


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
Application of generative-adversarial networks in unpaired image transfer

Введение
Генеративно-состязательные сети (GAN) продемонстрировали значительный успех в создании высококачественных изображений в различных областях [1–3], исходя из чего было принято решение использовать именно их. Используя их способность обучаться сложным распределениям и генерировать реалистичные изображения, можно создавать точные переносы «день-ночь».
Актуальность данного исследования многогранна. Во-первых, оно имеет практическое значение для многих отраслей, которые зависят от визуальных данных, например для киностудий, где часто требуется перевести день в ночь, чтобы совместить кадры, снятые в разное время суток. Во-вторых, она может помочь градостроителям в визуализации городских пейзажей при различных условиях освещения, что позволит им принимать более обоснованные решения относительно инфраструктуры и безопасности. Наконец, в сфере безопасности перенос изображения с дневного на ночное может расширить возможности систем видеонаблюдения, позволяя им эффективно работать как днем, так и ночью.
Цель данного исследования – рассмотреть применение современных методов непарного переноса изображений в контексте обучения без учителя. Потенциальные выгоды от успешного выбора реализации этой задачи значительны и охватывают различные отрасли и сферы применения.
Материалы и методы исследования
Литературный обзор включал в себя полнотекстовые оригинальные и обзорные статьи на английском языке через базу поиска arXiv preprint arXiv. Общая методология исследований представлена аналитико-синтетическим, сравнительным, статистическим подходами:
1. Анализ различных архитектур GAN, которые влияют на качество сгенерированных изображений.
2. Сравнение различных архитектур генераторов и дискриминаторов для оценки их эффективности в области переноса изображений (циклическая генеративно-состязательная сеть (CycleGAN), контрастный непарный перенос (CUT), фиксированное/обученное самоподобие (F/LSeSim)).
3. Обоснование возможности улучшения качества сгенерированных изображений путем адаптации GAN для конкретных приложений и дальнейшего исследования.
Результаты исследования и их обсуждение
GAN широко используются в контексте переноса изображений друг в друга благодаря своей способности генерировать похожие изображения. Однако им не хватает контроля над генерируемыми данными.
Сохранение взаимосвязи между входными и выходными изображениями – важнейший аспект переноса изображений. Например, при переносе лошади на зебру должен меняться только внешний вид, а остальные аспекты остаться неизменными. Расчет расстояния или вектора на уровне пикселей не всегда дает удовлетворительные результаты для этой задачи [4–6]. На более абстрактном уровне для сравнения карт признаков или пространственно-корреляционных карт были предложены потери на основе признаков, которые могут эффективно сохранять специфические для данного домена признаки [7].
Цикловая согласованность CycleGAN. Ключевая идея CycleGAN заключается в том, чтобы ввести потерю цикловой согласованности, которая побуждает оба генератора к обучению согласованным отображениям между двумя доменами. На рис. 1 представлен принцип работы цикловой согласованности.
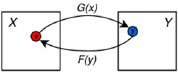
Рис. 1. Схема цикловой согласованности для двух доменов X и Y: х – изображение домена X, y – изображение домена Y
Этого можно достичь, пропуская изображения через пары генераторов (G и F), обеспечивая реконструкцию исходного изображения. Математически функция потерь цикловой согласованности может быть определена следующим образом [6]:
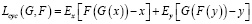 , (1)
, (1)
где F(G(x)) – прямая цикловая согласованность;
G(F(y)) – обратная цикловая согласованность.
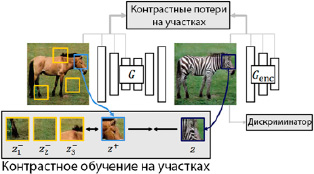
Рис. 2. Контрастное обучение на участках (Patchwise Contrastive Learning) для одностороннего переноса
Потери CycleGAN. Потери для CycleGAN состоят из двух частей: состязательные потери, которые побуждают генераторы производить образцы, неотличимые от реальных образцов дискриминаторов и потерь цикловой согласованности (Lcyc). Их можно выразить через следующую формулу:
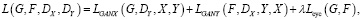 (2)
(2)
где LGANX(G,DY,X,Y) – функция состязательных потерь домена Х;
LGANY(F,DX,Y,X) – функция состязательных потерь домена Y;
λ – относительная важность двух функций, было взято значение 10;
Lcyc(G,F) – функция потерь цикловой согласованности.
