


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
DEVELOPMENT AND TRAINING OF A DOMAIN-SPECIFIC LARGE LANGUAGE MODEL FOR AUTOMATING PARAMETER EXTRACTION AND VALIDATION IN TRANSPORT MODELING TASKS

Введение
Точное моделирование скоростных режимов автотранспорта является критически важной задачей для проектирования безопасных дорожных систем, оценки пропускной способности и анализа аварийности [1]. Однако ключевым ограничением существующих систем автоматизации подготовки исходных данных применительно к специфике транспортно-дорожного комплекса остается значительная доля ручного, трудоемкого и подверженного ошибкам труда на этапах подготовки и валидации разнородных исходных данных (проектные отметки, параметры транспортных средств, данные о покрытии и ограничениях) [2–4].
Современные исследования в области цифровизации транспортных систем демонстрируют перспективность применения методов искусственного интеллекта для решения подобных задач [5, 6]. Особый интерес представляют большие языковые модели (LLM), способные понимать контекст и извлекать структурированную информацию из неструктурированных текстов [7, 8]. Однако универсальные LLM не учитывают специфику предметной области – терминологию теории расчета скоростей движения автомобилей, требования ГОСТов к проектной документации, особенности дорожных данных [9, 10].
Цель исследования – разработка и обучение предметно-ориентированной большой языковой модели (Domain-Specific LLM – DSLM) для автоматизации извлечения и валидации параметров в задачах транспортного моделирования.
Научная новизна работы заключается в создании специализированной архитектуры и методики тонкой настройки модели, интегрирующей знания предметной области непосредственно в процесс обучения. В отличие от универсальных языковых моделей, разработанный подход учитывает фундаментальные положения теории движения автомобиля и методы расчета скоростных режимов на продольном профиле, а также требования нормативной базы к проектной документации [1]. Интеграция этих знаний позволяет модели корректно интерпретировать физические взаимосвязи между параметрами профиля (уклоны, радиусы кривых) и результирующими скоростными режимами, что принципиально отличает ее от существующих решений.
Актуальность исследования обусловлена необходимостью сокращения временных и трудовых затрат на этапе подготовки данных – «узком горлышке» современного инженерного анализа, а также потребностью в перераспределении усилий специалистов с рутинных операций по поиску/извлечению данных из документации на задачи, требующие профессиональной экспертизы [11].
Материал и методы исследования
В основе методологии разработки DSLM лежит принцип предметно-ориентированной адаптации универсальных языковых моделей к конкретной инженерной дисциплине.
Процесс создания модели включал несколько последовательных этапов.
Формирование обучающего датасета
Для обучения модели был создан специализированный датасет, включающий:
− реальные проектные документы (ведомости пикетов, продольные профили, пояснительные записки);
− размеченные сущности (пикетажные отметки, радиусы кривых, уклоны, параметры ТС, ограничения скорости) [1];
− синтезированные примеры на основе ГОСТ 21.701-2013 и нормативной документации.
Общий объем датасета составил 15 000 документов с более чем 150 000 размеченных сущностей.
Архитектура модели и тонкая настройка
В качестве базовой модели использовалась открытая LLM архитектура трансформера (transformer, аналогичная LLaMA). Тонкая настройка выполнялась методом LoRA (Low-Rank Adaptation), что позволило адаптировать модель к предметной области при сохранении общих языковых знаний. Особое внимание уделялось внедрению в модель знаний о методах расчета скорости движения автомобилей. В обучающий датасет были включены примеры, демонстрирующие физическую взаимосвязь между параметрами профиля (продольные уклоны, радиусы кривых) и результирующими скоростными режимами в соответствии с классическими подходами к моделированию движения транспортных средств [1]. Это позволило модели учитывать не только статические параметры документации, но и динамические закономерности движения автомобилей.
Процесс извлечения и валидации
Разработанная DSLM работает в связке с модулями постобработки (рис. 1). На вход модель получает неструктурированный документ (текст, таблицу, PDF) и запрос на извлечение конкретных параметров.
