


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
DEVELOPMENT OF A MULTIMODAL METHOD OF SENTIMENT ANALYSIS TO SUPPORT DECISION-MAKING IN ORGANIZATIONS

Сентимент-анализ (или анализ тональности) является классом методов в компьютерной лингвистике для определения эмоциональной окраски в различных типах данных. Сентимент-анализ широко применяется для мониторинга социальных медиа, анализа потребительских отзывов, в маркетинге и в других областях, где важно понимание чувств и мнений людей по отношению к какому-то событию или понятию, например атомной энергетике [1].
Как правило, при анализе тональности выделяют положительную тональность (благоприятные, утвердительные или оптимистические эмоции), негативную тональность (неблагоприятные или пессимистические эмоции) и нейтральную тональность (отсутствие ярко выраженных эмоциональных оценок или чувств) [2].
Еще одним смежным понятием в сентимент-анализе является эмоциональная окраска. В отличие от общего понятия тональности, эмоциональная окраска позволяет более точно классифицировать специфические эмоции, такие как удивление, страх, печаль, эйфория [3]. Это различие важно в контексте мультимодального сентимент-анализа, где разные каналы (текст, аудио и видео) могут передавать разные аспекты эмоций.
В условиях цифровой трансформации организационные системы сталкиваются с необходимостью быстрого и точного принятия решений. Мультимодальный сентимент-анализ предоставляет эффективный механизм для повышения эффективности таких систем, позволяя управляющим структурам лучше понять и предвидеть реакции клиентов на текущее положение, а также на различные изменения и нововведения. Прежде чем перейти к обсуждению сентимент-анализа как метода математического и компьютерного моделирования, важно кратко рассмотреть процесс выражения эмоций с точки зрения нейробиологии, включая социокультурные аспекты. Само научное изучение эмоций затрагивает множество дисциплин – от нейробиологии и нейрофизиологии, которые изучают механизмы возникновения и распознавания эмоций, до клинической медицины, эволюционной биологии и когнитивистики. В основе научного понимания эмоций лежат следующие аспекты.
1. Нейробиологические основы эмоций – многие медицинские исследования показывают, что такие структуры мозга, как гипоталамус, префронтальная кора и миндалевидное тело, играют ключевую роль в обработке и регуляции эмоций. Эти области мозга отвечают за аверсивные сигналы, например страх и тревогу, и учувствуют в высших когнитивных функциях – принятии решений и эмоциональной регуляции [4].
2. Выражение эмоций через жесты и мимику – работы Пола Экмана начиная с 1967 года демонстрируют универсальность выражений лица для основных эмоций в различных культурах. Пол Экман идентифицировал шесть базовых эмоций (счастье, грусть, страх, отвращение, удивление и гнев) и разработал универсальную систему кодирования действий лица FACS, которая позволяет идентифицировать почти все возможные выражения лица. Этот метод и по сей день используется в методах глубокого обучения для определения векторов по изображениям лиц [5, 6].
3. Когнитивный аспект эмоций – согласно теории Ричарда Лазаруса, эмоции не возникают автоматически в ответ на события, а являются результатом когнитивной оценки, которая включает анализ соответствия событий личным желаниям, важности и возможности эмоциональной адаптации при понимании причины происходящего [7].
4. Влияние культуры на выражение эмоций – хотя основные эмоции универсальны, культурные и социальные нормы могут повлиять на то, как эмоции выражаются и интерпретируются.
Таким образом, одномодальные подходы к сентимент-анализу, например анализ исключительно текстовых данных, сталкиваются с серьезными ограничениями. Текстовые данные хоть и информативны, но не всегда способны передать полный спектр эмоционального фона, который может быть выражен через интонацию, жесты или выражения лица в аудио и видео. Например, иронию и сарказм часто трудно уловить только по тексту, без учета тона и контекста речи. Исследования показывают, что добавление аудиовизуальных данных значительно улучшает точность определения эмоций. Исследуя аудио и видео, можно обнаружить микроэкспрессии, вариации тембра голоса и другие невербальные сигналы, которые не учитываются при анализе только текста [8]. Пренебрежение аудиовизуальным контекстом приводит к упрощению восприятия сообщений, что критично в коммуникации, где звук и изображения играют центральную роль в передаче информации и эмоций.
