


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
DEVELOPMENT OF A SCALABLE AND RESILIENT ARCHITECTURE FOR A HIGH-LOAD INFORMATION SYSTEM

Введение
В условиях цифровизации экономики и общества интернет-платформы, веб-сервисы и другие сетевые программные решения играют все более значимую роль в предоставлении услуг, обработке информации и организации взаимодействия пользователей. При этом увеличивается и число пользователей таких платформ, и объемы данных, обрабатываемых в цифровой среде. Например, по данным Министерства цифрового развития, связи и массовых коммуникаций, аудитория мирового интернета увеличилась на 98 млн чел., а ежемесячная аудитория российского интернета в 2022 г. составила почти 99 млн чел. [1]. В последние годы также активно развиваются технологии искусственного интеллекта [2]. Указанные тенденции создают дополнительную нагрузку на вычислительные ресурсы серверной инфраструктуры и требуют применения специальных подходов к проектированию программных решений [3]. Для снижения затрат на наращивание серверных мощностей важно обеспечивать рациональное распределение нагрузки и эффективное использование вычислительных ресурсов. Это может быть достигнуто за счет построения архитектуры системы, учитывающей характер и интенсивность решаемых задач.
Современные информационные системы включают в себя большое количество функций, которые реализованы в виде огромного количества страниц (экранов). Это приводит к высокой нагрузке базы данных, у которой ограничено число подключений и выделенных ресурсов. Кроме того, в случае обращения большого количества пользователей к разным страницам создается нагрузка от всех страниц к единой базе данных. В итоге происходит достижение максимального количества запросов и создаются коллизии (блокировки) запросов, которые еще больше усугубляют проблему, провоцируя появление новых запросов. Аналогичная ситуация происходит и с самим приложением, в котором реализованы все функции страниц сразу. В этом случае приложение потребляет большое количество ресурсов и блокируется в ожидании выполнения запросов к базе данных и при выполнении вычислительных задач. Потребление ресурсов оперативной памяти и мощностей процессора будет достаточно высоким, и появится потребность улучшения характеристик аппаратной части информационной системы. Решить проблему можно с помощью внедрения микросервисной архитектуры [4]. Микросервисная архитектура – это такая архитектура, когда функционал информационной системы поделен на различные небольшие приложения (сервисы). В таком случае нагрузка будет распределена между сервисами. При этом большое число обращений к одному из сервисов не будет блокировать работоспособность всей системы в целом. Как правило, пользователи редко нагружают систему одномоментно, и существует коэффициент распределения нагрузки. При этом каждый сервис будет запущен в свое время (пускай и с небольшой разницей в доли секунды друг от друга), и в промежутки времени будет выполнена часть работы каждого сервиса, что сделает нагрузку более равномерной. Однако важно, чтобы данные были согласованы между собой, поэтому важно предусмотреть интеграционные шлюзы [5].
Микросервисная архитектура рассматривается как один из базовых подходов к проектированию масштабируемых информационных систем. В работе Microservices Architecture in Large-Scale Distributed Systems: Performance and Efficiency Gains [6] отмечается, что ее применение способствует созданию масштабируемых сервисов, разработка и сопровождение которых могут осуществляться независимыми командами. Аналогичная позиция представлена и в работе Secure and Scalable Microservices Architecture: Principles, Benefits, and Challenges [7].
Одним из ключевых узких мест высоконагруженных систем остается реляционная СУБД. В работе [8] отмечается, что даже кластеризация PostgreSQL не всегда устраняет проблему исчерпания пула соединений при резком росте активности. Использование промежуточных пулов соединений, например PGBouncer, позволяет снизить накладные расходы, однако, как показывают исследования [9, 10], без кэширования часто запрашиваемых данных этого подхода недостаточно. Системы хранения данных в оперативной памяти, такие как Redis и Memcached, широко применяются для кэширования. Кокоулин и соавт. [11] демонстрируют их эффективность в сценариях обработки больших данных, однако вопросы их интеграции с ИИ-модулями, где требуется контроль актуальности данных, остаются недостаточно изученными.