В модели используются две состязательные сети:
– дискриминатор DX , отличающий изображения x, x ∈ X от перенесенных F(y);
– дискриминатор DY , отличающий изображения y, y ∈ Y от перенесенных G(x).
DX заставляет генератор G переносить изображения из X в неотличимые от домена Y изображения, аналогично DY, поощряет F синтезировать близкие к X изображения. Авторы [6] ввели функции потерь цикловой согласованности Lcyc (1) и две функции состязательных потерь LGANX и LGANY.
Контрастный непарный перенос (CUT). В области переноса изображения с одного изображения на другое, как показано на рис. 2, задача состоит в том, чтобы преобразовать входное изображение, сохранив его структурное содержание, но изменив его внешний вид в соответствии с целевым доменом. Для этого необходимо разделить содержание, которое должно оставаться неизменным в разных доменах, и внешний вид, который должен быть изменен.
Используя контрастную функцию потерь, такую как InfoNCE [8], данная модель учится связывать соответствующие признаки, одновременно отделяя их от других частей входного изображения или нерелевантного фона. Это побуждает сеть фокусироваться на общих чертах между доменами (например, части и формы объектов), оставаясь инвариантной к различиям (например, текстуры животных).
Генератор и кодировщик вместе создают изображение, по которому можно отследить соответствующие входные данные. Используя многослойное контрастное обучение с использованием патчей и извлекая негативы из входного изображения, метод эффективно сохраняет содержание входных данных.
Потери CUT. В обучении без учителя подход контрастного обучения использовался как на уровне изображений, так и на уровне патчей (участков) [9, 10]. Для рассматриваемой задачи важно понимать, что не только целые изображения должны сохранять сходство содержания, но и соответствующие участки входных и выходных изображений. Эта идея мотивирует использование многослойного обучения на основе патчей.
В CUT выбирают L интересующих слоев и пропускают карты признаков через небольшую двухслойную MLP-сеть Hl, создавая стек признаков
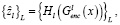 (3)
(3)
где 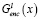 – выход l-го выбранного слоя;
– выход l-го выбранного слоя;
Hl – двухслойная MLP-сеть.
Сама функция потерь PatchNCE приведена ниже:
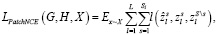 (4)
(4)
где Sl – количество пространственных расположений в каждом слое;
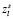 – соответствующий индексу признак,
– соответствующий индексу признак,
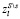 – другие признаки.
– другие признаки.
Цель обучения CUT. Цель обучения у данной модели двояка: создание реалистичных изображений при сохранении соответствия между признаками на входных и выходных изображениях. Как показано на рис. 2, задача минимаксной игры предназначена для достижения этого баланса. Кроме того, можно использовать потери PatchNCE для изображений из домена Y, чтобы предотвратить ненужные изменения в генераторе. По сути, эти потери являются обучаемой, специфичной для домена версией потерь идентичности, используемой в предыдущих методах непарного переноса, в том числе в CycleGAN [11].
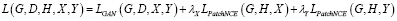 (5)
(5)
где LGAN(G,D,X,Y) – состязательные потери,
λX = 1, если λY = 1, как было описано в [14],
LPatchNCE(G,Н,X) – потери PatchNCE на изображение домена Х,
LPatchNCE(G,Н,Y) – потери PatchNCE на изображение домена Y,
Фиксированное/Обученное Самоподобие (F/LSeSim). Чуанься Чжэн и др. [5] представили новый метод для задач переноса изображений, который фокусируется на явном обучении пространственно-корреляционных карт. Такой перенос изображения сохраняет шаблоны самоподобия в исходном и перенесенном изображениях, независимо от геометрической формы или внешнего вида.
