


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
RESEARCH OF DEEP LEARNING MODELS FOR TRAFFIC OPTIMIZATION IN VEHICLE-TO-EVERYTHING NETWORKS

Анализ больших массивов текстовых данных является важным направлением машинного обучения. Отдельную роль в обработке текста играют нейронные сети, существенным образом повышающие качество решения стандартных задач классификации текстов и последовательностей, а также снижающие трудоёмкость при работе непосредственно с текстами. В то же время нейронные сети нельзя считать полностью самостоятельным средством решения лингвистических проблем, и они являются не единственным многозадачным математическим аппаратом [1, 2]. Известно, что [3] для решения лингвистических задач в условиях неопределенности (размытости), поиска возможностей применения в вычислительных системах может применяться аппарат, основанный на нечёткой логике. В рамках данной статьи рассмотрены различные подходы к решению задачи кластеризации отзывов пользователей к товарам интернет-магазина, представлен разработанный прототип системы, определяющей эмоциональную составляющую текста на примере отзыва пользователей. К научной новизне можно отнести разработку модели оценивания эмоциональной окраски отзывов на основе нечёткой логики в условиях размытости входных данных в задачах кластеризации отзывов покупателей, обеспечивающей путём введения дополнительных входных данных, например длины текста и количества иных эмоционально окрашенных знаков препинания, повышение корректности входных значений экспертов.
Целью выполненного исследования является разработка модели оценивания эмоциональной окраски отзывов на основе нечёткой логики в условиях размытости входных данных в задачах кластеризации отзывов покупателей.
На данный момент существует большое количество решений для классификации отзывов. Например, подобные решения могут выделять среди отзывов положительные, нейтральные и отрицательные [4]. Однако классификаторы ограничены в количестве возможных категорий отзывов. Тем не менее для пользователя может быть полезно рассмотреть для каждого товара самые часто встречающиеся темы, поднимаемые в отзывах. Для этого необходимо выделять не заданные заранее категории, а кластеры, которые могут отличаться для каждого товара. Например, в отзывах к ноутбуку такая система сможет выделить следующие кластеры: «плохая система охлаждения», «хороший процессор», «достаточный объём встроенного жёсткого диска». Если мнения пользователей по какому-то вопросу расходятся, то система может выделить отдельные кластеры, такие как «хорошая видеокарта», «непроизводительная видеокарта». Система выводит в пользовательский интерфейс перечень кластеров с самыми явными примерами отзывов для каждого кластера.
Обзор методов анализа текста в контексте рассматриваемой задачи. Наиболее часто применяемыми для анализа текста являются рекуррентные нейронные сети (RNN) [5]. Идея RNN заключается в последовательном использовании информации, что отличает их от традиционных нейронных сетей, в которых подразумевается, что все входы и выходы независимы. Очевидно, что, если необходимо предсказать следующее слово в предложении, лучше учитывать предшествующие ему слова. RNN и называются поэтому рекуррентными, потому что они выполняют одну и ту же задачу для каждого элемента последовательности, причем выход зависит от предыдущих вычислений. Рекуррентные сети могут использовать «память», учитывающую предшествующую информацию и благодаря этому могут использовать данные в произвольно длинных последовательностях, но, как показывает практика, это ограничивается лишь несколькими шагами [6]. Трудность применения рекуррентной сети заключается и в том, что при учете каждого шага времени существенно увеличивается вычислительная сложность, так как в этом случае становится необходимым для каждого шага времени создавать свой слой нейронов. Но такие многослойные реализации оказываются вычислительно неустойчивыми, так как в них, как правило, исчезают или, наоборот, зашкаливают веса, а если ограничить расчёт фиксированным временным окном, то полученные модели не будут отражать долгосрочных трендов. Для обучения систем долговременным зависимостям применяют сети с долгой краткосрочной памятью (LSTM) [6], которая представляет собой особую разновидность архитектуры рекуррентных нейронных сетей, способная к обучению долговременным зависимостям. Они хорошо решают подобные задачи и в настоящее время широко используются. В такой сети повторяющийся модуль состоит не из одного слоя, а из четырёх слоев и ключевым компонентом является состояние ячейки (cell state). Таким образом, LSTM разработаны специально, чтобы избежать проблемы долговременной зависимости, и запоминание информации на долгие периоды времени – их характерное поведение. Эти особенности выделяют LSTM среди других методов анализа текста и делают их крайне удобным инструментом для лингвистического анализа [7].
