


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
Clustering algorithms for processing spatially linked statistical data in the task of managing user support for multifunctional centers

Введение
Многофункциональные центры (МФЦ) являются бюджетными учреждениями, обеспечивающими предоставление государственных и муниципальных услуг населению. Часть услуг предоставляется в электронном виде через специализированные интернет-порталы [1]. В связи с тем, что не все граждане располагают собственными техническими средствами и доступом к интернету, в офисах МФЦ организованы рабочие места с доступом к необходимым информационным ресурсам и поддержкой со стороны сотрудников. В рамках настоящей работы система пользовательского сопровождения МФЦ рассматривается как организационная система, функционирование которой опирается на анализ статистических данных обращений.
Использование таких рабочих мест требует формирования отчетности о фактически оказанных услугах. Данные отчетности используются как информационная основа управления нагрузкой рабочих мест и регламентацией процессов сопровождения. Для автоматизации сбора статистических данных на рабочих местах применяется браузерное расширение, фиксирующее активность пользователя в ходе сессии [2], включая URL-адреса и заголовки посещенных страниц, а также пространственную привязку данных, определяемую рабочим местом и офисом МФЦ. Объем собираемых данных значителен и содержит большое количество нерелевантных записей, не относящихся непосредственно к получению услуг. В рамках исследования под пространственной привязкой понимается связь каждой пользовательской сессии с конкретным рабочим местом и подразделением МФЦ, без использования географических координат. Пространственная привязка данных задает организационно-структурный контекст формирования обращений и позволяет учитывать различия между рабочими местами и подразделениями МФЦ. В связи с этим возникает задача автоматического выделения и группировки интернет-ссылок, соответствующих страницам сервисов государственных услуг [3]. В данной статье рассматривается разработка алгоритма группировки часто посещаемых страниц на платформах государственных организаций на основе методов кластеризации и обработки текстовых данных.
Цель исследования – разработка алгоритма обработки интернет-адресов, посещенных пользователями государственных сервисов, на основе средств кластеризации данных для идентификации фактов получения услуг и последующей статистической обработки.
Материалы и методы исследования
В настоящее время автоматизация анализа пользовательской активности реализуется преимущественно на основе перебора данных и фильтрации с применением регулярных выражений. Серверный обработчик принимает данные сессий и формирует массив посещенных веб-страниц, который затем очищается от нерелевантных записей. Фильтрация выполняется с использованием справочников ресурсов государственных и муниципальных услуг и характерных фрагментов URL-адресов страниц оказания услуг [4]. Формирование таких справочников требует предварительного ручного анализа необработанных данных активности, после чего возможна их программная обработка [5, 6]. Данный подход обладает существенными ограничениями. Его настройка связана с высокими трудозатратами, а влияние человеческого фактора приводит к неполному учету страниц услуг и искажению итоговой статистики, что негативно сказывается на качестве данных, используемых для управленческих решений [7]. Применение нейросетевых методов в данной задаче также затруднено, поскольку состав и структура сервисов существенно различаются между регионами, что осложняет формирование устойчивых и интерпретируемых кластеров [8, 9].
Фильтрация ссылок по различным сервисам может быть реализована с использованием алгоритма Кнута – Морриса – Пратта (КМП), однако данный подход требует ручного задания строгих критериев схожести и шаблонов поиска в базе URL-адресов посещений сайтов государственных услуг. Вся собранная информация хранится в файлах JSON в строковой форме, что значительно упрощает процесс обработки. Работать с записями активности можно как с простыми строками, но для более подробного анализа стоит учитывать не только строки, в которых содержатся ссылки страниц, но и строки заголовков.
Первым этапом построения кластеров являлось определение матрицы степеней сходства строк, выраженной в метрике расстояния Левенштейна [10]. Расстояние между каждой парой строк вычислялось с использованием метода Вагнера – Фишера, основанного на построении матрицы, размерность которой определяется длинами сравниваемых строк, и поэлементном заполнении на основе рекуррентной формулы [11]. В результате формировалась матрица, элементы которой отражают минимальное количество операций редактирования, необходимых для преобразования одной строки в другую. Значение в правой нижней ячейке матрицы соответствует общему числу требуемых преобразований и представляет собой искомое расстояние Левенштейна. В данном случае строки URL-адресов интерпретируются как формализованные описания событий обращений, а расстояние Левенштейна – как мера их сходства.
