


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
RESEARCH OF MACHINE LEARNING ALGORITHMS FOR VIBRATION CONDITION PREDICTION COMPRESSOR UNIT

Введение
Одна из главных тенденций современного производства – это концепция, которая предполагает цифровизацию производства, внедрение в него предиктивной (прогнозной) аналитики, работа с большими данными, создание цифровых двойников [1–3]. Данная работа посвящена анализу применения методов машинного обучения для решения задач предиктивного анализа при работе технологического оборудования, задействованного в технологическом процессе переработки и производства нефтепродуктов [4–6]. Своевременное предсказание эффективной работы оборудования и выявление аномалий в его работе существенно увеличит экономическую эффективность и безопасность производства, так как уменьшит вероятность нарушения в обеспечении проведения непрерывных технологических процессов.
Цель исследования – провести анализ и сравнение методов машинного обучения для реализации задач прогнозирования состояния вибрации компрессорной установки.
Материалы и методы исследования
Для построения моделей был использован язык Python, cреда разработки Jupyter Notebooks. В разработке программ по исследованию алгоритмов машинного обучения использование библиотек Python обусловлено их функциональными возможностями и особенностями, которые позволяют эффективно обрабатывать и анализировать данные [7, 8]. NumPy служит основой для численных вычислений, Pandas упрощает манипуляцию табличными данными, Matplotlib и Seaborn обеспечивают возможности визуализации данных, Statsmodels позволяет оценивать и анализировать различные статистические модели, Scikit-learn предоставляет разнообразные алгоритмы машинного обучения.
Объект исследования – компрессорная установка модели С-85.6, управляемая с помощью программируемого логического контроллера, данные с которого отправляются в программный пакет для диспетчерского управления и сбора данных, который представляет собой распределенную систему управления CENTUM VP от компании Yokogawa Electric Corporation, предназначенной для мониторинга и управления технологическим процессом. Система резервирует все компоненты системы, имеет распределенную архитектуру «клиент-сервер», хранит данные технологической линии, которые и понадобятся для исследования. Для проведения анализа был использован табличный формат данных – .csv. Для прогнозирования технического состояния компрессора методом машинного обучения проведены исследования исторических данных значений с датчиков вибрации, давления, падения штока (износ сальника) поршневой компрессорной установки. Полученные для анализа значения с датчика вибрации снимаются с периодичностью в 1 мин. Количество наблюдений 43 165 строк. В исследовании выполняется прогнозирование вибрации корпуса компрессора (датчик поз.1V-VIA1967.PV).
Для совершения оперативных прогнозов с помощью авторегрессионых моделей временной ряд должен быть стационарным [9–11]. По стационарному ряду строится прогноз, так как его будущие статистические характеристики не отличаются от наблюдаемых текущих. Проверка ряда на стационарность показала, что полученное значение p-value 0,018859 меньше 0,05 – значит, ряд стационарен. Распределение целевой переменной (вибрация) показало, что оно близко к нормальному, с легким перекосом вправо, в основном значения варьируются в диапазоне от 7 до 10 мм/с. Корреляционная матрица показала высокую корреляцию между переменными давления (P_нагнет и P_всас) и целевой переменной и низкую корреляцию между сдвигами штоков и вибрацией. Наиболее коррелирующие признаки с вибрацией: P_нагнет_4, P_нагнет_3, P_всас_4, P_всас_3, P_нагнет_2. Визуализация показала линейную зависимость между вибрацией и давлениями, что подтверждает значимость этих признаков для модели. В данном исследовании, в случае прогнозирования одномерных рядов, использованы методы авторегрессии и авторегрессии со скользящей средней [12]; для прогнозирования многомерных рядов использованы методы линейной регрессии, деревьев решений [13], случайный лес [14] и градиентный бустинг [15]. Во всех моделях обучающая выборка включает данные, использованные для обучения модели прогнозирования. Тестовая выборка содержит данные, которые не использовались при обучении модели, но применялись для проверки ее точности. Прогон представляет собой данные, обработанные моделью после завершения обучения. Доверительный интервал указывает на уровень уверенности в прогнозах, показывая верхнюю и нижнюю границы возможных значений.
Результаты исследования и их обсуждение
Авторегрессионные модели (AR-модели) используют прошлые значения ряда для прогнозирования его будущих значений. Эта модель предполагает, что текущее значение ряда зависит от его предыдущих значений. В данном исследовании были использованы модели AutoReg и ARIMA. На графике, представленном на рис. 1, отображены прогнозируемые значения вибрации компрессора. Из графика видно, что модель прогнозирует вибрацию компрессора только в краткосрочном периоде.