С учетом этих ограничений одномодальных методов становится очевидной потребность в создании методов, интегрирующих мультимодальные данные, для более полного и точного понимания эмоциональной окраски. Предложенный в статье метод объединяет текстовые, аудио- и видеоданные, что способствует более глубокому анализу и повышает точность сентимент-анализа. Такой подход включает анализ широкого спектра данных – от текста до видео, что помогает создавать объективную картину эмоционального отношения к продукции, услугам или деятельности организации, что, в свою очередь, важно для принятия обоснованных управленческих решений, направленных на повышение удовлетворенности клиентов.
Целью исследования является разработка метода мультимодального сентимент-анализа. Этот метод интегрирует данные из различных каналов: текст, аудио и видео – для создания более глубокого и точного анализа эмоциональной окраски информации. Метод предназначен для интеграции в системы поддержки принятия решений, что не только позволит организационным системам эффективнее реагировать на изменения в настроениях и предпочтениях клиентов, но и обеспечит более обоснованное и стратегическое планирование.
Материал и методы исследования
Данное исследование фокусируется на методах сбора данных из различных источников, включая социальные сети, подкасты, телевизионные программы, а также видео- и аудиозаписи. Используются методы очистки и унификации для каждого типа данных (текст, аудио и видео), что необходимо для подготовки данных к дальнейшему анализу. Применяются специализированные методы и модели для каждого типа данных.
• Для видеоданных используется сверточная нейронная сеть (convolutional neural network, CNN) ResNet-50 для обработки визуальной информации и выявления эмоциональных сигналов.
• Для аудиоданных применяются такие методы, как спектральное преобразование и последующая обработка с использование LSTM (Long-Short-Term-Memory), одной из разновидностей рекуррентных нейронных сетей (англ. recurrent neural network, RNN), для выявления эмоциональных нюансов в речи.
• Для текстовых данных используется трансформер BERT (Bidirectional Encoder Representations from Transformer) для извлечения текстовых признаков, учитывающих контекстуальные связи.
Для классификации эмоциональной окраски был разработан мультимодальный подход, в основе которого лежит агрегация признаков из различных источников. Этот процесс включает в себя обучение модели на основе метода опорных векторов (англ. support vector machine, SVM), классификацию сентиментов и последующую оценку эффективности полученной модели.
Результаты исследования и их обсуждение
Шаг 1: Сбор данных
Сбор данных является первым этапом любого метода сентимент-анализа. Этот процесс включает в себя отбор данных, который может существенно различаться в зависимости от объектов исследования, платформ, на которых они размещены, и конечной цели анализа. Этот этап подразумевает многогранный подход к сбору данных, охватывающий текст, аудио и видео, что позволяет получить комплексное представление о передаваемых эмоциях.
• Текстовые данные – в зависимости от задачи текстовые данные могут быть собраны из социальных сетей, агрегаторов новостей, форумов, блогов и транскриптов аудио и видео.
• Аудиоданные – сбор аудио может включать, например, аудиодорожки подкастов, интервью и телевизионных программ, где звук является ключевым каналом передачи информации.
• Видеоданные – как и аудио, видеоматериалы собираются из различных источников, используются инструменты для извлечения как визуальной информации, так и аудиокомпонента.
Далее каждый собранный набор данных подвергается предварительной обработке и очистке для извлечения релевантной информации.
Шаг 2: Предобработка данных и извлечение признаков
Для эффективного сентимент-анализа важен тщательный процесс предобработки данных, который включает ряд специфических методов и инструментов для каждого типа данных. Этот шаг критичен, так как качество и достоверность входных данных напрямую влияют на результаты анализа.
