


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
Data-Driven Economy: The Digital Logic of Decision-Making Under Conditions of Complexity and Uncertainty

Введение
Экономическая реальность переживает не просто изменения, она трансформируется с беспрецедентной скоростью. Информационные потоки увеличиваются в разы, связи между участниками рынков становятся всё более запутанными, а привычные подходы к принятию решений теряют эффективность. Там, где раньше можно было положиться на опыт или интуицию, теперь этого недостаточно. Слишком многое происходит одновременно и слишком многое влияет на результат.
Перед исследователями и практиками встаёт всё более острый вопрос: как принимать решения в условиях, где количество факторов давно вышло за пределы, которые можно удержать в голове? Как управлять системой, поведение которой становится всё менее предсказуемым, а реакции нестабильными и нелинейными?
Ответы всё чаще ищут в области алгоритмических решений. Инструменты автоматизации, оптимизационные методы, технологии машинного обучения – то, что ещё недавно воспринималось как эксперимент или редкость, сегодня становится частью обыденной управленческой практики [1-3]. Эти подходы не просто ускоряют обработку информации: они переопределяют само понимание управления. Вместо анализа по факту – прогноз, вместо интуитивных решений – модели, способные «учиться» на данных. Управленческое мышление смещается: от стабильных схем к адаптивным системам, от отчётов к динамическим решениям, которые реагируют на изменения среды в реальном времени [4-6].
Особый интерес вызывает прикладной аспект: насколько далеко можно продвинуться в использовании математического моделирования и алгоритмов обучения для решения конкретных экономических задач? Например, при распределении ресурсов, планировании затрат, выборе оптимальных стратегий [7-9]. Насколько надёжными оказываются модели, когда они сталкиваются не с абстрактными допущениями, а с реальными, «шумными» и часто неполными экономическими данными?
Рациональность в экономике всегда связана с точкой опоры. В традиционной экономической логике эта опора строилась на упрощённой модели мира: ограниченное число факторов, предсказуемые взаимосвязи, стабильные параметры. Такая схема позволяла мыслить в рамках расчёта и логики, формируя представление о рациональном агенте, действующем в пределах заданных условий [10-12]. Однако по мере распространения цифровой среды эта картина начала терять устойчивость. Потоки информации стали непрерывными, поведение участников рынка всё менее предсказуемым, а системы подверженными нелинейным реакциям. Объём данных, с которым приходится работать, уже превышает возможности человеческого восприятия и осмысления [13; 14]. Как следствие, классическая модель рациональности сталкивается с ограничениями применимости. Цифровая рациональность сохраняет логику, но переносит её в иную плоскость. Если раньше мышление выражалось через рассуждение, то теперь оно воплощается в алгоритме. Модель перестаёт быть просто уравнением, она становится вычислительной структурой, способной адаптироваться и развиваться. Вместо одного «экономического агента» тысячи, смоделированных в цифровой среде. Вместо ручного анализа автоматизированное обучение на данных, которые поступают в режиме реального времени.
Возьмём, к примеру, задачу планирования производственных затрат при наличии ресурсных ограничений. В классической постановке это решается с помощью линейной модели и симплекс-метода. Такая схема действительно позволяет найти оптимум, при условии, что входные параметры заданы точно, а зависимости между переменными сохраняют линейный характер [7; 15]. Но в условиях цифровой среды эти допущения редко выдерживают проверку. Зависимости оказываются сложными, ограничения подвижными, а система динамичной и непредсказуемой. Здесь классическая логика начинает буксовать. На передний план выходят методы машинного обучения [13; 16]. При прогнозировании спроса на продукцию, где учитываются сезонность, цены конкурентов, логистика и погодные условия, применяются модели временных рядов и градиентный бустинг (например, XGBoost, LightGBM). Эти алгоритмы выявляют сложные связи, могут работать с неполными данными и демонстрируют высокую точность предсказаний.
Ещё один пример: использование регуляризованных регрессионных моделей (Lasso, Ridge) для работы с большим числом переменных, где важна устойчивость к переобучению. Или алгоритмы кластеризации, такие как k-means и DBSCAN, которые позволяют сегментировать клиентов на основе поведенческих паттернов. Все эти методы дают возможность анализировать данные, с которыми традиционные экономические подходы просто не справляются.
