


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
Identifying textual drivers of brand audience engagement in social media based on a graph-regularized approach

Введение
Социальные медиа стали доминирующим каналом коммуникации между брендами и широкой аудиторией. Эффективность этой коммуникации измеряется вовлечённостью – метрикой, отражающей активную реакцию пользователей. Возникает сложная обратная задача, заключающаяся в определении текстовых компонент поста, которые вызывают рост вовлечённости. Актуальность вопроса обусловлена ограничениями существующих методов. Классические инструменты анализа текста развивались в парадигме тематического моделирования и классификации контента, тогда как выявление причинно-следственных эффектов текста на внешнюю реакцию изучено недостаточно. С одной стороны, попытки оценить влияние отдельных слов и фраз простыми статистическими тестами страдают конфаундингом – фраза может коррелировать с откликом не благодаря своей семантике, а вследствие присутствия в постах определённой популярной тематики. С другой стороны, в задачах прогнозирования популярности контента сегодня доминируют сложные нейросетевые модели, которые обеспечивают высокую точность ценой потери прозрачности. Существует потребность в новых методах, способных работать с высокоразмерными разреженными текстовыми данными, учитывать семантический контекст и при этом давать статистически корректные и интерпретируемые оценки влияния языковых конструкций на метрики вовлечённости.
Ряд недавних работ сфокусирован на том, какие характеристики текста связаны с реакцией аудитории. Например, тон и структура призывов к действию могут существенно влиять на отклик. Показано, что CSR-посты компаний, побуждающие аудиторию к участию в игровых акциях или программах, собирают больше лайков и репостов, тогда как избыточные призывы к обсуждению или одновременное использование нескольких разных призывов снижают вовлечённость [1]. Исследование Gkikas et al. выявило, что читаемость и объём текста, а также число хэштегов статистически значимо связаны с повышением пользовательской активности [2]. Легко читаемые и достаточно длинные описания (более 30 слов, >320 символов) с большим количеством меток показывают более высокий уровень вовлечённости аудитории. Анализ миллионов сообщений в X (бывший Twitter) также подтверждает решающую роль содержимого текста. Так, сравнительное исследование Toraman et al. (2022) показало, что семантика твита является основным драйвером вовлечённости, тогда как идентичность или популярность автора играет меньшую роль [3]. Помимо читаемости и семантики, важным фактором выступает эмоционально-смысловая окраска контента. Например, Saquete et al. (2022) применили анализ мнений и ассоциативных правил для выявления паттернов вирусного распространения сообщений и объяснения, почему одни посты становятся популярнее других [4]. Авторы показали, что определённые сочетания сентимента и тематики значительно повышают «виральность» контента. Существенное влияние оказывает и формулировка заголовков и текстов анонса. Даже при контроле темы и автора разные варианты заголовка заметно влияют на успех поста в Reddit [5]. В совокупности, предыдущие исследования подтверждают. Текстовые особенности публикаций оказывают измеримое влияние на вовлечённость аудитории.
Для количественного предсказания отклика широко используются модели машинного обучения – от регрессий до глубоких нейронных сетей [6]. Так, на данных конкурсов RecSys показано, что предобученные языковые модели способны довольно точно предсказывать метрики реакции по тексту поста [7]. Развиваются и гибридные подходы. Например, предложены графовые нейросети, учитывающие взаимосвязи пользователей при прогнозировании вовлечённости в X (бывший Twitter), а также быстрые сверточные модели, оптимизированные под соревнования рекомендаций контента [8, 9]. Вместе с тем в социальной информатике набирают популярность и каузальные подходы, нацеленные на выявление причинно-следственных связей. В период пандемии COVID-19 предпринимались попытки применить байесовские сети для отсеивания ложных корреляций и идентификации факторов, действительно влияющих на активность пользователей в соцсетях [10]. В сфере маркетинга появились и новые методы целенаправленно для текстовых данных. Lemaire et al. предложили фреймворк на основе эмбеддингов и инструментов причинного вывода, который изолирует вклад отдельных слов, контролируя фоновые переменные [11].