Предобработка и извлечение признаков из видеоданных
Процесс предобработки и извлечения признаков из видеоряда, представленный на рисунке 1, осуществляется с использованием сверочной нейронной сети ResNet-50, которая может эффективно обрабатывать визуальные признаки, связанные с эмоциональными проявлениями в видео [9].
Изначально видеоряд разделяется на отдельные кадры, которые затем масштабируются до стандартных размеров входа для ResNet-50 и подвергаются нормализации цветовых каналов. Далее каждый кадр подается на вход модели ResNet-50 для получения вектора признаков. Эта модель глубокого обучения была предварительно обучена на большом наборе данных изображений [10] и способна выявлять сложные визуальные паттерны, что делает ее применимой для извлечения эмоциональных сигналов из видеоряда. Следующий шаг – агрегация признаков из отдельных кадров путем усреднения векторов признаков по всем кадрам:
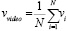 ,
,
где vi – вектор признаков i-го кадра, N – количество кадров в видео.
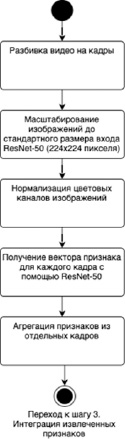
Рис. 1. Предобработка и извлечение признаков из видеоряда с использованием архитектуры сверочной нейронной сети ResNet-50
Предобработка и извлечение признаков из аудиоданных
Аудиоданные требуют отдельного набора техник предобработки и извлечения признаков в целях подготовки звуковой информации для анализа и классификации. На рисунке 2 представлен подход, основанный на использовании рекуррентных архитектур как LSTM [11], которые хорошо подходят для обработки временных последовательностей. Такие сети способны улавливать зависимости в аудиоданных, что важно для распознавания эмоциональных нюансов в речи. Например, повышение тональности и ускорение речи могут сигнализировать о волнении или стрессе, а более медленная и монотонная речь может указывать на грусть или усталость.
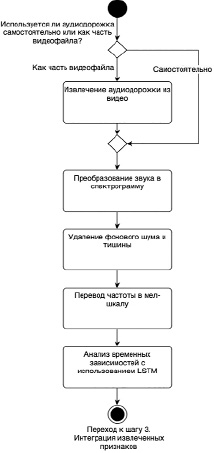
Рис. 2. Предобработка и извлечение признаков из аудиоряда с использованием рекуррентной архитектуры LSTM
Для преобразования звука в спектрограмму используется преобразование Фурье для перевода временной последовательности аудиосигнала в частотное представление:
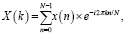
где X(k) – спектральные компоненты аудиосигнала, x(n) – амплитуды звуковой волны в дискретные моменты времени, N – общее количество точек в анализируемом фрагменте.
Для большей чувствительности к частотам, близким человеческому уху, частота переводится в мел-шкалу:
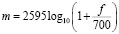
где m – частота в мелах, число 2595 используется для приближения линейного восприятия частоты звука человеческим ухом в мелах, f – значение частоты в герцах.
Далее (мел-спектрограммы) входные данные подаются на вход LSTM-слоям [12], которые обрабатывают аудиопоследовательность, сохраняя информацию о предыдущих состояниях для определения текущего состояния эмоций:
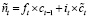
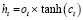 ,
,
где ct и ht – состояние ячейки и скрытое состояние ячейки в момент времени t, ft , it , ot – вентили «забывания» входа и выхода LSTM.
Эти этапы позволяют извлекать эмоциональные признаки из аудиоряда (vaudio), которые затем используются для сентимент-анализа с учетом интеграции между другими типами данных.
