


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
DEVELOPMENT OF GENERALIZED QUERY TIME CALCULATION MODEL USING EXPRESS AND FASTAPI WEBAPPLICATIONS

В контексте современных информационных технологий время отклика сервера является определяющим фактором в производительности веб-приложений. С учетом того, что пользователи предполагают мгновенный доступ к данным, задержки в загрузке могут существенно снизить их удовлетворенность от использования продукта. Это крайне негативно сказывается на позиции веб-сайта в результатах поисковой системы и его конкурентоспособности на рынке. В эпоху цифровизации, когда время приобретает особую ценность, оптимизация скорости загрузки становится ключевым аспектом для обеспечения потребностей пользователей и сохранения конкурентных преимуществ. Активное развитие сетей и методов передачи информации способствует повышению скорости клиент-серверных взаимодействий и положительно влияет на общую производительность веб-приложений.
В рамках улучшения производительности веб-приложений исследователи и разработчики применяют множество методов оптимизации. Эти методы охватывают широкий спектр подходов, включая программную оптимизацию исходного кода, выбор и использование передовых технологий, а также улучшение архитектуры и компонентов веб-приложений [1]. Однако, несмотря на разнообразие доступных методик, существует затруднение в получении точных количественных показателей, которые бы отражали изменение производительности в прямой зависимости от внедряемых технологических решений. Это обусловлено множеством переменных, влияющих на производительность, и сложностью их изолированного анализа в контексте реальных условий эксплуатации веб-приложений.
В представленной работе описывается методология для вычисления общего времени HTTP-запроса, основанная на комплексном анализе тестовых данных, полученных в разнообразных условиях. Данный метод предоставляет возможность гибкого расчета временных параметров запроса для различных системных конфигураций и может быть модифицирован для применения в специфических системах. Это достигается за счет внедрения гибкой структуры, позволяющей интегрировать дополнительные составляющие, возникающие в ходе реализации конкретных веб-приложений.
Цель исследования – разработка унифицированной модели для расчета полного времени HTTP-запроса в клиент-серверной архитектуре.
Материалы и методы исследования
Веб-приложение состоит из клиентской и серверной части. Подавляющее большинство запросов между ними осуществляется посредством протокола HTTP, обеспечивающего обмен данными путем отправки запроса от клиента к серверу и последующим получением ответа от сервера клиентом [2].
На более низком уровне запрос можно разделить на большее количество этапов. Например, на сервере запрос может проходить через широкий ряд компонентов: веб-сервер, программная платформа, библиотеки, база данных.
В частном случае, который будет рассмотрен в этой статье, запрос можно представить в следующем виде:
1. Клиент отправляет HTTP-запрос к веб-серверу, который представляет собой приложение, написанное на JavaScript или Python с использованием Express или FastApi соответственно.
2. Веб-сервер принимает запрос и обращается к СУБД PostgreSQL или MongoDB для получения данных.
3. СУБД возвращает данные приложению, которое в свою очередь отправляет эти данные обратно клиенту.
В расчете времени запроса клиентская часть рассматривается в качестве вывода полученной информации с сервера и не учитывается как фактор, оказывавший влияние на скорость получения ответа от сервера.
Таким образом можно выделить компоненты системы, которые оказывают влияние на общее время запроса:
1. Время работы обработки запроса веб-сервером, включая программную платформу, библиотеки и другие компоненты. Обозначим его как «базовое время».
2. Время обращения к СУБД. Обозначим его как «время СУБД».
3. Время передачи запроса по сети. Обозначим его как «время сети».
В ходе данного исследования были выдвинуты следующие гипотезы:
1. Каждую из этих компонент можно рассматривать как математическую функцию, принимающую аргументы, необходимые и достаточные, в рамках данной модели, для дифференциации запроса.
2. Суммой этих функций является результирующая функция, отражающая общее время запроса.
3. Все компоненты результирующей функции независимы друг от друга.
В качестве аргументов, достаточных для исследуемой модели, функции, были выбраны количество запрашиваемых сущностей и размер одной сущности. Таким образом была сформирована следующая результирующая функция (1) для расчета времени запроса:
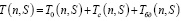 , (1)
, (1)
где n – количество запрашиваемых сущностей;
S – размер одной сущности (байт).
MongoDB и PostgreSQL представляют собой два различных типа баз данных. MongoDB является базой данных NoSQL типа, обладающей гибкой моделью данных. Это достигается за счет того, что все данные хранятся в виде документов JSON, обеспечивая быстрое извлечение, репликацию и анализ данных. В отличие от MongoDB, PostgreSQL является объектно-реляционной базой данных, хранящей данные в виде таблиц с рядами и столбцами. В ходе различных исследований было выявлено, что реляционные системы управления базами данных (СУБД) обычно показывают высокую производительность при выполнении обширных запросов к большим объемам данных, в то время как объектно-ориентированный доступ оказывается более эффективным для малых объемов данных, включая те, которые имеют сложную структуру [3]. Проведение тестирования с использованием этих разных по свойствам работы СУБД позволило получить более широкое представление о специфике их поведения при разной нагрузке [4].