Хотя GAN могут генерировать изображения, соответствующие общему распределению набора данных, они часто не могут сохранить структуру сцены при переносе, если были обучены с только состязательными потерями. Для решения этой проблемы были разработаны различные потери для оценки согласованности содержания, такие как потери при реконструкции изображения на уровне пикселей, потери цикловой согласованности, потери при восприятии на уровне признаков и потери PatchNCE. Однако эти методы все еще страдают от некоторых ограничений. Потери на уровне пикселей не разделяют структуру и внешний вид, в то время как потери на уровне признаков объединяют признаки, характерные для конкретной области. Кроме того, большинство потерь на уровне признаков опираются на фиксированные сети ImageNet, которые могут плохо адаптироваться к произвольным областям.
Несмотря на значительные внешние различия между лошадью и зеброй, когда структуры объектов идентичны (например, одинаковые позы), пространственные шаблоны самоподобия также совпадают, что наглядно представлено на рис. 3.
Оценивая проявления совпадений в самоподобии, можно явно представить структуру в виде нескольких пространственно-корреляционных карт, визуализированных в виде тепловых карт на рис. 3, в и г [5].
Потери F/LSeSim. Фиксированное самоподобие. В предлагаемых авторами [5] фиксированных пространственно-корреляционных потерь, они сравнивают структурное сходство между входным изображением x в определенном домене и его соответствующим переносом ŷ в другом домене. Для этого сначала используется сверточная нейронная сеть, такая как VGG16 [5], для извлечения признаков для обоих изображений, в результате чего получаются векторы признаков fx и fŷ. Вместо того чтобы напрямую вычислять расстояние между этими векторами (fx – fŷ ), они вводят понятие пространственно-корреляционной карты, математически определяемой как
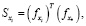 (6)
(6)
где 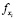 – признак точки запроса xi;
– признак точки запроса xi;
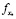 – соответствующие признаки в патче точек Np;
– соответствующие признаки в патче точек Np;
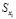 – пространственная корреляция между точкой запроса и другими точками в патче.
– пространственная корреляция между точкой запроса и другими точками в патче.
После этого вся структура изображения представляется с помощью набора пространственно-корреляционных карт 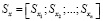 . Такое представление позволяет проводить сравнения с большей вычислительной эффективностью.
. Такое представление позволяет проводить сравнения с большей вычислительной эффективностью.

Рис. 3. Обученное пространственно-корреляционное представление кодирует локальную структуру объекта на основе самоподобия [5]
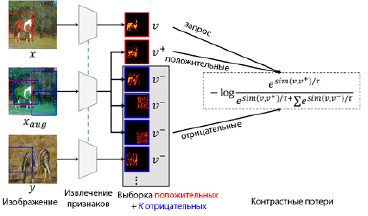
Рис. 4. Контрастное обучение на участках для получения самоподобия [5]
Затем сравниваем карты множественного структурного сходства между входным x и перенесенным изображением ŷ следующим образом:
Ls = d(Sx,Sŷ), (7)
где Sx – набор пространственно-корреляционных карт, представляющий структуру изображения,
Sŷ – соответствующие Sx пространственно-корреляционных карты в целевом домене.
Для метрики расстояния d существуют два варианта: расстояние L (Sx – Sŷ ) и косинусное расстояние (1 – cos(Sx;Sŷ )). Первое способствует постоянству пространственного сходства во всех точках участка, а второе – корреляции шаблонов без учета различий в величине Sx и Sŷ.
Обученное самоподобие. В контексте обучения без учителя авторы [5] предлагают генерировать пары схожих признаков на участках для эффективного обучения. Это достигается путем создания дополненных изображений с помощью структурно-сохраняющих преобразований. Обозначим патч «запроса» как 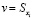 . «Положительные» и «отрицательные» образцы патча будут обозначены как
. «Положительные» и «отрицательные» образцы патча будут обозначены как 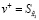 и
и 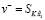 соответственно.
соответственно.
Запрашиваемый патч позитивно сопоставляется с патчем в той же позиции i в аугментированном изображении xaug. В то же время он отрицательно сопрягается с патчами, отобранными из других позиций в xaug, или патчами из других изображений y.
В LSeSim, как показано на рис. 4, используется контрастная функция потерь, которая поощряет подобие между запросом и положительными образцами и одновременно поощряет несходство с отрицательными образцами.