Для разгрузки основного потока выполнения рекомендуется использовать брокеры сообщений. Скрыпников [12] и Riaset et. al. [13] подтверждают, что RabbitMQ и Kafka позволяют организовать надежную асинхронную обработку, особенно в распределенных системах. Однако большинство работ не учитывают приоритизацию задач: например, пользовательский запрос должен обрабатываться быстрее фонового аналитического отчета. Вопрос динамического управления приоритетами в очередях при наличии ИИ-нагрузок остается слабо изученным.
С развитием систем контейнеризации платформы Kubernetes и Docker стали стандартом для развертывания микросервисов. Marella [14] проводит сравнительный анализ этих решений, но не рассматривает их применение в связке со специализированными вычислительными устройствами (GPU, графический процессор/TPU, тензорный процессор). Muzumdar исследует применение Docker для реализации систем сложных облачных вычислений, но также не изучает интеграцию со специальными вычислительными устройствами [15]. М. А. Жижченко [16] и К. И. Никишин [17] акцентируют внимание на балансировке нагрузки, однако их модели не адаптированы под неравномерное потребление ресурсов ИИ-модулями.
Изучив существующие научные работы, связанные с высоконагруженными информационными системами, можно сделать вывод о необходимости разработки архитектуры информационной системы, охватывающей все аспекты, влияющие на производительность и масштабирование.
Цель исследования – разработать и обосновать масштабируемую архитектуру программного решения для высоконагруженной среды, обеспечивающую эффективное распределение вычислительных ресурсов, устойчивость системы при росте числа одновременных подключений и интенсивной обработке данных, а также оценить ее эффективность с помощью нагрузочного тестирования.
Материалы и методы исследования
В рамках проведенного исследования были изучены недостатки и преимущества распространенных архитектур высоконагруженных приложений и разработана собственная архитектура информационной системы, ориентированная на эффективную работу при высокой нагрузке, включая задачи, связанные с обработкой данных и применением моделей искусственного интеллекта. Объектом исследования являются информационные системы, функционирующие под высокой нагрузкой, включая системы с модулями искусственного интеллекта. Предметом исследования является архитектура информационной системы, обеспечивающая эффективное распределение вычислительных ресурсов и устойчивость к высокой нагрузке.
Методология включала проектирование архитектурных компонентов, выбор технологического стека, реализацию системы и проведение нагрузочного тестирования.
При разработке архитектуры были использованы следующие подходы:
– микросервисная декомпозиция;
– разделение баз данных и управление соединениями;
– внедрение высокопроизводительной системы хранения для часто запрашиваемых данных;
– асинхронная обработка через очереди сообщений;
– горизонтальное масштабирование и оркестрация;
– использование специализированных вычислительных ресурсов для ИИ-задач.
Для оценки эффективности предложенной архитектуры было проведено сравнительное нагрузочное тестирование «до» и «после» ее внедрения. Тестирование выполнено с использованием инструмента Apache JMeter 5.6, который имитировал поведение реальных пользователей. Было смоделировано от 10 до 200 одновременных WebSocket-подключений для получения данных о проекте. Продолжительность каждого тестового сценария – 5 мин. Измеряемые метрики при тестировании:
– потребление оперативной памяти (ОЗУ – оперативное запоминающее устройство, в Гб);
– загрузка центрального процессора по каждому ядру (%).
Результаты исследования и их обсуждение
Архитектура с использованием микросервисов представлена на рис. 1.
В качестве примера, когда может быть актуальна данная архитектура, можно привести работу таких сервисов, как личный кабинет информационной системы и составление статистики. Как правило, аналитические задачи выполняются достаточно долго, а задачи для отображения информации в личном кабинете, наоборот, быстро. При использовании микросервисов составление статистики не будет блокировать работу личного кабинета во время выполнения.
Однако данная архитектура не поможет в случае создания большого количества запросов от одного сервиса. Если при этом задействована база данных, то возникнет ошибка с превышением числа запросов. Для решения такой проблемы целесообразно применять программы управления пулом соединений к базе данных [18].
При выполнении запросов в обычной ситуации открывается соединение от каждого клиента и держится до тех пор, пока работа с базой данных не прекратится. Если имеет место большое количество клиентов, осуществляющих большое число запросов длительное время, количество активных соединений неуклонно растет и доходит до максимального значения. После превышения максимального значения возникают коллизии и блокировка работы базы данных.