В качестве программных платформ для реализации веб-сервера были выбраны Node.js и Python.
Для веб-сервера на Node.js был использован фреймворк Express, обладающий упрощенной структурой и обеспечивающий обширный набор функциональных возможностей для создания как мобильных, так и веб-приложений. Веб-сервер на Python был разработан с использованием FastAPI. Данный инструмент хорошо подходит для создания высокопроизводительных API и использует библиотеку asyncio для обеспечения асинхронной обработки запросов. Основными его достоинствами являются высокая скорость работы, типизация данных и автоматическая генерация спецификации OpenAPI.
Зачастую работа сервера с реляционными и нереляционными базами данных строится соответственно через ORM и ODM библиотеки [5]. Для работы сервера с базой данных MongoDB на базе Node.js использовалась ODM Mongoose. Для подключения к MongoDB через сервер на FastAPI использовался официальный драйвер Pymongo. В случае с PostgresSQL применялись npm-пакет «pg» для Node.js и «psycopg2» для Python.
Для оценки производительности системы был выбран инструмент ApacheBench, который является утилитой командной строки, предназначенной для тестирования и измерения производительности веб-серверов [6].
Выбор ApacheBench в качестве инструмента для оценки производительности системы основан на следующих преимуществах: возможность тестирования производительности веб-серверов, работающих по протоколу HTTP, возможность генерации и отправки запросов, сбор и обработка данных, анализ и визуализация результатов, генерация и предоставление отчетов и др. [7]. Тестовый клиент ApacheBench был развернут на отдельном сервере с операционной системой Linux, имеющей 1 ядро процессора, 2 ГБ оперативной памяти и 30 ГБ дискового пространства.
Версии технологий, используемых в тестировании, приведены в табл. 1.
На базе Node.js и Express был спроектирован и развернут веб-сервер, обрабатывающий входящие GET-запросы [8]. В качестве ответа на запрос отправлялся список произвольных данных. Для проведения серии тестов были подготовлены абсолютно идентичные списки для всех типов запросов. Список содержал 10000 записей, каждая из которых представляет собой объект с несколькими полями разных типов.
Были проведены серии тестов, представленные в табл. 2.
Тестирование каждой из представленных выше баз данных проводилось в тысячу повторных одиночных GET-запросов для усреднения получаемых данных. В данном исследовании клиент и сервер находились в одной локальной сети. Результаты замеров приведены на рис. 1–3.
На рис. 1 продемонстрирована независимость компонент друг от друга за счет того, что изменение Node.js на Python не оказало влияния на время обращения к PostgreSQL.
Таблица 1
Версии тестируемых технологий
|
Node.js |
Python |
PostgreSQL |
MongoDB |
Express |
PG |
Mongoose |
|
19.8.1 |
3.12 |
16.2 |
7.0.2 |
4.18.2 |
8.11.5 |
8.3.2 |
Таблица 2
Тестируемые конфигурации систем
|
Базы данных |
Среда выполнения |
Фреймворк |
|
PostgresSQL |
Node.js |
Express |
|
Python |
FastAPI |
|
|
MongoDB |
Node.js |
Express |
|
Python |
FastAPI |
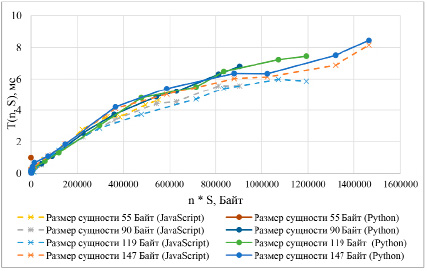
Рис. 1. Результаты расчета СУБД компоненты PostgreSQL
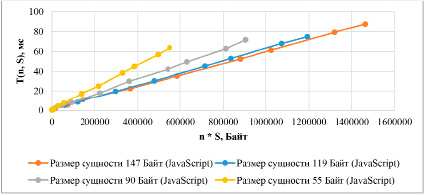
Рис. 2. Результаты расчета СУБД компоненты MongoDB на Node.js
Приведенные рис. 2 и 3 показывают, что время ответа MongoDB прямо пропорционально увеличению количества сущностей и обратно пропорционально размеру сущности. При рассмотрении результатов для PostgreSQL, приведенных на рис. 1, наблюдается явная зависимость времени запроса от произведения количества сущностей на размер сущности. При варьировании значений аргументов с сохранением их произведения не наблюдается закономерного изменения времени запроса. Поскольку функция для расчета времени запроса к MongoDB не может быть выражена как функция одной переменной, в расчетах модели она участвовать не будет, и во всех последующих расчетах в качестве СУБД будет использоваться PostgreSQL.
