


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
Analysis of legal information by applied means when using vba scripts

Сегодня невозможно представить работу любого направления деятельности человека без обработки и анализа текстовой информации. В частности, правовой информации в социально значимых сферах – таких как медико-социальная экспертиза (далее – МСЭ) и реабилитация и абилитация инвалидов (далее – РиАИ).
«Социальная защита инвалидов – система гарантированных государством экономических, социальных и правовых мер» [1], что вызывает необходимость своевременно актуализировать, в частности, как правовую систему, так и свод нормативно-правовых актов (далее – НПА). Это диктует определенные требования к скорости внедрения правовых нововведений, качеству проводимых оценок и экспертиз, редакций или юридических нововведений.
Целью данного исследования является определение проблематики при работе с НПА и разработка метода автоматизации анализа правовой информации в областях МСЭ и РиАИ, однако предлагаемый метод не ограничивается применением в названных областях.
Результаты исследования и их обсуждение
Государство каждый год совершенствует работу с инвалидами, но практика показывает, что процессы и итоговые результаты могут не удовлетворять конечного потребителя, вызывая социальные споры, что отражается в судебной статистике, в том числе в делах «О предоставлении гарантий и компенсаций, установленных инвалидам» (таблица).
Исходя из представленных данных, следует, что сохраняется определенная напряженность в сфере правового регулирования вопросов инвалидности и сопровождения лиц с ограниченными возможностями здоровья, что требует качественного нового подхода к обработке и проведению экспертиз правовой информации.
Правовая информация в данной работе рассматривается в рамках контурных потоков информационным [3], который обрабатывается в контуре предприятия с помощью выбранных средств и «публикуется» в преобразованном виде, требующемся для специалистов (рис. 1). Для обработки контурного потока (в рассматриваемом случае, информационный поток предстает в виде текстовой потоковой информации) требуется провести структурирование данных для повышения качества выходного результата.
При решении задачи анализа правовой информации в рамках РиАИ и МСЭ первостепенно стоит учитывать, что для принятия решений о правовых изменениях и внесения изменений в существующие НПА (или при разработке новых НПА) формируются рабочие группы, состоящие из членов экспертных сообществ, где для работы используется пакет Microsoft Office.
Поскольку написание отдельного программного продукта может потребовать много времени и ресурсов, предлагается основываться на указанном выше пакете, использование которого в равных соотношениях взаимосвязывает участников процесса.
Не менее важна общедоступность пакета Microsoft Office. Удобство использования программного продукта также заключается и в том, что перечень, выведенный в формате документов Word и Excel (а также Visio), не требует разработки специальных печатных (в данном случае – отчетных) форм [4]. Также отмечается, что предлагаемый метод и инструмент снизит уровень риска возникновения ситуации работы с разными версиями редакций документа.
Для создания инструмента используется Visual Basic for Applications (далее – VBA), использование которого не требует дополнительных инструментов и сложной дальнейшей настройки.
Судебная статистика [2]
|
Год |
Рассмотрено дел |
Удовлетворено |
Отказано |
Соотношение удовлетворенных к отказам |
|
2018 |
862 |
618 |
244 |
2,53 |
|
2019 |
768 |
559 |
229 |
2,44 |
|
2020 |
797 |
609 |
188 |
3,24 |
|
2021 |
866 |
672 |
194 |
3,46 |
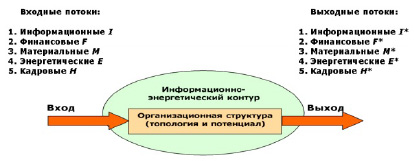
Рис. 1. Схема динамических контурных потоков
«Для автоматизации процесса экспертизы необходимо сформулировать последовательность действий при проведении лингвистической экспертизы и основные маркеры, на которые обращает внимание эксперт при ее проведении» [5]. Основными маркерами могут выступать как отдельные понятия (термины), так и ключевые словосочетания, – данный параметр зависит от конкретной задачи при каждом анализе текста.
«Основная задача подготовки текста – получение максимального количества информации для дальнейшего использования в классификации» [6]. То есть при текстовом анализе важно задать такие параметры, которые давали бы максимально полную и исчерпывающую картину для эксперта(ов), для чего текст следует разделить на смысловые части (блоки).
«На синтаксическом уровне может проводиться декомпозиция не только на словосочетания и предложения, но и на <...> элементарные предикативные структуры, выражающие структуры» [7]. В данном опыте такие структуры именуются фреймами, для эксперимента условно один фрейм принимается за один абзац из НПА (рис. 2). Фреймы могут работать как при оценке синтаксического аспекта, так и при семантическом (с возможным развитием до прагматического, но при использовании более сложных инструментов). Также подход разбития на фреймы способствует структурированию данных (на что было указано ранее), что повышает качество обработки данных.