Программы управления соединениями позволяют переиспользовать соединения для каждого запроса и даже клиента, ограничивают максимальное количество соединений и управляют временем ожидания, закрывают неиспользуемые соединения и обрабатывают ошибки [8].
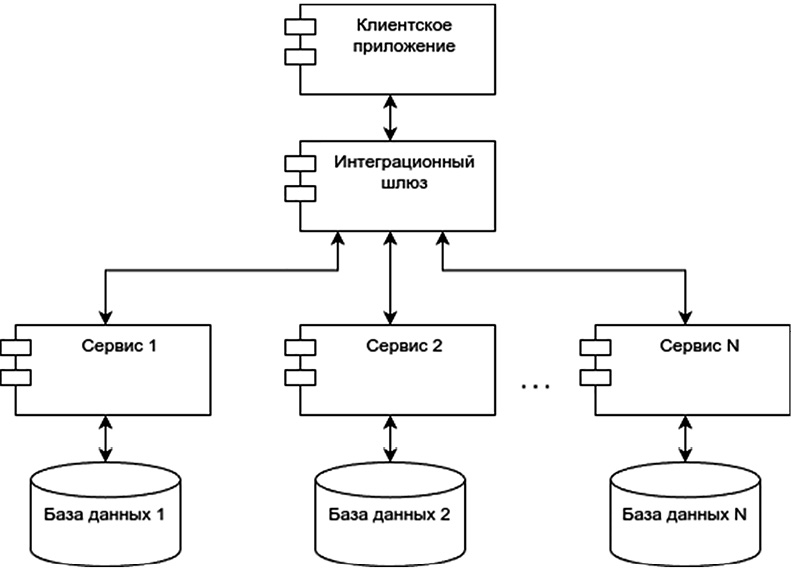
Рис. 1. Микросервисная архитектура Примечание: составлен авторами по результатам данного исследования
Примерами таких программ может выступить PGBouncer для PostgreSQL или SQLAlchemy Connection Pool для приложений, реализованных с помощью языка программирования Python [9].
Снизить число подключений к базе данных также могут высокопроизводительные системы хранения данных, не относящиеся к реляционным. Такие системы хранят информацию в оперативной памяти и позволяют снизить число одинаковых запросов к реляционной базе данных с помощью извлечения недавно полученной информации по принципу кэширования. То есть клиент создает обращение к базе данных, данные сохраняются в оперативную память, и при запросе аналогичной информации в течение короткого времени от другого клиента или повторном запросе от того же клиента извлекаются данные из оперативной памяти без осуществления запросов к основной базе данных. К таким системам можно отнести популярные на рынке программы Redis или Memcached. Архитектура с применением высокопроизводительной системы хранения данных и программой управления соединениями приведена на рис. 2.
Избежать коллизий при работе с базой данных или чрезмерной нагрузки на один из сервисов можно также с помощью систем очередей и брокеров сообщений. Такие системы выстраивают обращения от клиентского приложения или интеграционного шлюза в единую очередь и с учетом приоритета выполнения задач инициализируют выполнение той или иной части программы путем отправки информационных сообщений. К таким программным средствам можно отнести системы RabbitMQ и Kafka.
Высокая вычислительная нагрузка возникает при реализации задач, связанных с интенсивными математическими вычислениями, включая обработку данных, машинное обучение и нейросетевые алгоритмы.
В случае сложных вычислений может возникать повышенная нагрузка на вычислительные мощности сервера, а именно на нагрузку процессора, оперативной памяти и устройство хранения данных, например ПЗУ SSD (постоянное запоминающее устройство твердотельного накопителя). Для того чтобы система функционировала стабильно, реализуют следующие мероприятия в архитектуре:
1. Декомпозиция информационной системы. Выделяют блоки сбора данных, предобработки, обучения модели. Когда блоки разделены на отдельные программные элементы, они могут выполняться независимо друг от друга в разных потоках, тем самым равномерно нагружая систему.
