


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
INTELLIGENT SYSTEM FOR ANALYZING AND PREDICTING TEST RESULTS BASED ON MACHINE LEARNING

Введение
Рост объёмов данных, формируемых в процессе тестирования, обусловливает необходимость разработки программных средств, обеспечивающих их автоматизированный анализ и получение воспроизводимых прогностических оценок. В прикладных информационных системах такие средства рассматриваются как программные компоненты, включаемые в контур обработки данных, и предъявляют требования к корректности вычислительных процедур, устойчивости результатов при вариативности входных данных и технологической совместимости с внешними программными модулями [1]. В этом контексте актуальной является разработка моделей, методов и алгоритмов, ориентированных на построение и экспериментальную проверку программных решений для классификации и интерпретации результатов тестирования, а также на оценку качества соответствующих программных систем и их вычислительных модулей.
Одним из результативных подходов к решению указанного класса задач является применение методов машинного обучения для многоклассовой классификации, позволяющей по признаковому описанию отнести наблюдение к одному из заранее заданных классов [2]. Реализация таких подходов в виде программной системы предполагает проектирование архитектуры взаимодействия компонентов, включающей модуль предобработки данных, вычислительный модуль модели и интерфейс интеграции, обеспечивающий доступ к функции прогнозирования в машиночитаемом формате.
Объектом исследования является программная система анализа тестовых данных, включающая программные компоненты подготовки данных, вычислительный модуль модели и интерфейс интеграции с внешними информационными системами. В качестве предмета исследования рассматриваются алгоритмы машинного обучения для многоклассовой классификации, а также архитектурные решения, определяющие взаимодействие программных компонентов и обеспечивающие эксплуатационные характеристики программной системы.
Научная новизна работы состоит в том, что предложена программная реализация многоклассового прогнозирования, ориентированная на использование в составе программной системы. Решение включает предобработку данных, нейросетевую классификацию и формирование машиночитаемого результата. По сравнению с распространёнными подходами, где ограничиваются построением модели и выдачей класса, дополнительно описаны схема проверки качества на отложенной выборке и вариант интеграции в виде веб-сервиса. Это позволяет применять разработку как готовый вычислительный компонент для автоматизированной обработки результатов тестирования.
Разработанная программная система может быть использована в составе цифровых платформ, ориентированных на автоматизированный анализ результатов тестирования и мониторинг качества освоения учебного материала [3]. Реализация в виде сервисного компонента обеспечивает технологическую совместимость с внешними системами и позволяет использовать предложенные алгоритмы в типовых сценариях обработки данных, включая обновление модели и контроль качества на новых выборках.
Цель исследования – разработка программной системы анализа результатов тестирования, обеспечивающей многоклассовую классификацию на основе нейросетевого классификатора и формирование результата в машиночитаемом виде для интеграции с внешними программными компонентами.
Материалы и методы исследования
Для исследования использована анонимизированная выборка результатов тестирования, представленная набором числовых признаков и целевой переменной, задающей класс в задаче многоклассовой классификации [4]. Исходные данные имели табличный формат. Каждая запись соответствовала одному прохождению тестирования. Признаки представляли числовые показатели результата выполнения заданий. Целевая переменная задавала категорию успешности. Идентифицирующие атрибуты в модель не включались. Подготовка данных включала приведение входных данных к единому формату, проверку корректности, обработку пропусков и аномальных значений при их наличии, нормализацию признаков и формирование матрицы признаков и вектора меток. Процедуры предобработки реализованы как воспроизводимый конвейер, что обеспечивает сопоставимость результатов при изменении конфигурации модели [5]. Разделение выборки на обучающую и отложенную подвыборки выполнено по фиксированной схеме, что позволяет корректно сравнивать варианты моделей по единым метрикам качества.
Обучающая выборка формировалась на основе данных Excel-файла, содержащего 11 столбцов. Первые 10 числовых признаков представляли результаты тестирования, 11-й столбец задавал категорию успешности 1, 2 или 3. Объём исходной выборки составил 999 наблюдений. Распределение по классам составило 16,6% для первого класса, 65,9% для второго и 17,5% для третьего класса. В исходных данных выявлены повторяющиеся записи по признакам. Для исключения завышения оценки качества дополнительно сформирована выборка без дубликатов по 10 признакам. Объём выборки после удаления дубликатов составил 633 наблюдения. Для корректной работы функции потерь метки были преобразованы в диапазон 0–2. Разделение данных на обучающую и отложенную подвыборки выполнено в пропорции 80/20 с использованием фиксированного параметра random_state=42. В формате метрик качества использованы accuracy и macro-F1.
В рамках валидационного протокола дополнительно контролировалось отсутствие пересечений одинаковых наблюдений по признакам между обучающей и отложенной подвыборками после удаления дубликатов. Такая проверка направлена на исключение завышения метрик качества при наличии повторяющихся комбинаций признаков и обеспечивает корректность сопоставления моделей при фиксированной схеме разбиения.