Для оценки эффективности выбранного подхода был проведен сравнительный анализ алгоритма Левенштейна и классического алгоритма КМП, который предназначен для точного поиска подстроки в строке и показывает наилучшие результаты при наличии заранее известных шаблонов, что характерно для задач синтаксического поиска, но не для анализа вариативных URL-адресов. Он оперирует бинарным результатом – совпадение найдено или нет, и не позволяет оценить степень близости строк. В отличие от КМП, алгоритм Левенштейна обеспечивает метрическую оценку различий между строками, определяя минимальное количество операций редактирования, необходимых для их совпадения. Это делает его особенно эффективным при работе с динамическими адресами, содержащими параметры сеансов, идентификаторы пользователей и временные метки.
В экспериментальной части сравнение показало, что КМП корректно обрабатывает не более 10–15 % записей, совпадающих дословно, тогда как Левенштейн позволяет формировать непрерывное пространство расстояний и использовать его для построения кластеров по смысловой близости [12]. Таким образом, выбор метрики Левенштейна оправдан способностью учитывать частичные совпадения и вариативность структуры URL, что делает ее базовым инструментом для последующего применения иерархической кластеризации методом Уорда. Минимизация внутрикластерной дисперсии при использовании метода Уорда позволяет формировать однородные классы обращений, что повышает пригодность результатов для задач управления пользовательским сопровождением. С целью ускорения расчетов использовали готовую библиотеку Python Strsimpy для определения расстояния между строками и в процессе построения кластеров.
Решение по выбору наиболее подходящего алгоритма может быть затруднительным, однако можно обратиться к опыту схожих исследований, работающих с анализом строк [13]. Алгоритм КМП использует шаблон подстроки для поиска по строке, что заранее сделать затруднительно, потому что на сайтах разных государственных организаций сервис реализован по разным ссылкам. На первом этапе нужно формировать кластеры по подобным ссылкам URL посещенных сервисов и далее уменьшать в следующем поиске базу, выделяя только узлы соответствующих сервисов. По конечным данным можно уже получить статистику сформированных обращений. Самым популярным из методов вычисления дистанции между двумя строками является расстояние Левенштейна. В данной работе выбор остановился на методе Уорда, так как он имеет меньшую восприимчивость к шуму и выбросам и эффективен даже на небольших выборках [14, 15].
Предлагаемый алгоритм кластеризации включает следующие этапы:
1) формирование массива URL-адресов и заголовков посещенных страниц по пользовательским сессиям;
2) вычисление парных расстояний между строками с использованием метрики Левенштейна и формирование матрицы расстояний;
3) преобразование матрицы расстояний к формату, совместимому с иерархическими методами кластеризации;
4) применение метода Уорда для построения дендрограммы и последовательного объединения объектов в кластеры;
5) выбор порога отсечения по дендрограмме и определение числа кластеров;
6) интерпретация полученных кластеров как типовых классов пользовательских обращений и исключение кластеров, соответствующих нерелевантным переходам.
Сравнение с альтернативными подходами показало, что использование классических методов разбиения, таких как k-means, а также других агломеративных критериев (например, по ближайшему соседу или полному связыванию) менее эффективно в рассматриваемой задаче. Методы разбиения требуют заранее задавать число кластеров и чувствительны к шумовым и единичным записям, характерным для пользовательских сессий. Альтернативные критерии агломерации демонстрируют более высокую чувствительность к выбросам и приводят к менее интерпретируемой структуре объединений. В отличие от них, сочетание метрики Левенштейна и метода Уорда обеспечивает компактные и устойчивые к шуму кластеры, которые удобно интерпретировать как типовые классы обращений.
Результаты исследования и их обсуждение
С помощью функции levenshtein() были вычислены редакционные расстояния в массиве статистических данных о ссылках на посещенные страницы, сформированных в различных пространственных контекстах пользовательского сопровождения. На основании полученных значений был сформирован вектор расстояний. Для дальнейшей работы с данными вектор был преобразован в квадратную матрицу. К полученной матрице был применен метод Уорда для построения иерархического дерева. Расстояние R между кластерами U и V вычисляется как прирост суммы квадратов расстояний от точек до центроидов кластеров при объединении этих кластеров.