Иначе говоря, данные перестают быть лишь вспомогательным ресурсом, они становятся средой, в которой формируются новые механизмы принятия решений. Аналитика движется от констатации к симуляции, от теории к предсказанию, от жёсткой модели к гибкой вычислительной системе [13]. Важно понимать: данные сами по себе не решают задач. Без модели они остаются неструктурированной массой. А модель не может работать без метода. Поэтому цифровая трансформация без опоры на устойчивые формальные структуры, будь то методы линейной оптимизации или алгоритмы машинного обучения, приводит лишь к накоплению необработанных массивов, неспособных трансформироваться в знание.
Целью работы является исследование и применение математических моделей и методов машинного обучения для анализа и прогнозирования экономических показателей, а также выявление ограничений и возможностей их использования.
Материалы и методы исследования
В центре внимания – разработка и тестирование моделей, сочетающих методы линейного программирования и машинного обучения – гибридной архитектуры, в которой неопределённость компенсируется за счёт прогнозов, полученных с помощью машинного обучения.
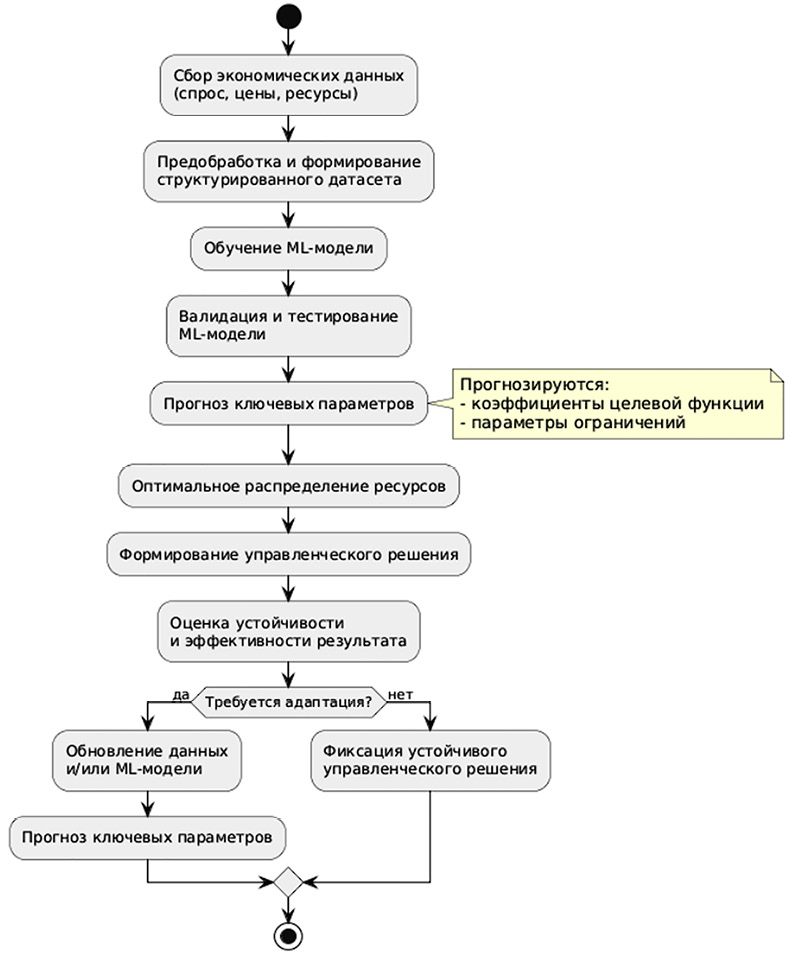
Рис. 1. Схема алгоритма принятия решения Примечание: составлено авторами по результатам данного исследования
Такой подход был реализован в рамках экспериментальной системы, где на вход машинной модели подавались данные прошлых периодов: цены, объёмы, спрос, издержки. Алгоритм (в данном случае использовались методы градиентного бустинга) строил прогноз для ключевых параметров: коэффициентов целевой функции и ограничений. Затем эти значения передавались в модуль линейного программирования (ЛП), где уже происходил сам расчёт оптимального решения (рис. 1).