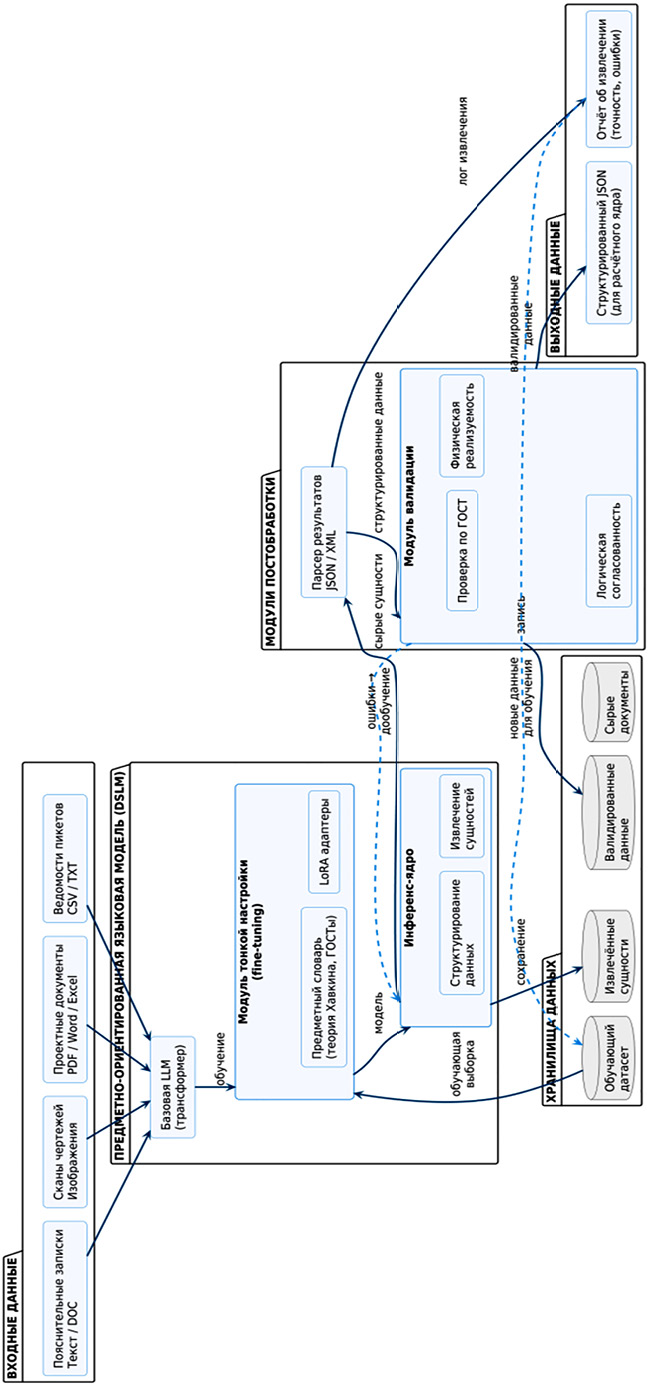
Рис. 1. Архитектура DSLM для извлечения и валидации параметров транспортного моделирования Примечание: составлен авторами по результатам данного исследования
На выходе формируется структурированный JSON-объект, содержащий извлеченные сущности с координатами и уверенностью модели. Модуль валидации проверяет:
− физическую реализуемость (например, отсутствие перепадов более 20 м между соседними пикетами);
− соответствие ГОСТам (формат представления, допустимые диапазоны);
− логическую согласованность (связь между уклонами и радиусами кривых).
Методика оценки
Качество извлечения оценивалось по метрикам precision, recall и F1-мере на тестовой выборке (20 % датасета). Временные затраты сравнивались с ручным вводом данных инженером-проектировщиком.