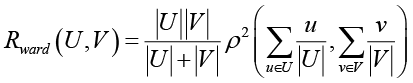 ,
,
где U, V – объединяемые кластеры;
|U|, |V| – количество объектов в кластерах U, V;
u, v – объекты, принадлежащие кластерам U, V;
ρ2 – квадрат расстояния между центроидами кластеров.
Сформированные кластеры могут рассматриваться как типовые классы пользовательских обращений, используемые при агрегировании данных и формировании управленческой отчетности.
На каждом шаге иерархического алгоритма кластеризации с использованием метода Уорда выполняется процедура выбора двух кластеров, объединение которых минимально увеличивает значение целевой функции. В качестве целевой функции используется общая внутрикластерная сумма квадратов – показатель, отражающий степень компактности кластеров и величину разброса объектов внутри них. Для каждой пары кластеров U и V вычисляется величина увеличения этой суммы квадратов при гипотетическом слиянии кластеров. Эта величина показывает, насколько возрастет суммарная дисперсия в данных, если два кластера будут объединены. Фактически это прирост ошибки кластеризации, поэтому алгоритм стремится выбирать пару кластеров с минимальным значением R (U, V).
Далее процесс выглядит так:
1. На начальном шаге каждый объект считается отдельным кластером, центроид совпадает с объектом, внутрикластерная дисперсия равна нулю.
2. Для всех пар кластеров рассчитывается значение прироста внутрикластерной суммы квадратов при их объединении. Выбирается пара с минимальным приростом дисперсии, то есть наиболее «похожих» или «близких» с точки зрения критерия Уорда кластеров.
3. Кластеры объединяются, вычисляется новый центроид объединенного кластера. Матрица расстояний пересчитывается, так как расстояния до нового кластера уже не равны расстояниям до исходных двух.
4. Шаги 2–3 повторяются до тех пор, пока все объекты не будут объединены в единый кластер.
Метод Уорда формирует кластеры таким образом, чтобы внутри каждого кластерного объединения сохранялась максимальная однородность. Алгоритм избегает объединения групп, которое привело бы к заметному росту внутрикластерной дисперсии, и, наоборот, последовательно соединяет наиболее компактные и близко расположенные группы данных. В результате получается иерархическое дерево (дендрограмма), уровни которого отражают моменты объединения кластеров и величину увеличения дисперсии, что делает структуру кластеризации легко интерпретируемой. С помощью функции dendrogram() на основании полученных данных было построено дерево, отображающее взаимное расположение страниц и групп посещенных страниц в зависимости от меры сходства между URL-адресами. Дерево, полученное при анализе данных о 300 записях из 15 различных сессий, указано на рисунке.
На вертикальной оси дендрограммы указана дистанция между кластерами. Таким образом, чем ближе к вершине, тем больше расстояние и менее схожи между собой посещенные страницы. На основании этого рисунка можно выбрать количество кластеров, на которое разумно поделить данные. Если анализировать ссылки с одного из наиболее популярных порталов для получения услуг, можно отметить что расстояние между различными посещенными URL-адресами не будет превышать 100–200 замен. В рамках одного ресурса наблюдается такая закономерность, что большая часть страниц имеет между собой минимальные различия. Исключением может стать обращение к адресу на ресурсе, в ссылке посещения которого может отобразиться достаточно длинный get-параметр, однако по различным данным средняя длина URL адреса ограничивается 75–100 символами.
Получается, что в основании дендрограммы, в пределах значений до 100 кластеры еще не будут в полной мере отражать разбиение по различным ресурсам и в разных кластерах с высокой вероятностью могут встретиться обращения к одному и тому же порталу. На основании рисунка можно выбрать количество кластеров, на которое разумно поделить данные.