Структурные недостатки «черных ящиков» удаётся решить за счёт использования статистических моделей с латентными переменными. Перспективным инструментом зарекомендовал себя метод частичных наименьших квадратов (Partial Least Squares, PLS) [12]. В задачах с большим числом коррелированных признаков PLS позволяет одновременно выполнить снижение размерности и регрессионный анализ, максимально сохраняя связь «признаки – отклик». Он был успешно применён в различных областях – от хемометрии до анализа поведения пользователей соцсетей. В частности, Yang et al. (2021) интегрировали тематическое моделирование текстов с PLS-SEM для изучения экологических настроений в соцмедиа и подтвердили эффективность PLS-методов для выявления структурных причинно-следственных связей в данных социального мониторинга [13]. В последние годы развиваются расширения классического PLS, сохраняющие его интерпретируемость на новых типах данных. Например, Vicente-Gonzalez et al. (2025) предложили бинарный PLS (BPLSR) для случаев категориального отклика, дополнив его наглядной визуализацией «триплот», что позволило интерпретировать взаимосвязи между наборами бинарных переменных по обе стороны модели [14]. Однако прямое применение линейных моделей (включая PLS) к текстовым признакам сталкивается с проблемой потери лексической структуры. Отдельные слова и фразы не независимы, а образуют группы синонимов и близких выражений. Стандартные методы регуляризации в таких случаях произвольно выбирают один из коррелированных признаков, обнуляя остальные, – что противоречит лингвистической интуиции и снижает устойчивость модели. Для решения этой проблемы в аналитике данных все шире применяется графовая регуляризация, вводящая априорные связи между признаками. Идея состоит в построении графа, где узлы – признаки (фразы), а ребра соединяют семантически сходные выражения [15]. Добавление в функционал регрессии штрафа за разрывы между соседями по графу сглаживает коэффициенты модели. Такой подход уже реализован, например, в задачах факторизации и кластеризации [16]. Регуляризация по графу позволяет учесть внутренние сходства в данных и за счет этого повысить устойчивость выделяемых факторов. В данном исследовании графовая регуляризация применяется впервые в сочетании с PLS для задач текстовой регрессии, что, по сути, встраивает знание о семантической близости слов в модель влияния контента [17].
Цель исследования – разработать и экспериментально верифицировать графо-регуляризованную PLS-модель, которая даёт статистически устойчивые и интерпретируемые оценки инкрементального прироста вовлечённости аудитории в публикацию, снижая смещения, вносимые контекстом, и тем самым обеспечивает прикладной инструмент для выявления формулировок-драйверов реакции аудитории и поддержки решений в контент-маркетинге.
Материалы и методы исследования
Рассматривается датасет из N социальных медиапостов одной тематики. Каждый пост имеет текст и числовой показатель вовлечённости – например, число комментариев. Обозначим через X ∊ RN×m матрицу признаков, где xij = 1, если в j-м посте использована i-я фраза из словаря, и xij = 0 иначе. Вектор y ∊ RN содержит значение метрики вовлечённости для каждого поста (yi – количество комментариев к j-му посту). Требуется построить модель f : X ↦ y, которая позволяет предсказывать уровень отклика по содержимому поста и даёт интерпретируемые оценки вклада отдельных фраз, то есть выявляет фразы-драйверы вовлечённости и количественно оценивает их uplift – прирост отклика при присутствии фразы.
Метод частичных наименьших квадратов выполняет проекцию исходных признаков X в пространство латентных компонентов с одновременной оптимизацией их прогностической значимости для целевой переменной y. В данной работе используется PLS2 – вариант, позволяющий моделировать многомерный отклик. Алгоритм PLS итеративно извлекает набор скрытых компонентов tk = XTwk – линейных сочетаний исходных признаков, – которые максимизируют ковариацию с откликом:
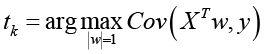 .
.
Компоненты вычисляются последовательно с ортогонализацией по предыдущим. Итоговая модель представляет собой регрессию y на d извлечённых компонент:
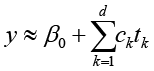 .
.
Вектор c = (c1,…,cd) определяется методом наименьших квадратов. Восстановление коэффициентов при исходных признаках происходит посредством разложения X = TPT + E (где T = (t1,…,td), aP – матрица нагрузок), после чего оценка влияния i-го признака вычисляется как
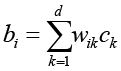 .
.