Задачей разработки было создание системы, которая предсказывает оптимальные решения для задач ЛП без необходимости заново выполнять точную оптимизацию, что позволяет ускорить процесс принятия решений в условиях быстроменяющегося производства. Python стал выбором, который оказался логичным благодаря своей популярности в научных и инженерных областях, включая математическое моделирование и анализ данных. Но важнее всего, что он предоставляет мощные библиотеки для оптимизации, обработки данных, обучения моделей и визуализации, позволяя создавать интегрированные решения, которые легко адаптируются под изменяющиеся требования. Система строится на основе набора тщательно выбранных библиотек, каждая из которых выполняет свою важную функцию:
• scipy.optimize – основная библиотека для решения задач линейного программирования. С версии SciPy 1.6 функция linprog интегрировала решатель HiGHS – высокопроизводительный оптимизатор, написанный на C++. Этот решатель способен обрабатывать задачи линейного программирования с огромным числом переменных и ограничений, эффективно масштабируясь на многопроцессорных системах;
• numpy и pandas – эти библиотеки позволяют формировать матрицы ограничений и коэффициенты целевых функций;
• PyTorch – мощный фреймворк для создания нейронных сетей, который предоставляет гибкость в настройке модели и доступ к GPU для ускорения вычислений, в качестве функции потерь используется Mean Squared Error (MSE);
• streamlit – библиотека для создания интерфейсов, которая превращает взаимодействие с системой в простой и понятный процесс. Пользователи могут загружать данные, визуализировать результаты и анализировать ошибки;
• openpyxl / xlrd – библиотеки для работы с Excel, которые позволяют загружать параметры задач из таблиц и сохранять результаты вычислений.
Результаты исследования и их обсуждение
Проверялась не только математическая корректность, но и практическая устойчивость модели. Сценарии варьировались от стабильных до резко изменяющихся условий, и во всех случаях гибридная система демонстрировала адаптивность выше, чем у классических решений, основанных только на исходных данных. Результаты оказались значимыми: и по скорости, и по точности. Об адекватности предлагаемой модели судили по точности прогноза и устойчивости оптимизационного решения при изменении входных параметров. Особенно это критично в задачах с высокой частотой принятия решений: в закупках, логистике, распределении фондов, где на раздумья попросту нет времени. Модель обучалась на датасете множества задач размерности 30×40; ввиду громоздкости представление входных и выходных данных здесь опущено, однако приведены расчёты средних ошибок и сравнение времени для одной из таких задач (рис. 2).

Рис. 2. Результаты запуска модели для задачи 30×40 (MAE – средняя абсолютная ошибка, MSE – среднеквадратическая ошибка) Примечание: составлено авторами по результатам данного исследования
В рамках исследования проверялось, насколько предложенный метод работает в условиях, приближенных к реальным задачам управления. В качестве предмета анализа были выбраны сценарии, где требовалась оптимизация расходов при ограниченности ресурсов и изменчивости внешних параметров. За основу бралась классическая задача линейного программирования: целевая функция отражала стремление минимизировать совокупные издержки, а ограничения описывали ресурсные лимиты, бюджетные рамки и предполагаемые значения ключевых экономических факторов. При этом параметры модели не задавались вручную, а рассчитывались с помощью прогнозов, полученных на основе структурированного массива данных, имитирующего поведение спроса, динамику цен и доступность ресурсов. Эти данные были предварительно очищены и нормализованы, при этом сохранялась логика их экономических взаимосвязей. Несмотря на компактный объём, база позволила протестировать основные принципы интеграции машинного прогноза в классическую схему оптимизации. Эксперимент показал: даже ограниченный, но осмысленно подобранный массив данных может лечь в основу адаптивной системы, способной генерировать устойчивые управленческие решения.
Важно отметить, что цель исследования не заключалась в построении полноформатной промышленной модели с подключением крупных наборов или сложных ML-фреймворков. Ставилась более простая, но принципиальная задача: проверить, возможно ли повысить эффективность классической оптимизации за счёт прогнозного блока, и если да, то насколько ощутим будет эффект. Для оценки использовались понятные метрики: степень снижения издержек, соблюдение заданных ограничений, стабильность результатов при варьировании входных данных.
