0 % |
85,0 % |
86,0 % |
1 мин / 2,4 мин |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
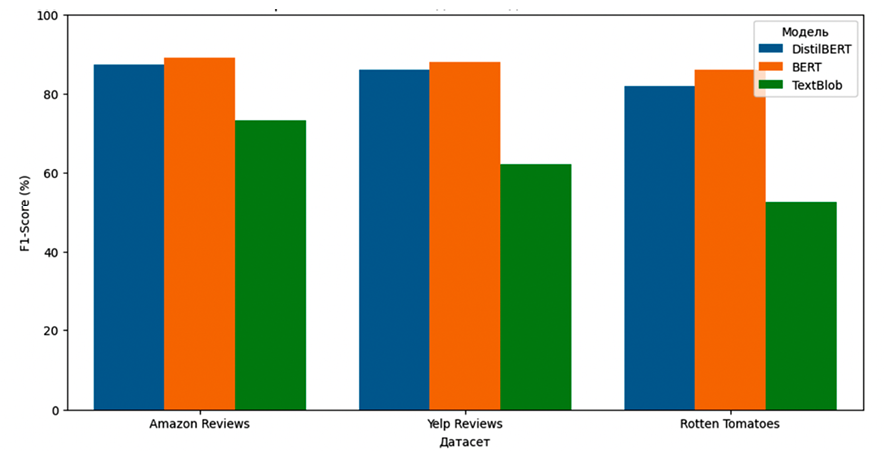
Рис. 3. Сравнение моделей по метрике F1-score на различных датасетах Примечание: составлен авторами по результатам данного исследования
На всех трех наборах данных, несмотря на самые большие временные затраты на обучение и работу, модель BERT оказалась наиболее успешной. Она проявила себя эффективнее облегченной модели DistilBERT и значительно превзошла по ключевой метрике F1-score результаты TextBlob. В автоматизированных системах обработки клиентских обращений, бесспорно, ее можно рекомендовать в качестве ведущей модели ML-анализатора не только из общих соображений и обзора опубликованных сведений, но и по итогам экспериментальной проверки.
Для автоматизированных систем с большим объемом отзывов и активной обратной связью от клиентов модуль машинного обучения может включать суммаризатор отзывов. Суть его работы состоит в том, что он создает короткие и сжатые варианты по большому числу отзывов с сохранением смысла. Это позволяет не только аналитическому отделу отслеживать какие-то глобальные тенденции, но и самим пользователям быстрее ориентироваться при выборе товара или сервиса, которые предоставляет компания. Однако разработка такого суммаризатора требует отдельного исследования и экспериментального сравнения различных моделей машинного обучения по преобразованию длинных текстов в короткие и не входит в задачи данной работы.
Заключение
В рамках данной работы было проведено моделирование автоматизации процесса обработки клиентских обращений с использованием системных инструментов BPMN и UML-диаграмм последовательности. Это позволило выделить и сделать более понятными основные этапы обработки обратной связи от клиентов.
В рассмотренные схемы предложено включить ML-анализатор, который предназначен для определения тональности клиентских сообщений (sentiment analysis) и автоматической генерации задач для сотрудников с указанием их приоритета. В работе был осуществлен экспериментальный отбор модели для такого анализатора, для этого DistilBERT, TextBlob и RuBERT были протестированы на трех различных наборах данных. Лучшие результаты по метрике F1-score продемонстрировала модель BERT, что подтверждает ее высокую точность и возможность использования для задач анализа пользовательских обращений.
Полученные результаты могут быть полезны разработчикам в области интеграции искусственного интеллекта в автоматизированные системы, что позволит компаниям, использующим такие системы, более эффективно осуществлять как тактические решения, требующие незамедлительных мер, так и стратегическое планирование на основе исторических данных.
[1] Yelp Review Polarity Dataset [Электронный ресурс]. URL: https://www.tensorflow.org/datasets/catalog/yelp_polarity_reviews?hl=ru (дата обращения: 14.03.2026).
[2] Amazon Product Reviews Dataset [Электронный ресурс]. URL: https://registry.opendata.aws/amazon-reviews/ (дата обращения: 14.03.2026).
[3] Rotten Tomatoes Reviews Dataset [Электронный ресурс]. URL: https://huggingface.co/datasets/cornell-movie-review-data/rotten_tomatoes (дата обращения: 14.03.2026).
Conflict of interest
Financing
Библиографическая ссылка
Чернявская А.В., Горшков К.А. АВТОМАТИЗАЦИЯ ПРОЦЕССА ОБРАБОТКИ КЛИЕНТСКИХ ОБРАЩЕНИЙ // Современные наукоемкие технологии. 2026. № 5. С. 108-114;URL: https://top-technologies.ru/en/article/view?id=40782 (дата обращения: 23.07.2026).
DOI: https://doi.org/10.17513/snt.40782