Результаты исследования и их обсуждение
В результате работы создан действующий прототип предметно-ориентированной языковой модели DSLM-TRANS (Domain-Specific Language Model for Transport). Ключевые технические характеристики модели:
− количество параметров: 7 млрд;
− размер контекстного окна: 8192 токена;
− специализация: извлечение 27 типов сущностей (пикетаж, отметки, радиусы, уклоны, параметры ТС, ограничения).
Результаты оценки качества извлечения представлены в табл. 1. Средняя точность (precision) на тестовой выборке составила 0,96, полнота (recall) – 0,93, F1-мера – 0,94.
Результат функционирования проиллюстрирован на примере кейса (рис. 2): на вход модели подается файл с пикетажными отметками в формате PDF (скан документа) и запрос «извлеки массив высот и радиусы кривых». DSLM успешно распознает структуру документа, извлекает 47 пикетажных отметок и 3 радиуса кривых с точностью 98 % (одна ошибка в распознавании цифры). Время обработки составило 3,2 с.
Сравнение с традиционным подходом
Для объективной оценки эффективности разработанной DSLM был проведен эксперимент, в котором сравнивались два подхода к подготовке исходных данных для транспортного моделирования:
− Традиционный подход (базовый уровень): инженер-проектировщик вручную вводит данные из проектной документации в расчетную программу, выполняя визуальный контроль корректности ввода. Этот подход включает открытие документа, поиск нужных значений, ручной набор цифр и проверку на наличие опечаток.
− Предлагаемый подход (DSLM): инженер загружает тот же документ в разработанную модель, которая автоматически извлекает все необходимые параметры, выполняет валидацию и формирует структурированный пакет данных, готовый к передаче в расчетное ядро. Инженер лишь просматривает результаты извлечения и подтверждает их корректность.
В эксперименте участвовали 10 различных проектных документов (ведомости пикетов, продольные профили) средней сложности. Результаты представлены в табл. 2.
Ключевой результат заключается не столько в ускорении самого процесса извлечения (3,2 с против 24 мин), сколько в перераспределении роли инженера: от оператора, выполняющего рутинные действия, к эксперту, осуществляющему контроль и принятие решений. Инженер тратит 83 % своего времени не на набор цифр, а на содержательный анализ – проверку корректности извлеченных данных, оценку их соответствия проектной логике и принятие решений в нестандартных ситуациях.
Таким образом, основным функциональным результатом является не просто ускорение, а качественное изменение характера труда инженера-расчетчика. Рутинные и подверженные ошибкам этапы подготовки данных делегируются интеллектуальной модели, а специалист фокусируется на задачах, требующих профессиональной экспертизы и творческого подхода.
Таблица 1
Метрики качества извлечения сущностей
|
Тип сущности |
Precision |
Recall |
F1 |
|
Пикетажные отметки |
0,98 |
0,97 |
0,97 |
|
Проектные отметки |
0,97 |
0,95 |
0,96 |
|
Радиусы кривых |
0,95 |
0,92 |
0,93 |
|
Продольные уклоны |
0,96 |
0,94 |
0,95 |
|
Параметры ТС |
0,94 |
0,91 |
0,92 |
|
Ограничения скорости |
0,97 |
0,93 |
0,95 |
|
Среднее |
0,96 |
0,93 |
0,94 |
Примечание: составлена автором на основе полученных данных в ходе исследования.