Эти коэффициенты b ∊ Rm представляют оценочные вклады каждой фразы в отклик. На малых выборках PLS обладает преимуществом перед обычной регрессией и даже RIDGE/LASSO, избегая проблемы мультиколлинеарности. За счёт ограничения пространства несколькими компонентами d ≪ m метод устойчиво оценивает влияния даже при m ≫ N. Однако без дополнительной регуляризации PLS-модель будет выбирать из группы коррелированных фраз одну произвольную, присваивая другим нулевые коэффициенты. Для текстовых данных это означает, что синонимичные или схожие по смыслу выражения могут получить сильно различающиеся оценки bi. Чтобы учесть априорные связи между текстовыми признаками, в модель вводится графовая регуляризация. Составляется ненаправленный граф семантической близости G = (V,E), где вершины V соответствуют уникальным фразам. Ребро (i,j) ∊ E проводится между двумя фразами, если они близки по смыслу. Для количественной оценки семантической близости используется косинусное сходство между векторными представлениями фраз. Если ei – эмбеддинг фразы i, то вес ребра задаётся как wj при превышении заданного порога. Полученный взвешенный граф отражает структуры синонимичных и тематически связанных выражений в корпусе. Регуляризация по графу вводится в функционал оптимизации модели в виде штрафа на разрыв значений коэффициентов соседних вершин. Для вектора регрессионных коэффициентов b добавляется пенальти вида формула (1):
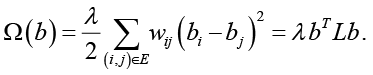 (1)
(1)
В формуле (1) L – лапласиан графа G, λ > 0 – коэффициент регуляризации. Данный член штрафует ситуацию, когда две семантически близкие фразы имеют сильно различающиеся оценки влияния. Минимизация bTLb эквивалентна требованию гладкости распределения эффектов на графе. Модель по возможности будет присваивать схожие коэффициенты синонимичным выражениям. Это позволяет «заимствовать силу» между редкими и частотными синонимами. Даже если какая-то фраза встречается редко и её индивидуальный эффект статистически незначим, но у неё есть более частотные синонимичные соседи с уверенно положительным влиянием, регуляризация подтянет оценку редкой фразы вверх. Предлагаемый Graph-Regularized PLS сочетает описанные элементы. На первом этапе выполняется PLS. Вычисляются матрица компонент T и веса W = (wik)m×d. Затем решается задача регрессии с графовой регуляризацией в пространстве исходных признаков. Эквивалентно можно рассматривать, что сразу получили оценки bi из решения оптимизационной задачи (2):
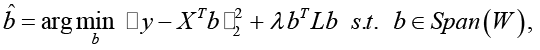 (2)
(2)
где условие b ∊ Span(W) означает, что вектор коэффициентов лежит в пространстве, порождённом колонками W (то есть учитываются только компоненты, извлечённые PLS). Фактически, GR-PLS добавляет к PLS-регрессии квадратичный штраф на разности bi – bj для связанных вершин графа. Задача является выпуклой и решается через систему нормальных уравнений с поправкой Лапласиана: (XXT + λL)b = Xy. В данном экспериментальном прототипе подбор оптимального λ осуществлялся по критерию минимизации ошибки предсказания на контрольной подвыборке. В качестве количественной меры влияния текстовой фразы на вовлечённость используется её uplift – относительный прирост целевой метрики при использовании данной фразы. Если ŷj – предсказанное моделью значение отклика для поста j, то uplift фразы i определим как процентное изменение ŷj при добавлении фразы i в текст (3):
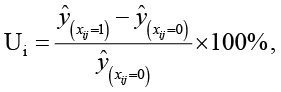 (3)
(3)
где ŷ(xij = 0) – прогноз модели для того же поста, но с обнулённым признаком i. В линейной модели это упрощается.
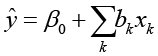 ,
,
поэтому 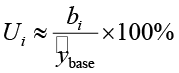 .
.
В GR-PLS расчёт uplift основан на регуляризованных коэффициентах 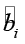 . Таким образом, положительный Ui означает, что присутствие фразы i в тексте статистически увеличивает ожидаемую вовлечённость на Ui процентов против среднего уровня, отрицательный – снижает.
. Таким образом, положительный Ui означает, что присутствие фразы i в тексте статистически увеличивает ожидаемую вовлечённость на Ui процентов против среднего уровня, отрицательный – снижает.