Применение нечёткой логики для анализа текста. Использованию нейронных сетей для анализа текста посвящено множество исследований, это направление искусственного интеллекта и математической лингвистики активно развивается, но тем не менее нейронные сети являются не единственным многозадачным математическим аппаратом [2, 8]. Известно, что [3] для решения лингвистических задач в условиях неопределенности (размытости), поиска возможностей применения в вычислительных системах может применяться аппарат, основанный на нечёткой логике [3]. При кластеризации отзывов важно выделить эмоциональную составляющую каждого отзыва. Модель нечёткой логики, позволяющая связать обычные человеческие рассуждения с математическими законами, может оказаться полезной для данной задачи. В рамках следующего раздела будет разработан прототип системы, определяющей эмоциональную составляющую текста, на основе такой модели. Прототип будет протестирован на реальных данных, после чего будут определены дальнейшие шаги для совершенствования модели.
Применение нечёткой логики для анализа текста. Разработка модели. Использованию нейронных сетей для анализа текста посвящено множество исследований, это направление искусственного интеллекта и математической лингвистики активно развивается, но тем не менее нейронные сети являются не единственным многозадачным математическим аппаратом [2, 8, 9]. Для исследования рассуждений в условиях нечёткости, размытости, сходных с рассуждениями в обычном смысле, и поиска возможностей их применения в вычислительных системах может применяться аппарат, основанный на нечёткой логике [3]. При кластеризации отзывов важно выделить эмоциональную составляющую каждого отзыва. Модель нечёткой логики, позволяющая связать обычные человеческие рассуждения с математическими законами, может оказаться полезной для данной задачи. Далее рассмотрим разработку прототипа системы, определяющей эмоциональную составляющую текста, на основе такой модели. Прототип был протестирован на реальных данных, после чего были определены дальнейшие шаги для совершенствования модели.
Важной составляющей выделения кластеров для отзывов является определение эмоциональной окраски отзыва. Разрабатываемая модель предназначена для определения эмоциональности отзыва, а также степени удовлетворённости товаром. Входные параметры: процент слов с положительной эмоциональной окраской, процент слов с отрицательной эмоциональной окраской, процент восклицательных знаков. Выходные параметры: степень эмоциональности отзыва и степень удовлетворённости пользователя товаром. В качестве основы была выбрана модель нечёткой логики. Такая математическая модель позволяет формализовать человеческие рассуждения, что уместно при оценке эмоциональной составляющей текста. Для реализации модели выбрано приложение FisPro. На первом этапе выбраны функции принадлежности, их описание представлено в табл. 1 и 2.
На следующем этапе (рис. 1) определены правила соответствия входных значений выходным.
Описание архитектуры системы, тестирование модели. Общий алгоритм работы системы представлен на рис. 2.
На вход системы поступает текст отзыва к товару. Далее программный модуль на языке Python при помощи пакета pymorphy2 [10] приводит все слова текста к начальной форме.
Таблица 1
Функции принадлежности для входных значений
|
Переменная |
Терм |
Функция |
Параметры |
|
Процент слов с положительной эмоциональной окраской Процент слов с отрицательной эмоциональной окраской |
Мало |
Sinus |
S1 = -5, S2 = 5 |
|
Средне |
Gaussian |
Mean = 12, St. deviation = 4 |
|
|
Много |
Semi trapezoidal sup. |
S1 = 15, S2 = 30, S3 = 100 |
|
|
Процент восклицательных знаков |
Отсутствуют |
Discrete |
Value = 0 |
|
Присутствуют |
Trapezoidal |
S1 = 0, S2 = 5, S3 = 10, S4 = 15 |
|
|
Много |
Semi trapezoidal sup |
S1 = 10, S2 = 30, S3 = 100 |
Таблица 2
Функции принадлежности для выходных значений
|
Переменная |
Терм |
Функция |
Параметры |
|
Степень эмоциональности отзыва |
Неэмоциональный |
SinusInf |
S1 = 0, S2 = 0.5 |
|
Средне |
Sinus |
S1 = 0, S2 = 1 |
|
|
Очень эмоциональный |
SinusSup |
S1 = 0.5, S2 = 1 |
|
|
Степень удовлетворённости товаром |
Не удовлетворён |
SinusInf |
S1 = 0, S2 = 0.5 |
|
Частично удовлетворён |
Sinus |
S1 = 0, S2 = 1 |
|
|
Не удовлетворён |
SinusSup |
S1 = 0.5, S2 = 1 |
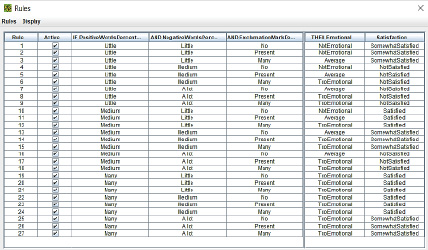
Рис. 1. Настройка правил в FisPro

Рис. 2. Общий алгоритм работы модели
Для определения эмоциональной окраски каждого слова используется датасет kartaslovsent.csv, содержащий тональный словарь русского языка, этот датасет имеет 46127 записи и распространяется по лицензии CC BY-NC-SA 4.0, позволяющей свободно использовать его в личных, научных, исследовательских и любых других целях, не подразумевающих получения дохода коммерческим путём [11]. На выходе данный модуль выдаёт номер отзыва, долю восклицательных знаков, а также доли положительных и отрицательных слов.