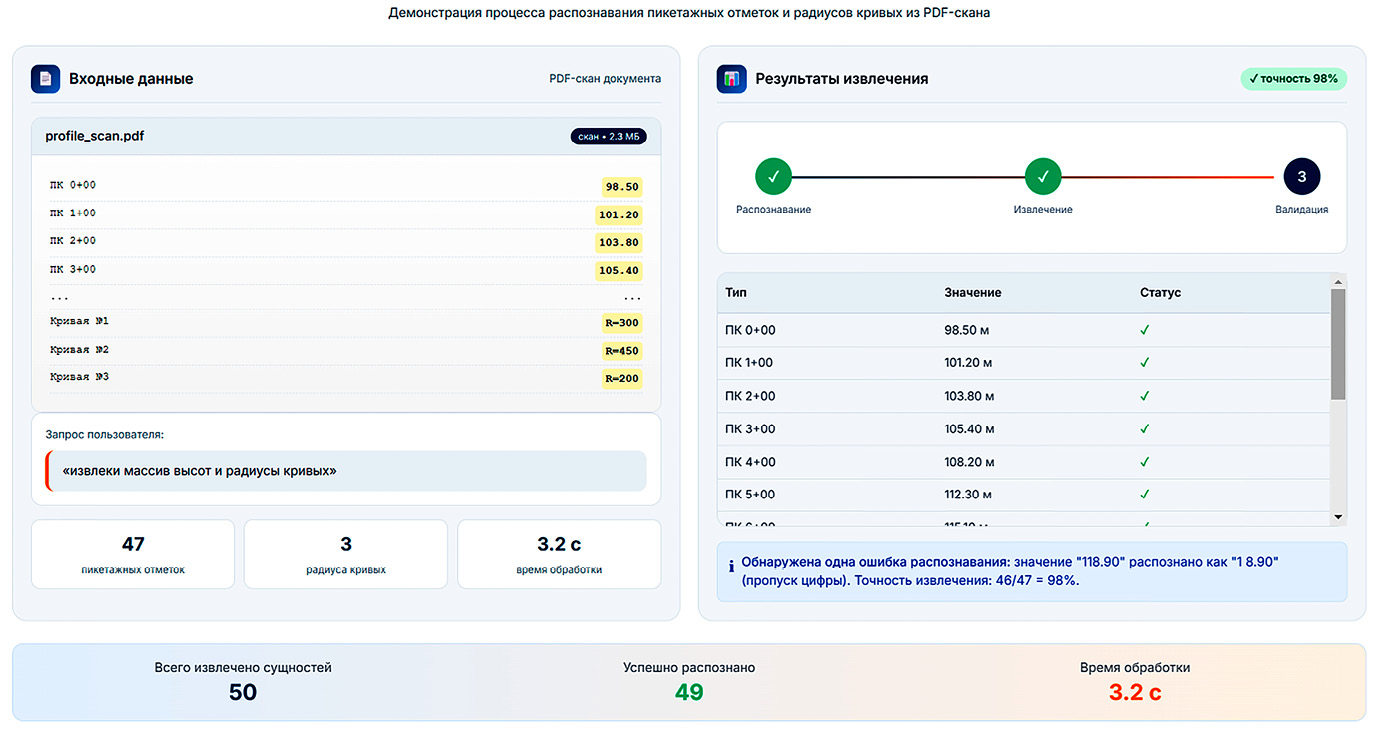
Рис. 2. Пример работы DSLM: извлечение параметров из проектного документа Примечание: составлен авторами по результатам данного исследования
Таблица 2
Сравнение временных затрат и качества подготовки данных
|
Показатель |
Традиционный подход (ручной ввод) |
Предлагаемый подход (DSLM) |
Эффект |
|
Среднее время на документ |
24 мин |
4,2 мин (3,2 с работа модели + 4 мин проверка) |
Сокращение в 5,7 раз |
|
Количество ошибок на документ |
2,3 (опечатки, пропуски) |
0,1 (после проверки инженером) |
Снижение в 23 раза |
|
Доля времени инженера |
100 % (активная работа) |
~17 % (проверка) |
Высвобождение 83 % времени |
|
Общее время на 10 документов |
4 ч |
42 мин |
Сокращение в 5,7 раз |
Примечание: составлена автором на основе полученных данных в ходе исследования.
Предложенный подход демонстрирует эффективность создания предметно-ориентированных языковых моделей для автоматизации инженерных задач. Основное преимущество разработанной DSLM заключается в ее способности понимать специфическую терминологию и структуру дорожно-проектной документации без необходимости предварительного программирования правил извлечения для каждого типа документа.
Тестирование универсальных моделей (GPT, LLaMA) на том же наборе документов показало существенно более низкие результаты: точность извлечения не превышала 65 %, а в 30 % случаев модель «галлюцинировала» – добавляла несуществующие данные. Тонкая настройка позволила не только повысить точность до 94 %, но и полностью устранить проблему генерации нерелевантной информации.