Предобработка и извлечение признаков из текстовых данных
Текстовые данные требуют комплексного подхода к предобработке, чтобы преобразовать сырые тексты в формат, пригодный для машинного обучения и анализа. На рисунке 3 представлены основные этапы предобработки текстовых данных и извлечения признаков с помощью модели BERT:
В случае если текстовые данные извлекаются из аудиофайла, то проводится транскрибация с помощью модели Whisper: сначала модель преобразует входящий аудиосигнал в спектрограмму для анализа аудио на уровне частотных компонентов, затем Whisper идентифицирует слова и фразы в аудио, учитывая контекст речи. В конечном итоге, на основе распознанных слов или фраз модель формирует текстовую транскрибацию.
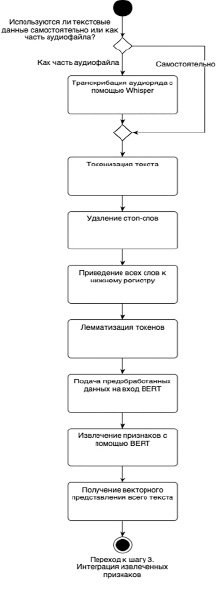
Рис. 3. Процесс предобработки и извлечения признаков из текстовых данных
Далее текстовые данные подвергаются процессу обработки – текст разбивается на токены (на уровне слов), исключаются стоп-слова, которые не несут смысловой нагрузки (союзы, частицы, местоимения, междометия, предлоги, вводные слова и знаки препинания). Для унификации и уменьшения размерности входных данных все слова приводятся к нижнему регистру и приводятся к их словарным формам (леммам).
После процесса предобработки данные подаются на вход модели BERT [13, 14], где она преобразует каждый токен в векторы, кодирующие контекстуальные связи между словами. BERT использует «механизмы внимания», что позволяет сконцентрироваться модели на релевантных словах. Полученные векторы представляют собой эмбеддинги слов, содержащие информацию не только о самом слове, но и о его контексте в рамках текста. Для получения единого векторного представления всего текста используется метод взвешенного усреднения:
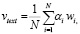
где v – итоговый вектор всего текста, N – количество слов в тексте, αi – вес, отражающий важность i-го слова, wi – вектор i-го слова.
Шаг 3: Интеграция извлеченных признаков
Полученные векторные представления из различных типов данных (видео, аудио и текста) комбинируются для создания единого представления. Это позволяет учесть комплексное взаимодействие между разными типами данных, что важно для точного анализа эмоций. Сама интеграция может быть реализована путем взвешенного сложения. Это один из наиболее простых подходов, где каждый набор признаков умножается на заданный вес, который отражает его значимость, и суммируется с другими для получения единого представления:
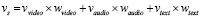
Шаг 4: Классификация сентимента
Мультимодальный подход к классификации сентимента основан на использовании метода опорных векторов, который способен эффективно работать с высокоразмерными данными. Этот этап начинается с нормализации данных для выравнивания диапазона признаков, что предотвращает искажение результатов из-за атрибутов с более высокими значениями. Для реализации мультимодального подхода к классификации сентимента были использованы современные программные библиотеки, включая torch, librosa, numpy, OpenCV, sklearn, transformers и whisper. Эти инструменты обеспечили комплексную обработку данных – от извлечения признаков до обучения и валидации моделей.
Модель обучалась и тестировалась на данных из датасета eNTERFACE [15], который содержит большую коллекцию из 1252 эмоциональных выражений 42 актеров в видеоформате на английском языке. Актеры представляют 14 различных национальностей, при этом мужчины составляют 81%, а женщины – 19%.
Для анализа использовались признаки, извлеченные из трех модальностей данных:
• для видеоряда – признаки лица и жестов;
• для аудиоряда – звуковые характеристики, такие как тембр и энергия в частотных диапазонах, извлеченные с помощью мел-кепстральных коэффициентов (англ. mel-frequency cepstrum, MFCC);
• для текста – лингвистические и семантические особенности (контекстуальная связанность, семантическое отношение между словами и синтаксические зависимости), извлеченные с помощью модели BERT.