Для проверки модели были взяты 15 отзывов c сайта Яндекс.Маркет к смартфону Redmi Note 10 Pro: отзывы № 1–5 на 5/5, отзывы № 6–10 на 1/5, отзывы № 11–15 на 3/5. В результате обработки текста первым модулем были получены результаты, представленные в табл. 3, там же представлена реакция на входные данные (эмоциональность и удовлетворение).
Из полученных результатов следует, что в среднем значение удовлетворённости автора отзыва товаром было определено следующим образом: для отзывов на 5/5: 0,75, для отзывов на 3/5: 0,61, для отзывов на 1/5: 0,47.
Таблица 3
Входные данные для модели и результат работы прототипа модели
|
№ |
Восклицательные знаки |
Положительные слова |
Отрицательные слова |
Эмоциональность |
Удовлетворение |
|
1 |
0,00 |
0,09 |
0,00 |
0,20 |
0,80 |
|
2 |
0,20 |
0,05 |
0,04 |
0,78 |
0,62 |
|
3 |
0,00 |
0,12 |
0,00 |
0,18 |
0,82 |
|
4 |
0,00 |
0,42 |
0,00 |
0,83 |
0,83 |
|
5 |
0,22 |
0,06 |
0,03 |
0,78 |
0,68 |
|
6 |
0,00 |
0,12 |
0,09 |
0,50 |
0,50 |
|
7 |
0,00 |
0,04 |
0,04 |
0,31 |
0,50 |
|
8 |
0,06 |
0,09 |
0,08 |
0,80 |
0,50 |
|
9 |
0,00 |
0,15 |
0,04 |
0,36 |
0,64 |
|
10 |
0,00 |
0,00 |
0,09 |
0,20 |
0,20 |
|
11 |
0,00 |
0,13 |
0,03 |
0,28 |
0,72 |
|
12 |
0,00 |
0,13 |
0,00 |
0,18 |
0,82 |
|
13 |
1,00 |
0,06 |
0,06 |
0,77 |
0,50 |
|
14 |
0,00 |
0,09 |
0,05 |
0,50 |
0,50 |
|
15 |
0,00 |
0,08 |
0,05 |
0,50 |
0,50 |
В результате исследования разработан прототип модели оценки эмоциональной окраски отзывов на основе математического аппарата нечёткой логики. Проверка модели на реальных данных подтвердила возможность применения аппарата нечёткой логики в задачах кластеризации отзывов покупателей в условиях размытости входных данных. Выяснилось, что параметры функций принадлежности для входных значений экспертами неосознанно завышаются. Была проведена оптимизация данных значений в сторону смещения параметров в меньшую сторону. Недостатком модели остаётся некорректное определение эмоциональности текста при небольшом количестве восклицательных знаков. Данная проблема может быть устранена путём введения дополнительных входных данных, например длины текста и количества иных эмоционально окрашенных знаков препинания. Альтернативным способом решения данной проблемы является увеличение количества термов для входных и выходных данных. Кроме того, можно заметить завышенные показатели удовлетворённости для отрицательных отзывов. Наиболее вероятно, данная проблема вызвана некорректным определением положительно и отрицательно окрашенных слов на подготовительном этапе. В дальнейшем предполагается совершенствование модели, в частности планируется определить дополнительные входные переменные, оценить их влияние на точность модели, выделить дополнительные термы для входных и выходных данных, также представляется перспективным применение методов машинного обучения для настройки коэффициентов функций принадлежностей.
Библиографическая ссылка
Поздняков М.В., Осипов Н.А., Зудилова Т.В., Ананченко И.В., Иванов С.Е. ОЦЕНИВАНИЕ ЭМОЦИОНАЛЬНОЙ ОКРАСКИ ТЕКСТА ПРИ ПОМОЩИ НЕЧЁТКОЙ ЛОГИКИ // Современные наукоемкие технологии. 2022. № 10-1. С. 32-36;URL: https://top-technologies.ru/en/article/view?id=39342 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.39342