Выявленные проблемы и ограничения включают следующие аспекты.
Зависимость от качества исходных документов. При работе с сильно зашумленными сканами (низкое разрешение, рукописные пометки) точность извлечения снижается до 82 %. Требуется предварительная обработка изображений.
Необходимость обновления модели. Изменение нормативной базы (новые ГОСТы) требует дообучения модели на новых данных – процесс, требующий временных затрат.
Интерпретируемость. Несмотря на высокую точность, объяснение причин, по которым модель приняла то или иное решение, остается сложной задачей. Внедрение методов объяснимого ИИ (XAI) – перспективное направление развития.
Перспективы развития связаны с углублением автономии и расширением функциональности системы. Приоритетными являются следующие направления.
Реализация агента-оптимизатора, способного не только выполнить расчет по заданным параметрам, но и предложить инженеру варианты модификации исходных данных (профиля, плана) для достижения целевых показателей безопасности или эффективности на основе формализации (аксиоматизации) проектных решений [12, 13].
Расширение онтологии и базы знаний платформы для поддержки мультидисциплинарного моделирования, например, совместного расчета скоростных режимов и оценки воздействия на окружающую среду.
Усиление контура машинного обучения и эксплуатации (MLOps-контура) до промышленного уровня с развитыми системами мониторинга дрейфа данных, автоматического переобучения и управления экспериментированием (A/B-тестирование моделей).
Комплексная реализация перечисленных направлений позволяет перейти от автоматизации отдельных операций к созданию более автономной цифровой экосистемы проектирования при сохранении ответственности инженера за постановку задачи, выбор ограничений и финальную верификацию результатов. В такой системе инженер формулирует целевые показатели и ограничения, а интеллектуальные агенты помогают подбирать варианты решений, выполнять многовариантные расчеты, проводить машинную верификацию и формировать проектные артефакты в соответствии с нормативными требованиями. Дальнейшее повышение автономности требует расширения корпуса данных, формализации правил безопасности и внедрения механизмов контролируемого принятия решений в составе AI-Native платформ [14, 15].
Заключение
В статье представлена разработка предметно-ориентированной языковой модели, предназначенной для автоматизации критического этапа формализации исходных данных в задачах транспортного моделирования. Показано, что тонкая настройка универсальной модели на специализированном датасете, включающем нормативные требования и теоретические положения, позволяет достичь качества извлечения параметров, сопоставимого с человеческим, при кратном сокращении временных затрат.
Ключевыми результатами являются методика создания обучающего датасета на основе реальной проектной документации и ГОСТов, архитектура модели, интегрирующая предметные знания в процесс обучения, а также действующий прототип, позволяющий сократить время активной работы инженера на этапе подготовки данных и высвободить рабочее время для решения содержательных профессиональных задач. Разработанная модель может служить ядром систем интеллектуальной автоматизации инженерных расчетов, повышая общую надежность проектирования транспортных систем.
Conflict of interest
Financing
Библиографическая ссылка
Остроух А.В., Подберёзкин А.А., Пронин Ц.Б., Поспелов П.И., Котов А.А. РАЗРАБОТКА И ОБУЧЕНИЕ ПРЕДМЕТНО-ОРИЕНТИРОВАННОЙ БОЛЬШОЙ ЯЗЫКОВОЙ МОДЕЛИ ДЛЯ АВТОМАТИЗАЦИИ ИЗВЛЕЧЕНИЯ И ВАЛИДАЦИИ ПАРАМЕТРОВ В ЗАДАЧАХ ТРАНСПОРТНОГО МОДЕЛИРОВАНИЯ // Современные наукоемкие технологии. 2026. № 4. С. 317-323;URL: https://top-technologies.ru/en/article/view?id=40767 (дата обращения: 25.06.2026).
DOI: https://doi.org/10.17513/snt.40767