Комбинация авторегрессионной модели порядка p и модели скользящего среднего порядка q дает смешанную авторегрессионную модель скользящего среднего (ARMA (p, q)). ARMA, как и AR модель, используется только для стационарных рядов. Для работы с нестационарными рядами формируется модель ARIMA, тем, что в модель ARMA включается оператор взятия простых разностей порядка d.
На графике, представленном на рис. 1, отображены прогнозируемые значения вибрации компрессора с использованием модели ARIMA. Результат показал, что модель прогнозирует вибрацию компрессора также в краткосрочном периоде.
На рис. 2 представлены прогнозы модели, обученной на методе линейной регрессии. Также на рис. 2 приведено ограниченное отображение данных для улучшения читаемости. Значения полученных метрик при выполнении программы приведены в таблице сравнения с другими алгоритмами.
Деревья решений (Decision Trees) – один из наиболее эффективных инструментов интеллектуального анализа данных и предсказательной аналитики. На рис. 3 представлен прогноз модели, обученной на методе деревьев решений. Значения полученных метрик приведены в таблице анализа (таблица).
При прогнозировании алгоритм «Случайный лес» (Random Forest) объединяет результаты всех деревьев либо путем голосования (для задач классификации), либо путем усреднения (для задач регрессии). Этот процесс совместного принятия решений, основанный на выводах нескольких деревьев, обеспечивает стабильные и точные результаты. Случайные леса уменьшают переобучение и обеспечивают надежные прогнозы в различных условиях. На рис. 3 представлен прогноз модели, обученной на методе «Случайный лес». Значения полученных метрик приведены в таблице анализа.
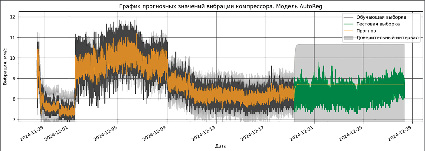
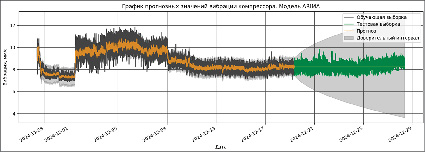
Рис. 1. График предсказания с помощью модели AR и ARIMA Источник: составлено авторами по результатам данного исследования
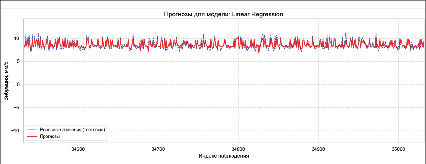
Рис. 2. Графическое представление прогноза модели линейной регрессии Источник: составлено авторами по результатам данного исследования
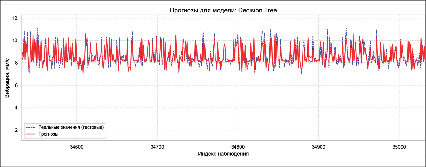
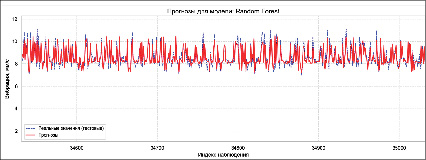
Рис. 3. Графическое представление прогноза модели деревья решений и Random Forest Источник: составлено авторами по результатам данного исследования
В рамках исследования была использована модель градиентного бустинга из библиотеки XGBoost, которая предлагает высокоэффективную реализацию градиентного бустинга на основе решающих деревьев. Прогнозирующая модель также состоит из ансамбля слабых предсказывающих моделей – деревьев решений. Подготовка данных для предсказаний с использованием XGBoost аналогична подготовке данных для модели линейной регрессии.
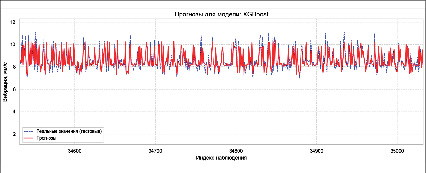
Рис. 4. Графическое представление прогноза модели XGBoost Источник: составлено авторами по результатам данного исследования
Метрики качества моделей
|
Model |
R2 |
MSE |
MAPE |
|
|
1 |
AutoReg |
0,980000 |
0,347148 |
6,355062 |
|
2 |
ARIMA |
0,818801 |
0,138474 |
3,233626 |
|
3 |
Linear Regression |
0,606385 |
0,309984 |
4,675680 |
|
4 |
Decision Trees |
0,801051 |
0,156679 |
3,408400 |
|
5 |
Random Forest |
0,827071 |
0,136187 |
3,223779 |
|
6 |
XGBoost |
0,823468 |
0,139025 |
3,267489 |
Источник: составлено авторами на основе полученных данных в ходе исследования.
Главная ценность библиотеки XGBoost заключается в ее высокопроизводительной реализации. Благодаря различным оптимизациям, таким как эффективное управление пропущенными значениями, поиск порога только среди персентилей, оптимизированная работа с кэшированием и поддержка распределенного обучения, производительность возрастает в десятки или даже сотни раз по сравнению с примитивными реализациями. На рис. 4 представлены прогнозы модели, обученной на методе градиентного бустинга. Значения полученных метрик приведены в таблице анализа.