Результаты исследования и их обсуждение
Несмотря на то что эмпирическая проверка выполнена на данных одного бренда, такой дизайн апробации является методологически оправданным и достаточным для демонстрации работоспособности GR-PLS в прикладных условиях. Во-первых, фокус на одном бренде фиксирует аудиторию, тон коммуникации и стратегию публикаций, тем самым снижая межбрендовую гетерогенность и позволяет проверять именно целевую способность метода отделять вклад конкретных формулировок от эффекта контекста внутри однородного коммуникационного потока. Во-вторых, выбранный корпус воспроизводит ключевые реальные сложности задачи высокой размерности и разреженности матрицы фраз, сильной коррелированности и синонимичности выражений, а также наличия контекстных смешивающих факторов, из-за чего требуется прохождение всей технологической цепочки метода от извлечения фраз и построения семантического графа до подбора регуляризации и получения интерпретируемых оценок эффектов с доверительными интервалами. В-третьих, устойчивость результатов дополнительно контролируется процедурно через валидацию на отложенных данных или кросс-валидацию, бутстрап-интервалы и анализ чувствительности по временным подвыборкам, что повышает доверие к выявленным драйверам и демонстрирует практическую применимость подхода для поддержки решений в контент-маркетинге при выборе формулировок и планировании A/B-проверок. Забегая вперёд, отметим, что экспериментальная апробация также проводилась на данных других брендов, где были получены аналогичные воспроизводимые результаты, согласующиеся с выводами, представленными ниже.
Для апробации метода использовались данные официальной страницы автоконцерна Nissan в социальной сети. Из выгрузки выбрана однородная выборка из 200 постов бренда, каждый с текстовым описанием и числом пользовательских комментариев, как основной метрикой вовлечённости. Тексты подвергнуты очистке. Словарь уникальных значимых фраз составил m = 784, матрица признаков X разреженная (плотность ~1.6%). Граф семантической близости фраз построен на основе дистрибутивных эмбеддингов. Использована модель Word2Vec по корпусу брендовых постов, для каждой фразы вычислен вектор как среднее слов, далее для каждой пары фраз с косинусным сходством >0.7 проведено ребро. Полученный граф имел 784 вершин и 4 690 рёбер. Параметры GR-PLS. Число латентных компонент d = 10, коэффициент регуляризации графа оптимизирован по отложенной выборке (лучший λ ≈ 0.1).
Таблица 1 содержит качество предсказания вовлечённости для предлагаемого метода и базовой модели без учета графа. В качестве базы выбрана PLS-регрессия без регуляризации (с тем же d = 10). Видно, что включение графовой регуляризации существенно повышает объясняющую способность модели: R2 увеличивается с ~0.17 до ~0.31 на тестовых данных. Также значительно снизилась среднеквадратичная ошибка (RMSE). Это свидетельствует, что учет семантических связей между фразами позволяет модели устойчивее выявлять истинные эффекты и лучше обобщать на новые наблюдения.
Главное преимущество GR-PLS – способность выявлять конкретные текстовые драйверы вовлечённости. Также стоит отметить, что графовая регуляризация явно сгладила оценки внутри семантических групп. Близкие по теме фразы получили сопоставимые веса. Например, кластер фраз, связанных с переходом на сайт, во всех случаях получил положительные коэффициенты bi ≈ 0.25–0.3. Это отличается от разрозненных результатов, которые показывала модель без графа. Аналогично, синонимичные призывы к участию в конкурсе сгруппировались и все получили очень высокий положительный вес.
Таблица 2 показывает топ-5 фраз с максимальным положительным uplift. Приведены также 95%-доверительные интервалы, полученные бутстрапированием выборки. Абсолютным лидером стала фраза «попасть в следующий пост» – т.е. призыв к пользователям участвовать в создании следующей публикации бренда. Согласно модели, наличие такого призыва повышает ожидаемое число комментариев на +367% по сравнению со средним уровнем (при p < 0.01). Этот результат отражает механику конкурсных активностей. Аудитория активно откликается, когда бренд обещает отметить или упомянуть лучших комментаторов в следующем посте. Высокий uplift (+136%) показали фразы «подробности на официальном сайте» и схожие обращения к переходу на сайт. На первый взгляд, это нетривиальный инсайт. Считается, что вставка внешней ссылки снижает вовлечённость в соцсети, отвлекая пользователя. Однако для автомобильного бренда обнаружено обратное. Аудитория, заинтересованная подробностями (спецификациями, ценами), напротив, более активно комментирует такие посты. Вероятно, детальный контент стимулирует обсуждение. Ещё одна группа – технические характеристики продукта. Фраза «система полного привода» стабильно даёт +65% комментариев. Это подтверждает, что целевую аудиторию Nissan сильно интересуют технические особенности (в данном случае – проходимость внедорожников), и посты с упором на эти свойства вызывают дополнительный отклик. Отметим, что для всех вышеперечисленных факторов PLS-оценки без графовой регуляризации были бы менее значимыми из-за мультиколлинеарности. Метод GR-PLS же «перенёс» значимость от родственных фраз, выдав более надёжные совокупные оценки эффектов.