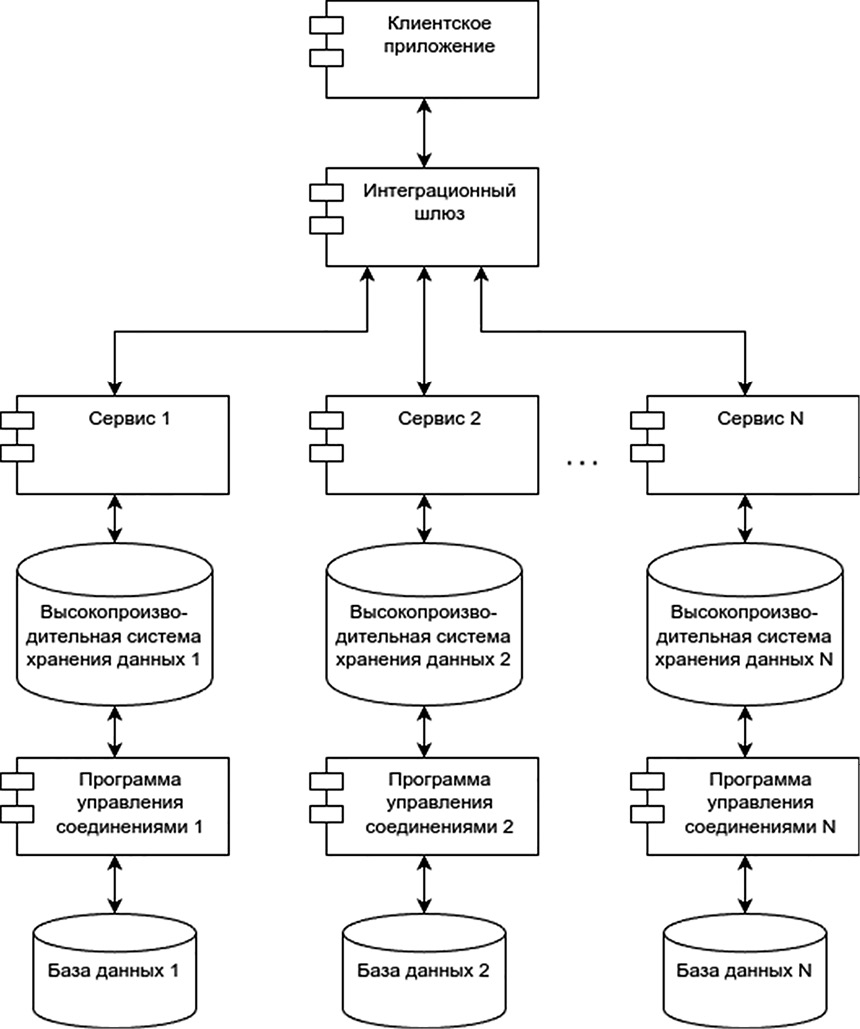
Рис. 2. Архитектура с внедрением высокопроизводительной системы хранения данных и программы управления соединениями Примечание: составлен авторами по результатам данного исследования
2. Использование систем оркестрации задач и систем балансировки нагрузки. Как правило, отдельные блоки программ выполняются в независимых контейнерах, например Docker. Для того, чтобы Docker-контейнеры упорядочить и равномерно распределить нагрузку между ними, используют системы оркестрации, например Kubernetes или Docker Swarm. К системам балансировки нагрузки можно отнести NGINX, HAProxy или Traefik. Эти программы позволяют запускать программы на наименее загруженных узлах сервера.
3. Применение кластеров GPU и TPU, а также распределенных вычислительных платформ. GPU кластеры изначально были разработаны для обработки графики, но они нашли свое применение в сложных вычислениях машинного обучения [19].