Информация об исследованных моделях c полученными метриками (коэффициент детерминации, среднеквадратичная ошибка, средняя абсолютная ошибка в процентах) их качества представлена в сводной таблице.
В результате проведенного статистического анализа были получены значимые метрики качества аппроксимации. Количественная оценка авторегрессионной модели (AutoReg) свидетельствует о том, что вариабельность целевой переменной на 98 % обусловлена изменениями предикторной переменной вибрации, что подтверждает высокую прогностическую способность модели. Дополнительно проведенный анализ среднеквадратичной ошибки (MSE), составившей 0,35, указывает на незначительную дисперсию отклонений наблюдаемых значений от расчетных. Данный факт свидетельствует о высоком качестве подгонки модели к исходному набору данных.
Коэффициент детерминации интегрированной модели авторегрессии скользящего среднего (ARIMA) указывает на то, что модель объясняет примерно 82 % вариации данных. Это довольно хороший результат, свидетельствующий о том, что модель достаточно точно описывает динамику временного ряда. Низкое значение MSE указывает на умеренную ошибку прогноза, но при этом она все еще остается приемлемо низкой. В среднем прогнозы отличаются от истинных значений на 3,23 %, это очень низкий уровень ошибки. Совокупный анализ всех диагностических метрик позволяет сделать обоснованный вывод о высокой эффективности модели ARIMA в контексте прогнозирования временных рядов. Полученные результаты подтверждают ее пригодность для решения задач прогностического моделирования с обеспечением высокого уровня точности предсказаний.
Линейная регрессия (Linear Regression) показала наихудшее качество предсказания с метрикой R2 = 0,606. Это свидетельствует о том, что зависимость между признаками и целевой переменной нелинейная, и простая линейная модель не может адекватно описать данные.
Проведенное сравнительное исследование эффективности алгоритмов машинного обучения выявило существенные преимущества модели дерева решений (Decision Trees) над классической линейной регрессией в контексте качества аппроксимации данных. Коэффициент детерминации (R2 = 0,801) демонстрирует значительное превосходство данной модели, что свидетельствует о ее способности эффективно выявлять и моделировать нелинейные взаимосвязи в исследуемом наборе данных. Однако относительно высокий MSE (0,156) может указывать на потенциальную проблему переобучения модели. Данный факт требует дополнительного внимания при дальнейшей настройке гиперпараметров и оптимизации архитектуры модели для достижения оптимального баланса между способностью к обобщению и точностью аппроксимации.
Модель случайного леса (Random Forest) показала лучшее качество предсказания с R2 = 0,827 и снижением ошибки MSE = 0,136. Использование ансамбля деревьев помогло уменьшить переобучение и повысить обобщающую способность модели.
Градиентный бустинг (XGBoost) показал близкое качество к случайному лесу с R2 = 0,823 и MSE = 0,139. Модель также хорошо справилась с нелинейностями и сложными зависимостями, а встроенные методы регуляризации уменьшили вероятность переобучения.
Заключение
В результате проведенного исследования собраны данные в виде временных рядов для разработки предиктивной модели, которые отображают основные параметры в работе компрессора. Был проведен сравнительный анализ методов машинного обучения для прогнозирования состояния вибрации компрессорной установки. Для задачи регрессии одномерных рядов лучше всего подошли модели авторегрессии. Для моделей AutoReg и ARIMA необходим стационарный временной ряд для получения точных и интерпретируемых результатов. При этом модель AutoReg имеет более высокие показатели качества прогнозирования. Для задачи регрессии многомерных рядов лучше всего подходят ансамблевые методы, такие как случайный лес и XGBoost. Случайный лес можно рекомендовать как основную модель из-за чуть более высокого R2 и простоты настройки гиперпараметров. XGBoost может быть полезен для дальнейшего улучшения качества предсказаний, особенно на большом количестве данных. Важно экспериментировать и настраивать параметры для каждого конкретного временного ряда, учитывая такие факторы, как наличие сезонности, тренда и выбросов в данных. При выборе метода прогнозирования необходимо учитывать не только его математические характеристики, но и особенности конкретных данных, на которых он будет применен.
Библиографическая ссылка
Вотякова Л.Р., Горячев А.С. ИССЛЕДОВАНИЕ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПРОГНОЗИРОВАНИЯ СОСТОЯНИЯ ВИБРАЦИИ КОМПРЕССОРНОЙ УСТАНОВКИ // Современные наукоемкие технологии. 2025. № 7. С. 8-14;URL: https://top-technologies.ru/en/article/view?id=40434 (дата обращения: 20.07.2026).
DOI: https://doi.org/10.17513/snt.40434