Таблица 1
Качество моделей предсказания комментариев по тексту поста
|
Модель |
R² на тестовой выборке |
RMSE на тестовой выборке |
|
PLS (10 компонент) |
0,170 |
5,21 |
|
GR-PLS (10 компонент, графовая регуляризация) |
0,310 |
4,47 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Таблица 2
Топ-5 фраз-драйверов вовлечённости по оценке GR-PLS (данные Nissan)
|
Фраза (лемматизировано) |
Uplift, % |
95% ДИ, нижняя граница |
95% ДИ, верхняя граница |
Частота, n |
|
«попасть в следующий пост» |
+367,1 |
+80,6 |
+1108,0 |
17 |
|
«подробности на офиц. сайте» |
+136,0 |
+39,7 |
+298,6 |
24 |
|
«прямая ссылка (http…)» |
+110,6 |
−4,9 |
+366,6 |
10 |
|
«официальный дилерский центр» |
+107,5 |
−3,4 |
+345,7 |
11 |
|
«система полного привода» |
+65,2 |
+15,1 |
+148,3 |
23 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Из таблицы видно, что помимо конкурсного механика («попасть в пост») и призывов к переходу на сайт, значимый эффект дает акцент на технических преимуществах продукта. Для маркетологов автомобильной отрасли это ценное указание. Подчёркивание конкретных характеристик (например, полноприводной системы) действительно стимулирует обсуждения больше, чем общие рекламные слоганы. Интересно, что некоторые фразы с высоким сырым эффектом при наивном анализе потеряли значимость после учета контекста. К примеру, выражение «благодарим за фото подписчика» в простой выборке ассоциировалось с резким ростом комментариев (+201% в t-тесте), но модель GR-PLS присвоила ей нулевой коэффициент. Причина выяснилась при изучении данных. Такие фразы встречались преимущественно в постах с пользовательскими фотографиями, которые сами по себе собирают много комментариев. Наивный анализ приписал весь эффект слову «благодарим», тогда как авторский метод корректно перераспределил эффект на фактор UGC-контента. Благодаря графовой регуляризации схожие благодарственные фразы тоже не были ошибочно отмечены как «магические» триггеры. Таким образом, GR-PLS успешно устраняет ложные драйверы, возникающие из-за спутанности признаков с темой поста. Полученные результаты подтверждают, что предложенная методика позволяет выявлять интерпретируемые текстовые детерминанты вовлечённости. В отличие от «чёрных ящиков», модель даёт маркетологам понятные рекомендации – на какие формулировки делать упор при подготовке контента, чтобы повысить отклик аудитории.
Заключение
В работе представлен новый подход GR-PLS – графо-регуляризованная регрессия на основе частичных наименьших квадратов – для анализа влияния семантических компонентов текста на вовлечённость в социальных медиа. Метод сочетает достоинства PLS, а именно устойчивость при m ≫ N, выделение информативных латентных факторов с учётом семантических связей между фразами через графовую регуляризацию. Благодаря этому достигается более точное и интерпретируемое ранжирование текстовых триггеров вовлечённости. Схожие по смыслу фразы получают сглаженные коэффициенты, исключаются случайные всплески за счёт контекста.
На примере данных бренда Nissan показано, что GR-PLS существенно превосходит классические методы по качеству (R2 повышается в ~1.8 раза) и выявляет нетривиальные инсайты. В частности, обнаружено, что конкурсные призывы, побуждение к изучению деталей на сайте, а также подчёркивание технических характеристик продукта являются сильными драйверами комментариев (+65–367% к среднему), тогда как вежливые благодарности или общие маркетинговые фразы сами по себе не увеличивают активность аудитории. Эти выводы согласуются с интуицией и дают конкретные рекомендации для SMM-стратегии.
Conflict of interest
Financing
Библиографическая ссылка
Родионов Д.Г., Поляков П.А., Конников Е.А., Старченкова О.Д. Выявление текстовых драйверов вовлеченности аудитории бренда в социальных медиа на основе графо-регуляризованного подхода // Современные наукоемкие технологии. 2026. № 1. С. 73-79;URL: https://top-technologies.ru/en/article/view?id=40651 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.40651