Вычислительный модуль прогнозирования реализован в виде нейросетевого классификатора на основе полносвязной архитектуры с вероятностной интерпретацией выходов [6]. Модель реализована в программном виде с использованием средств построения и обучения нейросетевых архитектур. Параметры и режим обучения подбирались с учётом устойчивости оптимизации и обобщающей способности. Для снижения риска переобучения применялись стандартные методы регуляризации и контроль качества на отложенной подвыборке [7].
Развёртывание модели выполнено в составе программной системы, организованной как сервисный компонент, выполняющий предобработку входных данных, инференс модели и формирование результата в машиночитаемом формате для передачи внешним программным модулям [8]. Взаимодействие реализовано через HTTP-интерфейс доступа к функции прогнозирования. Это обеспечивает технологическую совместимость и позволяет включать вычислительный модуль в распределённые сценарии обработки данных.
Результаты исследования и их обсуждение
Разработанная программная система анализа и прогнозирования результатов тестирования реализует сервисно ориентированный вычислительный контур, включающий прием входных данных, выполнение предобработки, инференс модели и выдачу результата во внешние программные компоненты [9]. В качестве вычислительного ядра используется нейросетевой классификатор, обученный на выборке, представленной десятью числовыми признаками и категориальной меткой класса (рис. 1). При эксплуатации вычислительный модуль получает на вход вектор признаков фиксированной длины, формирует вероятностную оценку принадлежности к классам и возвращает структурированный ответ, пригодный для последующей программной обработки, без включения в публикацию фрагментов прикладного кода [10].
Модель прогнозирования реализована в виде полносвязной нейронной сети со входным слоем размерности 10, двумя скрытыми слоями размерности 32 и 16 с функцией активации ReLU и выходным слоем размерности 3 с функцией softmax, обеспечивающей вероятностную интерпретацию выходов в задаче многоклассовой классификации [11]. Обучение проводилось в течение 50 эпох при размере пакета 16 с использованием оптимизатора Adam и функции потерь sparse categorical crossentropy. Оценка качества выполнялась на отложенной подвыборке при разбиении 80/20 с фиксированным параметром random_state=42 на данных, очищенных от дубликатов по признакам. В качестве метрик использованы accuracy и macro-F1.
Качество нейросетевой модели сопоставлялось с базовыми алгоритмами классификации [12]. В сравнительном эксперименте (таблица) приведены значения accuracy и macro-F1 для нейросетевой модели, логистической регрессии, метода опорных векторов и решающего дерева при одинаковой схеме обучения и оценки [13]. Полученные результаты подтверждают работоспособность предложенного решения на данных заданного формата при принятом протоколе валидации. При этом следует учитывать, что нейросетевая модель ориентирована на достижение высоких показателей качества классификации, тогда как интерпретируемость результатов выше у линейных моделей и деревьев решений (рис. 2).

Рис. 1. Архитектура программной системы анализа и прогнозирования результатов тестирования Примечание: составлено авторами по результатам данного исследования
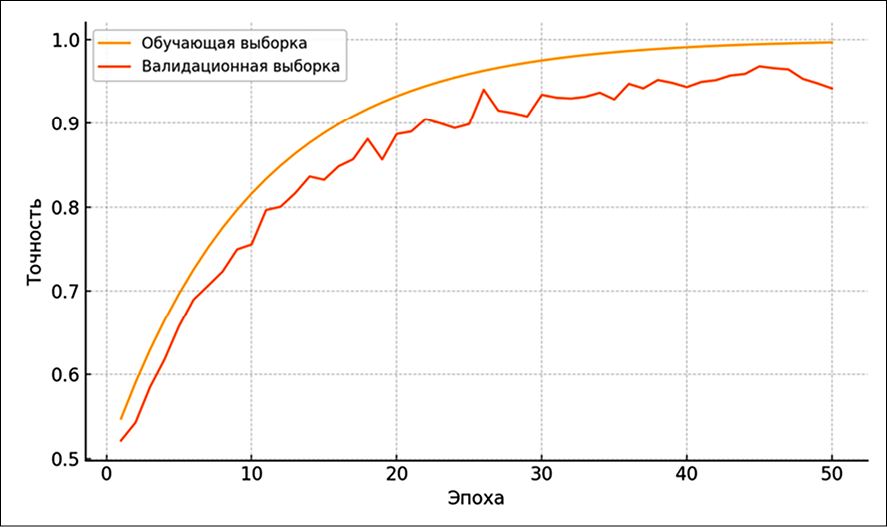
Рис. 2. Динамика точности (accuracy) на валидационной выборке в процессе обучения модели Примечание: составлено авторами по результатам данного исследования
Сравнение качества классификации нейросетевой модели и базовых алгоритмов
|
Модель |
Точность (accuracy), % |
macro-F1 |
|
Логистическая регрессия |
99,21 |
0,9845 |
|
Нейронная сеть |
98,43 |
0,9747 |
|
Метод опорных векторов (SVM, RBF) |
91,34 |
0,8740 |
|
Решающее дерево |
61,42 |
0,5109 |
Примечание: составлено авторами на основе полученных данных в ходе исследования.