Чтобы минимизировать риски переобучения, модель использует различные методики, включая регуляризацию в SVM и дропаут в модели BERT при извлечении текстовых признаков. Для проверки устойчивости и обобщающей способности модель применяет кросс-валидацию, что позволяет оценить модель на различных подвыборках данных, тем самым минимизируя риск переобучения и гарантируя более надежную оценку производительности модели. Производительность модели оценивалась с помощью следующих метрик (табл. 1):
• Precision (точность) – доля правильно идентифицированных объектов среди всех объектов.
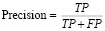
• Recall (полнота) – отношение верно классифицированных объектов класса к общему числу элементов этого класса.
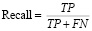
• Accuracy (общая точность) – доля всех правильно классифицированных случаев.
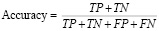
• F1-score (F1-мера) – гармоническое среднее между точностью (precision) и полнотой (recall).
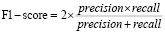
Таблица 1
Классификационные исходы
|
Принадлежит классу (P) |
Не принадлежит к классу (N) |
|
|
Предсказана принадлежность классу |
True positive (TP) |
False positive (FP) |
|
Предсказано отсутствие принадлежности к классу |
False negative (FN) |
True negative (TN) |
Таблица 2
Сравнительная характеристика мультимодальной модели сентимент-анализа с традиционными одномодальными подходами
|
Метод |
Avg. precision |
Avg. recall |
Avg. accuracy |
Avg. F1-score |
|
Мультимодальная модель SVM |
0.92 |
0.90 |
0.91 |
0.91 |
|
SVM (текстовые данные) |
0.85 |
0.87 |
0.86 |
0.86 |
|
Наивный байесовский классификатор (текстовые данные) |
0.85 |
0.86 |
0.85 |
0.85 |
|
BERT (текстовые данные) |
0.83 |
0.89 |
0.89 |
0.86 |
Эффективность мультимодальной модели сравнивалась с другими популярными методами сентимент-анализа, такими как наивный байесовский классификатор, классификация текстовых данных с помощью SVM и текстовый анализ с использованием BERT. Для обеспечения корректности сравнения все методы, включая мультимодальную модель, наивный байесовский классификатор и анализ с использованием BERT, были обучены и провалидированы на одних и тех же данных. В таблице 2 представлено сравнение усредненных по классам метрик производительности различных методов.
Эти данные демонстрируют, что мультимодальный сентимент-анализ имеет преимущества над традиционными одномодальными подходами, что отражается в повышении всех ключевых метрик производительности.
Заключение
В данной статье представлен метод мультимодального сентимент-анализа, который комбинирует данные из текста, аудио и видео. Такой подход позволяет комплексно анализировать эмоциональный контекст, обогащая анализ за счет использования различных каналов информации. Мультимодальный сентимент-анализ позволяет воспроизвести более полную картину эмоциональных реакций, которые могут остаться незамеченными при использовании традиционных одномодальных подходов.
В настоящей статье были рассмотрены методы глубокого обучения, такие как сверточные и рекуррентные нейронные сети, которые являются эффективными инструментами для извлечения признаков из каждого типа данных. Использование CNN и RNN позволяет обрабатывать и анализировать большие объемы данных, что также важно в контексте обработки мультимодального сентимент-анализа.
В завершение отметим, что использование мультимодального подхода показывает большую эффективность по сравнению с одномодальными подходами и открывает новые возможности для разработки более чувствительных к эмоциональному контексту методов, способствуя повышению точности и скорости принятия решений в организационных системах.
Библиографическая ссылка
Фазульянов Д.В., Гусева А.И. РАЗРАБОТКА МУЛЬТИМОДАЛЬНОГО МЕТОДА СЕНТИМЕНТ-АНАЛИЗА ДЛЯ ПОДДЕРЖКИ ПРИНЯТИЯ РЕШЕНИЙ В ОРГАНИЗАЦИЯХ // Современные наукоемкие технологии. 2024. № 5-2. С. 313-320;URL: https://top-technologies.ru/en/article/view?id=40045 (дата обращения: 23.06.2026).
DOI: https://doi.org/10.17513/snt.40045