


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
Overview of the Automated Measurement of Technical Debt

Технический Долг (ТД) является одной из новейших концепций, которая была введена в разработку программного обеспечения. Она признает компромисс между качеством кода и необходимостью удовлетворять ожидания участников рынка (например, низкая стоимость, короткое время выхода на рынок и т.д.). Это типичная ситуация для компаний-стартапов, которые имеют строгие требования к тому, чтобы создать минимально жизнеспособный продукт (MVP), чтобы протестировать рынок и получить финансирование для дальнейшего существования. В таких условиях принятие неоптимальных решений, снижающих качество системы, ведущих к созданию стратегических ТД [1], способно стать ключевой стратегией для достижения успеха. В любом случае компании должны понимать, что такие неоптимальные решения требуют дополнительных усилий для исправления продукта в долгосрочной перспективе [2; 3]. Тем не менее создание ТД может быть ценной стратегией, позволяющей вывести продукты на рынок, зная, что этот долг должен быть выплачен (с процентами) в будущем. Это феномен был первоначально описан Уордом Каннингемом в 1992 году [4], введшим понятие ТД. Существует гораздо больше источников ТД, которые были изучены в недавнем времени, включающих в себя коммуникацию, сотрудничество между членами команды, документацией и индивидуальным отношением [5; 6]. Поскольку ТД – это способ измерения усилий, необходимых для достижения наилучшего качества программной системы по сравнению с текущим состоянием, крайне важно иметь возможность измерить (или оценить) его. Важность такой работы доказывается тем простым фактом, что большинство программных проектов имеют некоторый ТД [7]. Возможность оценки ТД позволяет командам разработчиков и руководителям планировать работу должным образом. Может также случиться, что ТД слишком высок для оплаты [8], что требует различных подходов для его разрешения (например, переписывание системы). Однако знание о том, каким образом система достигла этого состояния, может помочь в выявлении ошибок и улучшить процесс разработки. Частые изменения программных артефактов (в основном исходного кода) без соответствующих мер по обеспечению качества быстро приводят к снижению качества программного обеспечения с увеличением затрат на дальнейшую разработку и эволюцию программного продукта в связи с увеличением ТД [9]. Более того, оценка ТД должна выполняться автоматически, чтобы не увеличивать нагрузку на разработчиков и иметь возможность постоянно отслеживать показатель оценки на любом этапе разработки. Это особенно полезно в сочетании с использованием Agile-подходов, поскольку их ориентированный на доставку характер и непрерывная адаптация к потребностям клиента могут быть более предрасположены к возникновению ТД по сравнению с традиционной разработкой программного обеспечения. Однако они также наиболее склонны платить ТД за счет правильной реализации рефакторинга. По всем вышеперечисленным причинам возможность автоматического измерения ТД имеет первостепенное значение для поддержки ежедневной работы разработчиков. В литературе существует множество различных подходов к ТД, и в данной работе представлен обширный анализ, показывающий текущее состояние исследований, расширяя работу тех же авторов в [10]. В данной работе мы расширили анализ, включив в него обширный ряд первичных исследований.
В данной работе исследуются доступные методы оценки ТД с помощью автоматизированных инструментов с целью помочь практикам и исследователям в понимании доступных вариантов и их правильном применении.
Материалы и методы исследования
Протокол, принятый для данного систематического обзора литературы, является протоколом, который был предложен Китченхэмом и Чартерсом [11] для проведения подобных обзоров в области программной инженерии. Основной целью данной работы является обзор существующих исследований и выделение аспектов, связанных с измерением ТД, поэтому мы определили следующие исследовательские вопросы. Вопрос 1: какие существуют методы измерения ТД? Вопрос 2: какие инструменты поддерживают автоматизацию измерения ТД? Вопрос 3: существуют ли эмпирические исследования, способные продемонстрировать полезность выявленных методов? Вопрос 4: существуют ли эмпирические исследования, способные продемонстрировать полезность выявленных инструментов? Чтобы ответить на вопросы исследования, мы провели поиск статей с использованием трех крупнейших электронных библиотек: Цифровая библиотека Ассоциации вычислительной техники (ACM), Полнотекстовая база данных IEEE (The Institute of Electrical and Electronics Engineers,Inc.), и цифровая библиотека Гугл Сколар (Google Scholar). Поскольку для нашей цели интересны только исследования, посвященные ТД как основной теме, мы предполагаем, что их название или аннотация включают ключевые слова «технический долг». Следовательно, мы использовали соответствующие запросы для каждой библиотеки. Мы нашли 1 063 статьи, распределенные следующим образом: Цифровая библиотека Ассоциации вычислительной техники (211), Полнотекстовая база данных IEEE (317), Гугл Академия (535). Как и ожидалось, статьи, найденные в разных библиотеках, значительно пересекались. Поэтому первым шагом было объединение результатов и удаление дубликатов. К концу процесса мы отобрали 46 статей.