Сравнение моделей, представленное в таблице, выполнено при фиксированной схеме разбиения данных и едином наборе метрик, что обеспечивает сопоставимость результатов между алгоритмами. Оценивание проводилось на отложенной подвыборке при одинаковых условиях обучения и тестирования, поэтому различия метрик можно интерпретировать как различия в обобщающей способности моделей в рамках выбранного признакового описания. Использование macro-F1, наряду с accuracy, позволяет корректнее интерпретировать качество при неоднородном распределении классов и снижает риск завышенной оценки за счёт доминирующего класса. Совокупность значений двух метрик рассматривается как подтверждение воспроизводимости экспериментальной проверки при принятом протоколе валидации и как основание для использования вычислительного модуля в сервисном контуре обработки результатов тестирования.
Преимущество предложенного решения состоит в объединении алгоритмической части и программной реализации в рамках единого воспроизводимого сервиса. Реализация предусматривает унифицированный интерфейс доступа, стандартизированное представление результата и возможность интеграции в распределённые программные системы. Формирование результата в машиночитаемом виде позволяет передавать прогноз во внешние программные компоненты без дополнительной интерпретации на стороне потребителя и использовать единый формат ответа при включении модуля в прикладные контуры обработки данных.
Для унификации представления результата в программной системе дополнительно рассчитывается агрегированная оценка успешности как взвешенная сумма вероятностей по классам [14]. В качестве весов используются значения 100, 70 и 30 для трёх категорий, а итоговая оценка округляется до двух знаков. Это позволяет сохранить вероятностную интерпретацию выхода модели и одновременно получить один числовой показатель, который удобно использовать для сортировки результатов, порогового отбора и мониторинга их динамики в программной системе. В общем виде вычисление может быть задано выражением
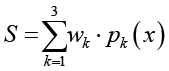 , (1)
, (1)
где pk(x) ‒ вероятность класса k, возвращаемая моделью, а wk ‒ заданный вес класса [15]. Такой способ формализации выхода обеспечивает машиночитаемую передачу результата и упрощает интеграцию модуля прогнозирования в прикладные контуры обработки данных [16]. К ограничениям относятся зависимость качества классификации от полноты и репрезентативности обучающей выборки и необходимость адаптации модели при расширении состава признаков, в том числе при использовании данных смешанных типов.
Заключение
В работе разработана и исследована программная система анализа результатов тестирования, реализующая многоклассовую классификацию на основе нейросетевой модели и предназначенная для автоматизированной обработки табличных данных. Решение охватывает этапы подготовки данных, построения и обучения модели машинного обучения, а также проектирования программной архитектуры с формализованным интерфейсом взаимодействия, обеспечивающим интеграцию вычислительного модуля в прикладные контуры обработки данных.
В качестве вычислительного ядра использован нейросетевой классификатор с вероятностной интерпретацией выходов. Качество оценивалось на отложенной подвыборке при разбиении 80/20 с фиксированным параметром random_state=42 на данных, очищенных от дубликатов по признакам. Экспериментальная проверка показала значения accuracy = 0,984 и macro-F1 = 0,975, что подтверждает работоспособность модели на данных заданного формата при принятом протоколе валидации. Сравнение с базовыми алгоритмами выполнено при одинаковой схеме обучения и оценки и приведено в таблице.
Архитектура программной системы реализована в виде сервисного компонента, включающего модули предобработки данных, инференса модели и формирования результата в машиночитаемом формате. Для унификации представления выхода используется агрегированная оценка успешности, вычисляемая по вероятностям классов, что упрощает передачу результатов между программными компонентами и расширяет возможности дальнейшей автоматизированной обработки. Такой подход позволяет рассматривать разработанную систему как программный модуль, пригодный для повторного использования и сопровождения.
К ограничениям текущей реализации относятся зависимость качества классификации от полноты и репрезентативности обучающей выборки и ориентация на числовые табличные признаки. Перспективными направлениями дальнейших исследований являются расширение набора обрабатываемых типов данных, развитие архитектуры модели и внедрение механизмов мониторинга качества при эксплуатации. Полученные результаты могут быть использованы при проектировании и исследовании программных систем анализа данных на основе методов машинного обучения.
Conflict of interest
Financing
Библиографическая ссылка
Ольховая А.М., Ромашкова О.Н. ИНТЕЛЛЕКТУАЛЬНАЯ СИСТЕМА АНАЛИЗА И ПРОГНОЗИРОВАНИЯ РЕЗУЛЬТАТОВ ТЕСТИРОВАНИЯ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ // Современные наукоемкие технологии. 2026. № 4. С. 98-103;URL: https://top-technologies.ru/en/article/view?id=40734 (дата обращения: 25.06.2026).
DOI: https://doi.org/10.17513/snt.40734