Результаты оказались обнадёживающими. Даже при использовании довольно простых алгоритмов и небольшой глубине исторической выборки система демонстрировала устойчивость и практическую применимость. Причём с сохранением одного из ключевых качеств – интерпретируемости. Было ясно, какие именно ограничения повлияли на результат, как перераспределились ресурсы и каким образом изменялись коэффициенты в зависимости от вводных условий. Это позволяет рассматривать предложенную модель как адекватный инструмент для задач, в которых необходимо сочетать прогнозирование и оптимизацию в условиях изменяющейся внешней среды. Понимание, откуда берётся то или иное значение, почему модель предлагает именно это решение и какие факторы лежат в его основе, не менее значимо, чем сам расчёт. Всё чаще ценится не просто само решение, а его обоснованность: откуда оно взялось, на каких данных построено, как поведёт себя при изменении исходных условий. Именно поэтому комбинация прозрачности и адаптивности становится важным ориентиром для прикладной экономической аналитики. Принятие решений перестаёт быть точкой завершения анализа, оно становится этапом в непрерывной цепочке: формулировка гипотезы, расчёт, проверка, корректировка, пересмотр. Формируется новая управленческая среда, где цифровая модель перестаёт быть вспомогательным инструментом. Она становится центральным элементом принятия решений. Экономика всё в большей степени обретает свойства обучаемой системы не только потому, что используются методы машинного обучения, но и потому, что само управленческое мышление становится способным к обучению. На данных. На ошибках. На взаимодействии с моделью.
Заключение
Можно ли действительно управлять экономикой не декларативно, а в смысле осознанного, основанного на данных, принятия решений? Результаты проделанной работы позволяют говорить об этом не как о мечте, а как о достижимой, пусть и сложной, цели.
Показанный в исследовании подход продемонстрировал, что даже при умеренной технической сложности цифровые модели могут существенно повысить качество управленческих решений, прежде всего в задачах распределения продукции, ресурсов и инвестиций, минимизации затрат и учёта производственных, ресурсных, временных и бюджетных ограничений. Важно, что речь идет не о замене людей алгоритмами, а о совместной работе: там, где человек определяет цель и контекст, а модель помогает просчитать варианты, сократить неопределённость и оперативно отреагировать на изменения.
На первый план выходит не только вычислительная точность, но и новое восприятие самой управленческой деятельности. Моделирование становится частью мышления, способом удерживать сложные взаимосвязи в рабочем фокусе, уточнять предположения, вовремя корректировать курс. Управление перестаёт быть разовой реакцией на ситуацию и становится цикличным процессом: прогноз – действие – обратная связь – настройка.
При этом важно сохранять трезвый взгляд на возможности и ограничения алгоритмических систем. Модель эффективна там, где есть структура, регулярность и данные, особенно в сценариях с повторяющимися управленческими решениями и изменяющимися внешними параметрами. Но она не способна подменить человеческий смысл. Она может предложить «как», но не ответит «зачем». Вопросы целей, рисков, долгосрочной устойчивости по-прежнему требуют человеческого суждения со стратегическим горизонтом и пониманием контекста, которого нет в числах.
Алгоритм не ошибается «по-своему», он просто следует логике, вшитой в исходные предпосылки. А значит, критическое мышление, способность задавать правильные вопросы и понимать, где заканчивается зона применимости модели, – остаются ключевыми управленческими навыками. Ответственность никуда не делась, она просто теперь требует цифровой грамотности.
Тем не менее тенденция очевидна: цифровое моделирование уже перестраивает то, как люди планируют, реагируют и принимают решения. Оно не заменяет классическое экономическое мышление, но дополняет его, делает его гибче, быстрее и более структурированным. Это не идеальная система, но это шаг вперёд: от интуитивного управления к управлению, в котором гипотезы можно проверить, решения уточнить, а последствия просчитать заранее.
Именно в этом суть «управляемой экономики»: не в том, чтобы всё заранее знать, а в том, чтобы уметь учиться на ходу. Не искать окончательных ответов, а выстраивать процессы, где человек и модель работают вместе, чтобы принимать решения, которые не просто возможны, а осмысленны.
Conflict of interest
Financing
Библиографическая ссылка
Асхатов Р.М., Гильман Д.М., Дубровин В.Т., Хисматуллина Р.Р., Чебакова В.Ю. Data-driven экономика: цифровая логика принятия решений в условиях сложности и неопределённости // Современные наукоемкие технологии. 2026. № 5. С. 10-15;URL: https://top-technologies.ru/en/article/view?id=40769 (дата обращения: 23.07.2026).
DOI: https://doi.org/10.17513/snt.40769