Шаг 1: объединение всех документов из источников данных. Первоначальный список включал 1063 статьи, но в нем было много дубликатов. Идентификация дубликатов проводилась вручную, чтобы избежать проблем, связанных с незначительными различиями в символах в названиях и именах авторов. В итоге мы получили список из 835 уникальных статей.
Шаг 2: применение критериев исключения. На данном этапе мы применили критерии исключения, в результате чего было отобрано 524 работы. Здесь мы все еще сохраняли в списке вторичные исследования.
Шаг 3: исключение не первичных исследований. На данном этапе мы определили вторичные исследования (например, систематические обзоры, систематические отображения и т.д.), и список сократился до 452 работ.
Шаг 4: рассмотрение исследований, связанных с измерением ТД. Во время чтения названия и аннотаций 452 статей мы определили работы, касающиеся вопроса измерения ТД. Мы выявили 77 работ, опубликованных в период с 2011 по 2021 год.
Шаг 5: оценка качества. Мы внимательно ознакомились с 77 отобранными работами и исключили 31 из них, поскольку они не касались измерения технического долга, даже если по названию или аннотации они казались подходящими для нашего исследования.
Результаты исследования и их обсуждение
Вопрос 1: какие существуют методы измерения ТД? Выявленные исследования были проанализированы с точки зрения предложенных методик, их требований к исходным данным, необходимым для расчета ТД, получаемой в результате методики информации, преимуществ и недостатков подхода. В табл. 1 суммируются все обнаруженные методы, их входные данные, выходные и расчёт.
Таблица 1
Обнаруженные методы для измерения ТД
|
Метод. Ссылка |
Входные данные |
Расчёт |
Выходные данные |
|
SQALE [12; 13] |
1. Целевой уровень качества (список нефункциональных требований, определяющих правильный код). 2. Модель оценки долга (связь каждого требования функцией исправления, превращает количество несоответствий затраты неисправленные) |
Запустить анализ кода с помощью инструментов анализа и использовать функции исправления, чтобы рассчитать затраты на исправление для каждого элемента. ТД – сумма затрат на исправление всех несоответствий. Этот долг называется индексом качества SQALE (SQI) |
Симптомы дизайна ТД (пирамида-индикатор, представляющий конкретное распределение ТД по восьми характеристикам) |
|
CAST [14] |
1. Количество нарушений, которые следует исправить в приложении. 2. Часы исправления каждого нарушения. 3. Стоимость труда |
((∑крайне тяжелые нарушения) x x (процент для исправления) x (среднее количество часов, необходимых для исправления) x ($ в час)) + + ((∑средние нарушения) x (процент для исправления) x (среднее количество часов, необходимых для исправления) x ($ в час)) + ((∑легкие нарушения) x (процент для исправления) x (среднее количество часов, необходимых для исправления) x ($ в час)) |
Стоимость исправления |
|
SIG [15] |
1. Исходный код. 2. Целевой уровень качества. 3. Стоимость труда |
Для извлечения значений измерений из исходного кода используется SAT от SIG. RE = SS* RA* RF * TF ME = |
1. Стоимость исправления. 2. Стоимость невмешательства |
|
Модель на основе сравнительного анализа [16] |
1. Выходные данные статических анализаторов кода (референсные проекты). 2. Исходный код. 3. Целевой уровень качества. 4. Стоимость рабочей силы |
Поддержка инструмента доступна [17], что облегчает запуск инструментов анализа кода, а также создание базы данных тестов и набора тестов 1. указан целевой уровень качества 2. # максимально допустимых нарушений рассчитывается 3. # исправляемых нарушений рассчитывается 4. # нарушений, подлежащих устранению * расчетное усилие для фиксации* почасовая ставка |
Стоимость устранения |
|
Продолжение табл. 1 |
|||
|
Метод. Ссылка |
Входные данные |
Расчёт |
Выходные данные |
|
Подход к моделированию, основанный на колебаниях [18] |
Облачный мобильный сервис-кандидат |
Количественная оценка ТД в течение первого года
Со второго и далее
|
Относительное количество ТД |
|
Критическая точка для ТД [8] |
1. Количество нарушений, которые следует исправить в приложении. 2. Часы исправления каждого нарушения. 3. Стоимость труда. 4. Прошлые изменения в истории системы (LOC) |
|
1. Стоимость устранения. 2. Стоимость не устранения. 3. Критическая точка ТД |
|
LOC и Fan-In для количественной оценки САТД [19] |
Исходный код |
1. Извлечение комментариев и сопоставление их с соответствующими методами. 2. Определение изменения во времени в этих методах САТД. 3. Определение показателей, измеряющих долю. 4. Расчёт процентов для каждой доли САТД |