В программной среде каждый НПА (как новый до принятия, так и уже существующий, поправки к которому могут рассматриваться) разбивается на фреймы, после чего в программной среде можно производить анализ по заданным параметрам (или фильтрам), которые, в зависимости от сферы деятельности, могут разниться и будут утверждаться экспертами.
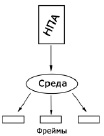
Рис. 2. Разбиение на фреймы (составлено автором)
«В пределах семантического блока <...> существует несколько логико-семантических отношений» [8]. Данные взаимосвязи присущи не только отдельно взятым фреймам. Взаимосвязи строятся и между фреймами, в том числе фреймами разных НПА (рис. 3).
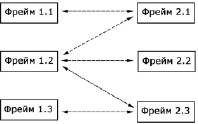
Рис. 3. Условная схема определения взаимосвязей между фреймами (составлено автором)
Технически фреймы представляют собой двумерные массивы данных, которые сравниваются друг с другом по возможным заданным параметрам.
For y = 1 To ActiveDocument.Paragraphs(i).Range.Words.Count
array2(i, y) = ActiveDocument.Paragraphs(i).Range.Words(y)
Next
В качестве экспериментального запуска поставлен фильтр процентного совпадения содержания свыше 50 %.
Собрав оба массива, программная среда (скрипт) сравнивает фреймы между собой (рис. 3) и, если есть совпадения (соответствия заданным параметрам и фильтрам), выведет абзацы соединенными блоками с указанием процента соответствия.
If StrComp(array1(i, j), array2(y, k), 1) = 0 And array2(y, k) <> “ “ Then
percen = percen + 1
array2(y, k) = “ “
End If
Таким образом, формируется форма, пригодная для проведения экспертной оценки (рис. 4).
В приведенном результате отражена обработка двух юридических документов:
1. Федеральный закон от 24.11.1995 № 181-ФЗ (ред. от 28.06.2021) «О социальной защите инвалидов в Российской Федерации».
2. Приказ Министерства труда и социальной защиты Российской Федерации от 13.02.2018 № 86н «Об утверждении классификации технических средств реабилитации (изделий) в рамках федерального перечня реабилитационных мероприятий, технических средств реабилитации и услуг, предоставляемых инвалиду, утвержденного распоряжением правительства Российской Федерации от 30 декабря 2005 г. № 2347-р».
В рамках проводимого опыта сравниваются два НПА друг с другом, но использование программного продукта (или программной среды при полной реализации) подразумевает работу в формате «один – много», т.е. один НПА анализируется (условно сравнивается) с базой или выделенной группой НПА в заданной отрасли.
Данная задача, исходя из механизма работы, может решаться подходом машинного обучения с учителем.
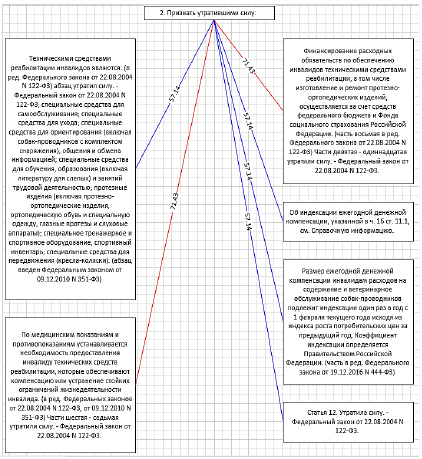
Рис. 4. Форма вывода по заданным параметрам фильтра (создано автором)
Заключение
Данный метод (применений VBA-скриптов на базе пакета Microsoft Office) в разы сокращает поиск ключевых юридических данных, требующих внимания экспертных сообществ.
Предложенный инструмент рассматривается и предлагается в качестве предварительного этапа оценки текста. Выводная информация может быть оценена экспертами:
1. Специалистами в области МСЭ.
2. Специалистами по реабилитации и абилитации инвалидов.
3. Юристами социального и медицинского направлений.
Предлагаемый метод и инструмент позволит многократно ускорить процесс оценки и согласования различных вопросов в рамке действия рабочей группы при работе с правовой информацией. Важной особенностью данного подхода являются доступность и простота в использовании как экспертами, так и аналитиками.
Показанный метод не претендует на исчерпывающий характер и будет доработан в ближайшем будущем. Также будет предложено использование продвинутых интеллектуальных средств обработки текстовой (правовой) информации, включая машинное обучение и нейросети.
При переходе к более сложным моделям и иным средствам достижения результата поставленной задачи, может применяться различный математический аппарат. Варианты будут рассмотрены в последующих работах.
Библиографическая ссылка
Ермолатий Д.А. Анализ правовой информации прикладными средствами при использовании vba-скриптов // Современные наукоемкие технологии. 2022. № 9. С. 22-26;URL: https://top-technologies.ru/en/article/view?id=39303 (дата обращения: 24.07.2026).
DOI: https://doi.org/10.17513/snt.39303