Для извлечения признаков подаются три изображения, в которых два изображения, x и xaug, с одинаковой структурой, но разным внешним видом, а y – еще одно случайно выбранное изображение. Для каждого запрашиваемого участка в x положительным образцом является соответствующий участок в xaug, а все остальные участки рассматриваются как отрицательные образцы.
Контрастные потери (L) определяются следующим образом:
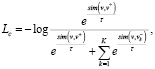 (8)
(8)
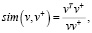 (9)
(9)
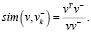 (10)
(10)
где sim(v,v+/–) – косинусоидальное подобие между двумя векторами;
K – количество рассматриваемых отрицательных патчей;
k – индекс отрицательных образцов;
τ – температурный параметр, взято значение 0,07 [5].
Подводя итог, для оптимизации сети представления структуры f используется контрастная функция потерь, которая способствует сближению схожих патчей и оттеснению несхожих. При этом пространственно-корреляционные потери в (8) используются для сети генератора в процессе обучения.
Цель обучения F/LSeSim. Основной целью является обучение сетей при минимизации следующих потерь:
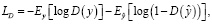 (11)
(11)
LS = Lc, (12)
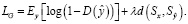 (13)
(13)
где LD – состязательные потери дискриминатора;
LS – контрастные потери сети репрезентации структуры f;
LG – потери генеративной сети G;
λ – гиперпараметр, равный 10 [5].
Сравнительный анализ описанных моделей. Эти методы похожи по архитектуре, но отличаются по критерию потерь. Для репрезентативности сходства и различия сведены в таблицу.
В CycleGAN используется циклическая структура GAN с двумя генераторами и двумя дискриминаторами. CycleGAN также использует потери цикловой согласованности, чтобы входные изображения после прямого и обратного отображения были как можно ближе к исходным изображениям. Однако из-за двух GAN эта система имеет тяжелую структуру и требует большого объема памяти. В CUT впервые было использовано контрастное обучение для переноса изображений без применения сетей обратного отображения и дополнительных дискриминаторов. Благодаря использованию контрастных потерь структура сети значительно облегчается и упрощается. F/LSeSim также использует контрастные потери, но сравнивает пространственно-корреляционную карту, а не признак в определенном слое. Таким образом, удается избежать зависимости между признаками внешнего вида и признаками, отражающими структуру изображения.
Сравнение CycleGAN, CUT и F/LSeSim на основе теоретических сведений
|
Метод |
CycleGAN |
CUT |
F/LSeSim |
|
Тип потерь |
На уровне пикселей |
На уровне признаков |
Пространственно- корреляционная карта |
|
Функция потерь |
состязательные + цикловая согласованность |
состязательные + PatchNCE |
состязательные + самоподобие |
|
Набор данных |
непарный |
||
|
Вклад |
Первое применение цикловой согласованности в GAN |
Отказ от сетей обратного отображения |
Быстрое обучение / точное отображение |
|
Недостатки |
Архитектура, требующая наибольших затрат памяти и времени; неспособность значительно менять геометрическую форму объектов; искажения |
Модель не способна отличать специфические для домена признаки от признаков внешнего вида; искажения |
Искажения |
|
Архитектура |
2 G + 2 D |
1 G + 1 D |
|
Заключение
В ходе экспериментальной работы было проведено обширное исследование в области непарного переноса изображений без учителя, были рассмотрены основные преимущества и недостатки, как теоретические, так и практические.
Важно отметить, что данная работа является лишь началом и дальнейшие исследования должны быть направлены на улучшение качества сгенерированных изображений и эффективности процесса переноса изображений, а также на применение полученных результатов в реальной жизни.
Данная статья представляет собой перспективный материал для научных исследований и практических приложений в области обработки изображений, который может быть использован как база для дальнейшего развития в этой области.
Библиографическая ссылка
Массеров Д.Д., Массеров Д.А., Лядунов К.А., Перков А.А. Применение генеративно-состязательных сетей в непарном переносе изображений // Современные наукоемкие технологии. 2024. № 8. С. 63-69;URL: https://top-technologies.ru/en/article/view?id=40113 (дата обращения: 02.08.2026).
DOI: https://doi.org/10.17513/snt.40113