Стоимость не устранения |
|
Фреймворк ТД для дизайна [20] |
Исходный код |
1. Выбрать набор актуальных недостатков дизайна. 2. Определить правила для обнаружения каждого дефекта дизайна. 3. Измерить негативное влияние каждого обнаруженного экземпляра дефекта
4. Подсчет общего балла
|
Дизайн симптомы ТД |
|
Схема оценки процента ТД [21] |
Данные активности разработчиков |
1. Запуск собраний. 2. Расчет показателей, связанных с усилием понимания в рамках собраний 3. Статические метрики показывают наличие ТД в классах, метрики позволяют количественно оценить усилия по пониманию классов |
Стоимость не устранения |
|
Окончание табл. 1 |
|||
|
Метод. Ссылка |
Входные данные |
Расчёт |
Выходные данные |
|
Метрики модульности для AТД и прошлые изменения в истории системы (записи фиксации) [22] |
Исходный код |
1. Анализ записи фиксации, чтобы извлечь необходимые элементы данных для расчета ANMCC. 2. Фильтрация данных в записях коммитов
Более высокий ANMCC влечет за собой потенциальное увеличение AТД. 1. Создание карты кода (XML). 2. Парсинг карты кода. 3. Расчет показателей модульности более высокий IPCI или IPGF указывает на меньшее AТД и относительное количество ТД |
Относительное количество ТД |
|
Обнаружение и количественная оценка САТД [23] |
Исходный код |
1. Извлечение данных проекта (используемая версия, количество классов, общее количество строк исходного кода, общее количество извлечённых комментариев и количество участников). 2. Разбор исходного кода и извлечение комментариев к коду. 3. Фильтрация комментариев. 4. Ручная классификация на пять различных типов САТД и количество комментариев (количество отдельных строк, блоков и комментариев Javadoc) |
Относительное количество ТД |
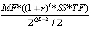
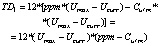
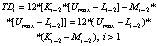
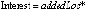
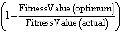
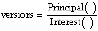
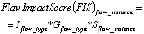
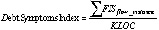
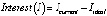
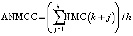
Таблица 2
Вопрос 2: какие инструменты поддерживают автоматизацию процесса измерения ТД?
|
Метод [Источник] |
Инструмент |
Ссылка на инструмент |
Открытый доступ |
|
SQALE [12; 13] |
SonarQube |
sonarqube.org |
+ |
|
MIND |
sourceforge.net/projects/mindyourdebt |
+ |
|
|
FindBugs |
findbugs.sourceforge.net |
+ |
|
|
Точка невозврата для ТД [8] |
JCaliper |
http://se.uom.gr/index.php/projects/jcaliper |
+ |
|
Фреймворк ТД для дизайна [20] |
inFusion |
chocolatey.org/packages/infusion/ |
- |
|
Схема оценки доли ТД [21] |
Blaze monitoring tool |
https://sites.google.com/site/blazedemosite/home/abou |
- |
|
Приоритизация ТД [24] |
Tracy |
- |
- |
|
Автоидентификация, мониторинг и контроль ТД [25] |
VisminerTD |
https://visminer.github.io |
- |
|
Инструмент для управления ТД [26] |
DeepSourse |
https://deepsource.io |
+ |
|
Инструмент для предотвращения в основном невидимого технического долга [27] |
Debtgrep |
- |
- |
|
Инструмент для автоматического определения архитектурных запахов для C / C ++ [28] |
Arcan too |
essere.disco.unimib.it/wiki/arcan |
+ |
|
Инструмент вычисляет наличие набора кода запахов и вычисляет индекс интенсивности [29] |
JCodeOdor |
essere.disco.unimib.it/jcodeodor |
+ |
|
Окончание табл. 2 |
|||
|
Метод [Источник] |
Инструмент |
Ссылка на инструмент |
Открытый доступ |
|
Инструмент для обнаружения запахов кода из кода Java и определения приоритетов технического долга на основе запахов [29] |
JSpiRIT |
- |
- |
|
Инструмент статического анализа кода для конкретной предметной области [30] |
PLC software |
- |
|
|
Инструмент для тактического планирования ТД при использовании гибких методологий [9] |
ProDebt |
- |
- |
|
Среда программирования [31] |
EXA2PRO |
- |
|
|
Метрики модульности для АТД [22] |
TortoiseSVN |
tortoisesvn.net/ |
+ |
|
LOC и Fan-In для количественной оценки СПАТД [19] |
Understand JDeodoran |
scitools.com/github.com/tsantalis/JDeodoran |
- + |
|
Обнаружение и кол. измерение СПАТД [23] |
SLOCCoun |
dwheeler.com/sloccount/sloccount.html |
+ |