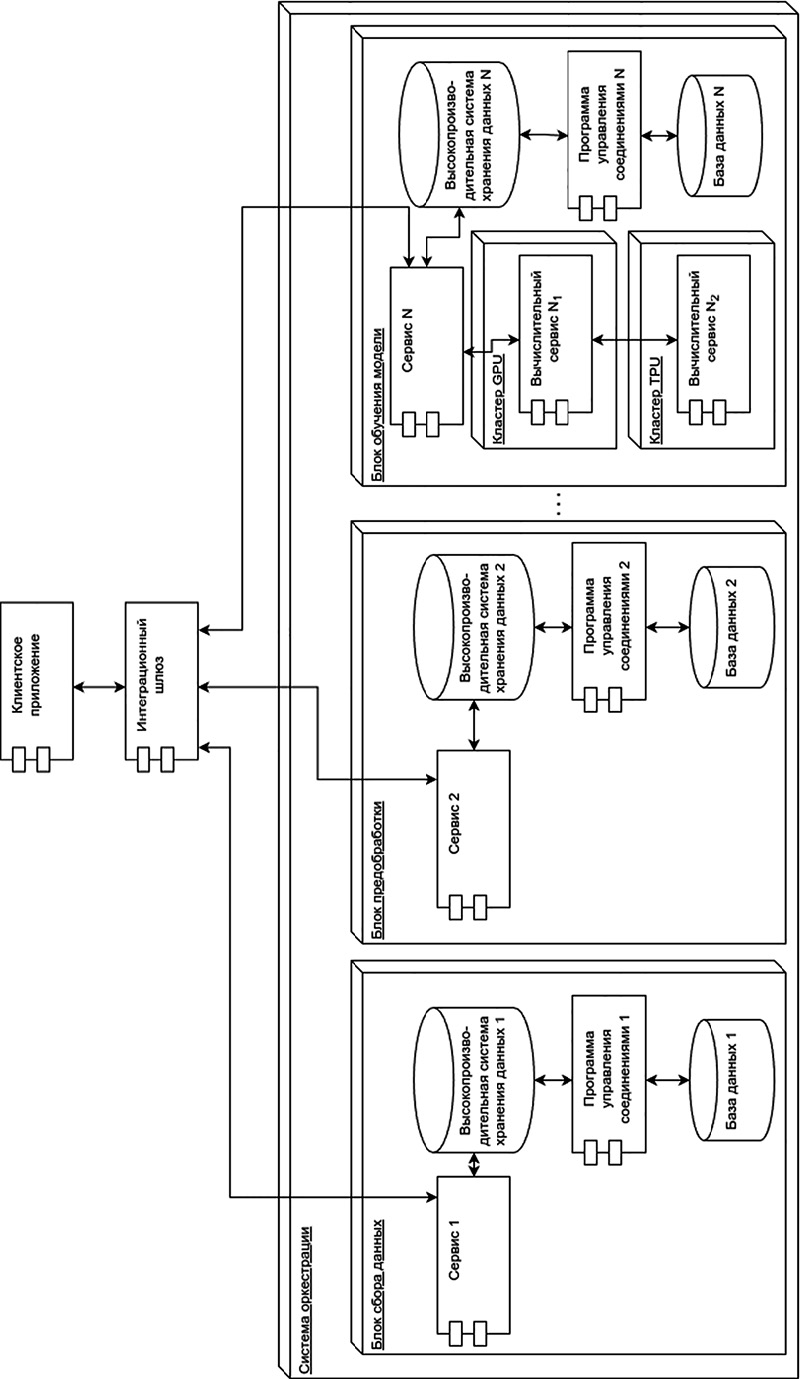
Рис. 3. Оптимальная архитектура информационной системы Примечание: составлен авторами по результатам данного исследования
GPU кластеры позволяют обрабатывать множество операций одновременно за счет большого числа ядер и обеспечивают высокую производительность матричных операций, которые используются при работе с нейронными сетями. TPU – интегральные схемы, предназначенные исключительно для задач машинного обучения. Распределенные вычислительные платформы – это программы, которые определенным образом делят вычислительные задачи между разными видами процессоров, кластерами и схемами. Так, задачи, требующие большой частоты, но малого количества потоков, направляются на центральный процессор CPU, операции машинного обучения, требующие большого числа потоков – на кластеры GPU и схемы TPU [20].
4. Использование систем очередей или брокеров сообщений с целью горизонтального масштабирования. Применение систем очередей позволяет разделить программу на сервисы и выстраивать очередность процессов, чтобы не происходило коллизий и ошибок во время параллельных вычислений. Брокеры принимают сообщения от разных сервисов, определяют очередность и инициируют выполнение задач в правильном порядке таким образом, чтобы не было дублирования данных.
5. Внедрение фреймворков для распределенного вычисления и обучения. Применение систем распределенных вычислений и обучения позволяет обрабатывать входные данные и передавать их на обучение, разделяя на части и распределяя между вычислительными потоками и кластерами, тем самым равномерно распределяя нагрузку и ускоряя вычисления. В качестве широко используемых систем можно отметить Apache Spark для обработки больших объемов данных и TensorFlow для построения и распределенного обучения моделей искусственного интеллекта (машинного обучения) [21].