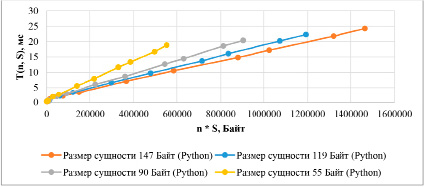
Рис. 3. Результаты расчета СУБД компоненты MongoDB на Python
Также следует отметить, что само время доступа к MongoDB сильно отличается для Node.js и Python ввиду использования концептуально разных библиотек для доступа к БД, поэтому специфика библиотеки будет отражаться на компоненте, отвечающей за время обращения к СУБД.
Результаты исследования и их обсуждение
По результатам замеров были выведены и рассчитаны функции компонент для Node.js (2)–(4) и Python (5)–(7):
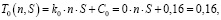 (2)
(2)
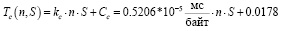 (3)
(3)
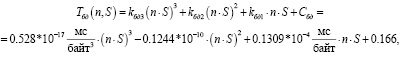 (4)
(4)
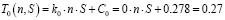 , (5)
, (5)
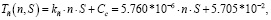 (6)
(6)
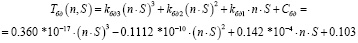 , (7)
, (7)
где С0 – базовая константа (мс/байт);
kc – коэффициент сети (мс/байт);
Сc – константа сети (мс/байт);
kбдп – коэффициент базы данных (мс/байтп);
Сбд – константа базы данных (мс/байт).
После расчета коэффициентов для функций компонент построим результирующие функции для Node.js на рис. 4 и для Python на рис. 5. На рис. 4 и 5 точками обозначены экспериментальные данные, а сплошными линиями рассчитанные функции для выведенной модели.
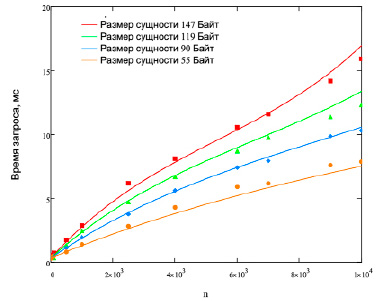
Рис. 4. Результаты сопоставления данных для Node.js
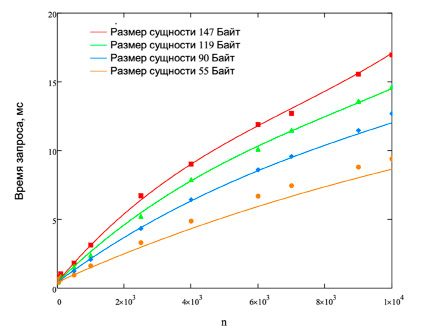
Рис. 5. Результаты сопоставления данных для Python
Заключение
При проведении тестирования было выявлено, что время получения результата от MongoDB зависит от используемой ODM. В том числе фактическое использование ODM увеличивает время получения данных в отличие от более низкоуровневых подходов доступа.
При сравнении скорости ответа от PostgreSQL и MongoDB наблюдается явное преимущество первого при числе сущностей до 10000. Другие исследования также демонстрируют преимущество PostgreSQL при больших объемах данных. PostgreSQL отличается независимостью времени запроса от числа запрашиваемых сущностей, в отличие от MongoDB, где наблюдается прямая зависимость от количества сущностей и обратная зависимость от размера сущности.
Спроектированная модель на основе гипотез продемонстрировала видимое совпадение экспериментальных и теоретических данных. Также были подтверждены все выдвинутые в рамках исследования гипотезы. В проведенном исследовании была сформулирована и выведена модель расчета времени запроса на основе гипотез. Все выдвинутые гипотезы били экспериментально подтверждены.
Также исследование выявило преимущество PostgreSQL над MongoDB в рамках ограниченной серии тестов. Стоит учитывать, что результаты могут отличаться от разных конфигураций систем и при этом сохранять общую закономерность. Использование ODM для доступа к MongoDB способно снижать скорость получения данных.
Выведенные коэффициенты могут быть использованы для расчетов предполагаемого времени ответа сервера в зависимости от количеств сущностей и объема сущности в байтах. При этом, опираясь на ход теоретических исследований, приведенных в данной статье, формула может быть расширена и пересчитана для специфических конфигураций систем, которые содержат большее число параметров.
Библиографическая ссылка
Кошельков В.С., Грязев Т.А., Соколов М.А., Жуков Н.Н. РАЗРАБОТКА УНИФИЦИРОВАННОЙ МОДЕЛИ ДЛЯ РАСЧЕТА ВРЕМЕНИ HTTP-ЗАПРОСОВ НА ПРИМЕРЕ ВЕБ-ПРИЛОЖЕНИЙ EXPRESS И FASTAPI // Современные наукоемкие технологии. 2024. № 5-1. С. 57-63;URL: https://top-technologies.ru/en/article/view?id=40005 (дата обращения: 02.08.2026).
DOI: https://doi.org/10.17513/snt.40005