Вопрос 3: существуют ли эмпирические исследования, способные продемонстрировать полезность идентифицированных методов? В [32] оценили три метода ([12; 14; 20]), чтобы выяснить, эффективно ли они описывают взаимосвязь между качеством системы и уровнем ТД. Изуриета и др. [33] используют Нугрохо и др. [15] для примера методологии. Модель на основе бенчмаркинга Майра и других [16] тесно связана с их более ранней работой по оценке качества, ориентированной на бенчмаркинг. Также она рассчитывает стоимость устранения недостатков способом, аналогичным подходу CAST [14]. Релевантные метрики структуры кода в структуре для оценки интереса к ТД [21] были выбраны таким образом, чтобы связать сопровождаемость и ТД в [15]. Как и в предыдущей работе, используются статические метрики кода. [34] провели эмпирическое исследование на 21 известном и развитом проекте с открытым исходным кодом, чтобы подтвердить гипотезу об ошибочности применения SonarQube. [35] выбрали четыре различных метода идентификации ТД (запахи кода, проблемы автоматического статического анализа (ASA), накопление кода и нарушения модульности) и применили их к 13 версиям программного обеспечения с открытым кодом Apache Hadoop проекта. Результаты показали, что различные методы ТД слабо связаны между собой и поэтому указывают на проблемы в разных местах исходного кода. Более того, их индикаторы заинтересованности (изменения и дефектность) коррелируют только с небольшим подмножеством индикаторов ТД. В [36] был проведен обзор эмпирических исследований по возникшей теме SATD после 2014 г. и до составления данного обзора в июле 2018 года. Они собрали инструменты и наборы данных, которые могут быть использованы в качестве основы для привлечения и содействия представлению новых и усовершенствованных подходов для управления и в конечном счете погашения САТД. Одновременно авторы отметили отсутствие исследований, посвященных погашению и управлению САТД, что чрезвычайно важно.
Вопрос 4: существуют ли эмпирические исследования, способные продемонстрировать полезность выявленных инструментов? В [37] ТД измерялся с помощью двух инструментов статического анализа кода (Findbugs и SonarQube). Целью было оценить, имеет ли код, созданный с помощью подхода Test Driven Development, более низкий ТД, чем код, созданный с использованием других методов. Эти два инструмента широко используются в сообществе для измерения ТД. Другие исследования тестировали SonarQube: [38] использовали его для измерения ТД в системе слежения за частицами; [39] использовал его для нескольких расчетов ТД в цепочке поставок программного обеспечения; [40] описывает тематическое исследование Ericsson, где они наблюдали за ТД, чтобы использовать их для создания системы оценки на основе стандарта ISO 15939:2007.
Заключение
Технический Долг – это широко используемое популярное выражение. Однако довольно сложно иметь четкое представление о доступных подходах и инструментах из-за большого количества материала. Цель данной работы – предоставить исследователям и практикам обзор состояния дел в области ТД с упором на автоматизированные подходы. Согласно обзору, эта область исследований является новой и активно развивающейся, но все еще незрелой. Постоянно появляются новые подходы и инструменты, которые не основаны на результатах предыдущих исследований, а исследователи сосредоточены на проверке собственных подходов без каких-либо независимых оценок. Более того, такие проверки часто невоспроизводимы из-за использования собственных наборов данных. Поэтому необходимы дополнительные усилия для определения подходов с перекрестной проверкой и четкие указания на их применимость. Это очень важно, особенно для практиков, поскольку им трудно определить, какие модели следует применять в их конкретном контексте. В исследовании также отмечается, что в тех случаях, когда имеются инструменты для поддержки некоторых специфических подходов, они часто тяжелы в использовании, требуют сложной настройки и обеспечивают ограниченную поддержку широкого спектра языков программирования, используемых в реальных проектах. Более того, большинство доступных инструментов не способны измерить или оценить общий ТД. Они обычно сосредоточены на затратах на устранение последствий и не принимают во внимание смежные интересы (часто называемые не восстановительными затратами), которые часто очень важны для планирования процесса разработки и для контролирования долга на протяжении всего жизненного цикла продукта.
Библиографическая ссылка
Хомяков И.А. Обзор Автоматизированного измерения Технического Долга // Современные наукоемкие технологии. 2021. № 11-1. С. 87-94;URL: https://top-technologies.ru/en/article/view?id=38893 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.38893