Архитектура информационной системы с учетом описанных мероприятий представлена на рис. 3.
В ходе проведения исследования в рамках НИОКТР № 123122100002-0 были получены оценки потребления ресурсов вычислительного сервера. Основные задачи сервера: поддерживать большое количество одновременных подключений Websocket, осуществлять математические операции и задачи, связанные с обработкой текста, при помощи искусственного интеллекта. Нагрузочное тестирование производилось с помощью специализированного программного обеспечения Jmeter. Jmeter – это программа, позволяющая нагружать удаленный вычислительный сервер с помощью создания заданного количества подключений и запросов [22].
До измерений потребление оперативной памяти в пиковой нагрузке 200 одновременных подключений в секунду было равно почти 8 Гб, а центральный процессор (ЦП) был нагружен неравномерно: на 1 ядре нагрузка была 96 %, а на остальных 11 ядрах – в пределах 5 %. После внедрения архитектуры было получено равномерное распределение нагрузки процессора и снижение потребления оперативной памяти.
Результаты нагрузки серверных мощностей до внедрения разработанной архитектуры представлены в табл. 1.
Результаты нагрузки серверных мощностей после внедрения архитектуры отображены в табл. 2.
Наглядное сравнение потребления нагрузки можно увидеть на графиках (рис. 4 и 5).
Таблица 1
Результаты нагрузки серверных мощностей до внедрения разработанной архитектуры
|
Подключения |
10 |
100 |
150 |
200 |
|
ОЗУ |
1,23 |
5,67 |
7,31 |
7,92 |
|
ЦП1 |
32 % |
75 % |
89 % |
96 % |
|
ЦП2 |
1 % |
3 % |
4 % |
5 % |
|
ЦП3 |
2 % |
2 % |
3 % |
4 % |
|
ЦП4 |
1 % |
2 % |
3 % |
3 % |
|
ЦП5 |
1 % |
2 % |
2 % |
5 % |
|
ЦП6 |
1 % |
2 % |
2 % |
4 % |
|
ЦП7 |
2 % |
3 % |
3 % |
3 % |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Таблица 2
Результаты нагрузки серверных мощностей после внедрения разработанной архитектуры
|
Подключения |
10 |
100 |
150 |
200 |
|
ОЗУ |
0,89 |
2,78 |
3,56 |
4,11 |
|
ЦП1 |
8 % |
20 % |
32 % |
43 % |
|
ЦП2 |
7 % |
21 % |
30 % |
42 % |
|
ЦП3 |
8 % |
22 % |
32 % |
43 % |
|
ЦП4 |
7 % |
20 % |
31 % |
40 % |
|
ЦП5 |
8 % |
20 % |
32 % |
43 % |
|
ЦП6 |
7 % |
23 % |
31 % |
41 % |
|
ЦП7 |
6 % |
20 % |
32 % |
43 % |
|
ЦП8 |
7 % |
19 % |
31 % |
40 % |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
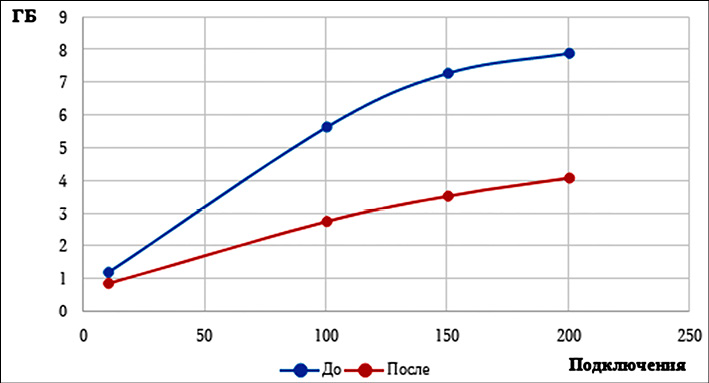
Рис. 4. Потребление оперативной памяти до и после внедрения разработанной архитектуры Примечание: составлен авторами по результатам данного исследования
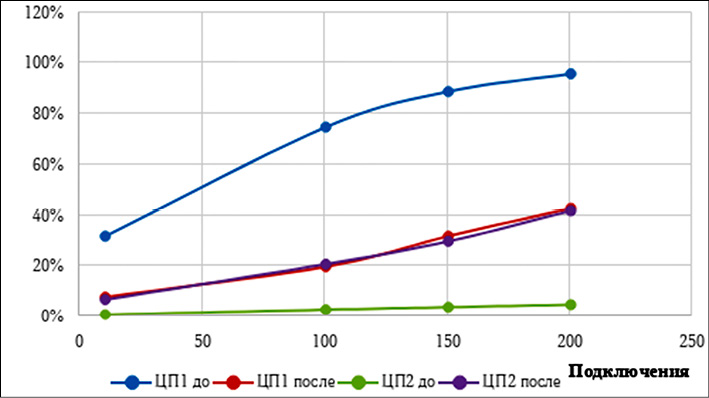
Рис. 5. Распределение нагрузки первого и второго ядер процессора до и после внедрения разработанной архитектуры Примечание: составлен авторами по результатам данного исследования