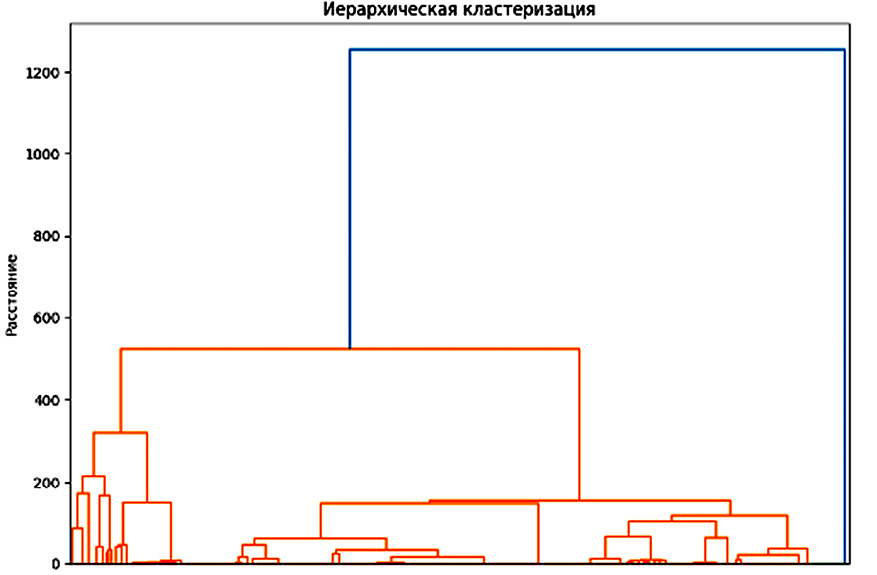
Дендрограмма разделения по кластерам Примечание: составлен авторами по результатам данного исследования
В результате анализа получившихся кластеров удалось выделить основные группы адресов, по которым обращались пользователи, а с ними и определить посещаемые ресурсы. Отдельную большую группу образовали страницы портала регионального многофункционального центра, основная часть которых представляет собой страницы начала сессии и навигации. Далее в отдельную группу попали преимущественно все страницы домена «Госуслуги», включая авторизацию, получение услуг и просмотр информационных страниц. В отдельную группу попали страницы просмотра заявлений на портале «Госуслуги», по причине длинной строки GET-параметров, что значительно увеличило расстояние строк от других адресов того же домена. Оставшаяся группа сформировалась вокруг менее значимых для исследования адресов, на которых находился пользователь: промежуточные страницы открытия новой вкладки для перехода на целевой адрес.
В отличие от стандартных подходов к кластеризации строковых данных, предложенный алгоритм учитывает не только содержательное сходство URL-адресов, но и их пространственную привязку к рабочим местам и офисам МФЦ. При использовании классических методов разбиения и агломеративных алгоритмов пространственная компонента, как правило, либо игнорируется, либо учитывается отдельно от процесса кластеризации, что затрудняет интерпретацию результатов в организационном контексте. В рассматриваемой методике пространственная привязка выступает дополнительным измерением анализа: кластеры URL-адресов сопоставляются с конкретными рабочими местами и подразделениями, что позволяет выявлять типовые классы обращений не только по структуре ссылок, но и по их распределению в системе пользовательского сопровождения. Это обеспечивает более полное представление о нагрузке на инфраструктуру МФЦ и делает результаты кластеризации непосредственно пригодными для решения задач управления пользовательским сопровождением.
Заключение
Таким образом, применение алгоритмов кластеризации позволяет существенно сократить трудоемкость анализа больших массивов данных пользовательской активности за счет автоматизированного выявления и группировки однородных обращений. Использование кластерного разбиения обеспечивает возможность формирования типовых классов обращений и исключения из анализа нерелевантных переходов, не связанных с фактическим получением услуг, что повышает качество подготавливаемой управленческой информации. Повторное применение алгоритмов кластеризации к данным выделенных кластеров позволяет проводить более детальный анализ обращений внутри отдельных ресурсов и выявлять закономерности, характеризующие процессы получения услуг. В рамках проведенного исследования это дало возможность идентифицировать группы обращений, относящиеся к порталу государственных услуг, и отделить их от вспомогательной пользовательской активности. Учет пространственной привязки статистических данных, определяемой рабочими местами и подразделениями МФЦ, формирует основу для анализа распределения обращений в организационной системе пользовательского сопровождения. Полученные результаты могут быть использованы для информационного обеспечения задач управления, включая оценку нагрузки рабочих мест, анализ структуры обращений и поддержку принятия решений по организации процессов пользовательского сопровождения без изменения базовой методики кластеризации.
Conflict of interest
Financing
Библиографическая ссылка
Егунова А.И., Сидоров Д.П., Егунова О.И., Ямашкин С.А., Вечканова Ю.С. Алгоритмы кластеризации для обработки пространственно привязанных статистических данных в задаче управления пользовательским сопровождением многофункциональных центров // Современные наукоемкие технологии. 2026. № 2. С. 29-34;URL: https://top-technologies.ru/en/article/view?id=40667 (дата обращения: 29.07.2026).
DOI: https://doi.org/10.17513/snt.40667