Поскольку ЦП2–ЦП8 имеют примерно равную нагрузку до и после внедрения архитектуры, на графиках было отражено только второе ядро процессора. Это обеспечивает большую наглядность и не искажает восприятие ситуации. На графиках распределения можно отметить, что оперативная память вычислительного сервера до внедрения разработанной архитектуры достигает полной загрузки в 8 Гб при 200 активных подключениях, в то же время после внедрения архитектуры потребление ОЗУ сократилось почти вдвое. До внедрения разработанной архитектуры был заметен перекос нагрузки на первое ядро центрального процессора, в то время как остальные ядра оставались недозагруженными. Нагрузка на первое ядро достигала почти 100 %. Как видно из графика, после внедрения архитектуры распределение стало равномерным и составило примерно 40 %. Исходя из полученных результатов можно сделать вывод, что получено снижение общей нагрузки почти вдвое, что позволяет увеличить максимальное число подключений без увеличения мощности аппаратной части информационной системы.
Заключение
В рамках исследования проанализированы основные проблемы, возникающие при эксплуатации информационных систем в условиях большого числа одновременных соединений, высокой интенсивности операций, выполнения сложных вычислительных задач и обработки значительных объемов данных. Также изучены архитектурные подходы, позволяющие снизить риски, обусловленные ростом нагрузки. По результатам исследования разработана архитектура информационной системы, оптимизированная для функционирования в условиях высокой нагрузки на вычислительные ресурсы и применения технологий искусственного интеллекта.
Разработанная архитектура была апробирована на действующей веб-платформе, после чего проведено комплексное нагрузочное тестирование. Результаты тестирования показали, что ее внедрение обеспечивает более эффективное использование аппаратных ресурсов: объем потребляемой оперативной памяти снизился почти на 50 %, а вычислительная нагрузка на центральный процессор стала распределяться более сбалансированно между всеми доступными ядрами и вычислительными модулями. Достигнутый эффект способствовал снижению вероятности перегрузки отдельных компонентов и повышению производительности и устойчивости системы при высокой нагрузке.
Практическая значимость исследования состоит в возможности применения разработанной архитектуры при создании высоконагруженных информационных систем, обрабатывающих большие объемы данных и множество одновременных запросов, в том числе интеллектуальных аналитических систем с использованием искусственного интеллекта и машинного обучения. Архитектура может внедряться как полностью, так и поэтапно, в зависимости от уровня зрелости системы и решаемых задач. Перспективы дальнейших исследований связаны с учетом различных подходов к хранению данных в специализированных базах данных и с адаптацией архитектурных решений к развитию технологий анализа и обработки информации.
Conflict of interest
Financing
Библиографическая ссылка
Горшков О.В., Мингалева Ж.А. РАЗРАБОТКА МАСШТАБИРУЕМОЙ И УСТОЙЧИВОЙ АРХИТЕКТУРЫ ВЫСОКОНАГРУЖЕННОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ // Современные наукоемкие технологии. 2026. № 4. С. 56-65;URL: https://top-technologies.ru/en/article/view?id=40729 (дата обращения: 25.06.2026).
DOI: https://doi.org/10.17513/snt.40729