


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
CLASSIFICATION OF SCANNED DOCUMENTS USING A CONVOLUTIONAL NEURAL NETWORK

Автоматизация документооборота является важным этапом автоматизации производственных процессов предприятия. Одной из задач автоматизации документооборота является классификация документов, при которой программой производится выбор для документа одного из нескольких возможных классов. Наибольшая востребованность для делопроизводства организаций и сложность в обработке возникает для сканированных изображений, поэтому далее под документом будем понимать отдельную страницу.
Для автоматической классификации документов используются два основных метода: классификация страниц по шаблону и классификация с помощью сверточных нейронных сетей. Первый метод заключается в том, что необходимо для каждого вида документа описать шаблон страницы, то есть четко определить расположение текстовых полей и ключевых слов в этих полях. Это требует кропотливого описания шаблонов, а также их модификации при изменении формата документа.
Ускорения процесса можно добиться с использованием машинного обучения. Обзор успешного использования нейронных сетей для решения различных прикладных задач приведен в [1]. В статье [2] представлен двухэтапный подход к обучению и тестированию в реальном времени классификации изображений документов, основанный на использовании компьютерного зрения, с конечной точностью 83,24 %. Работа [3] посвящена повышению эффективности обучения классификаторов на основе областей и их объединения для классификации изображений документов, метод достигает точности в 92,21 %. В [4] предложен подход, основанный на выделении, анализе и объединении текстового и визуального потоков для классификации изображений документов, в визуальном потоке используются глубокие CNN для извлечения структурных особенностей изображений, точность зависит от вида входных данных. В исследовании [5] предлагается двухпоточная нейронная архитектура для выполнения задачи классификации изображений документов, при этом используется подход совместного обучения признаков, объединяющий признаки изображения и текстовые части, подход совместного обучения имеет точность классификации до 97,05 %. Преимуществом использования нейросетевого подхода является отказ от шаблонов. Вместо этого для создания обучающего датасета требуется указать лишь класс документа. Это позволит быстро разметить датасет и при необходимости внести оперативные изменения, что сделает систему гибкой. Обзор решений показывает актуальность задачи повышения точности распознавания при работе системы в режиме реального времени.
Основными требованиями к реализации программного модуля классификации документов является точность и скорость его работы. Цель работы состоит в определении подхода, включающего порядок обработки сканированных документов и архитектуру нейросети, позволяющего классифицировать документы с точностью не ниже 97 % в режиме реального времени.
Входными данными для модуля является pdf-файл сканированного документа (примером документа является акт освидетельствования скрытых работ [6]), выходными данными является xml-файл с классом документа.
Классификация документов с использованием CNN
Исходя из вышеописанного, для классификации документов выбран подход с использованием нейронной сети. Для повышения точности и скорости работы программы были решены задачи по кодированию сигнала для нейронной сети и определению ее структуры.
Анализ факторов [7], влияющих на производительность CNN для обработки изображений документов, позволяет выделить применение сдвиговых преобразований во время обучения и использование больших входных изображений, которые приводят к наибольшему увеличению производительности, достигая показателей на RVL-CDIP с точностью 90,8 %. Для увеличения скорости работы сети и повышения точности классификации были использованы «экспоненциальные линейные модули» – ELU [8], а также использованы слои DropOut[9].
Определен следующий порядок обработки сканированных документов.
1. Выполняется коррекция изображения по гистограмме яркости и по углу поворота. Эти меры должны существенно поднять качество работы Tesseract OCR алгоритма.
2. Выполняется распознавание текстовых полей и их значений. Результат – дескриптор страницы записывается в xml-файл.
3. Для каждого такого дескриптора создается специальная пара изображений (показаны на рис. 1), которые являются входным сигналом для нейросети классификатора и сжимаются до разрешения 128×128 пикселей.


Рис. 1. Пара изображений, сгенерированных для дескриптора
4. Нейросеть классифицирует каждую из страниц-дескрипторов. Причем при обучении этой нейросети вводился специальный класс «неизвестная страница» – страница, которая не относится ни к одному из заданных в датасете типов документов. Нейросеть возвращает целое положительное число, которое является ID класса страницы. Архитектура разработанной нейросети представлена на рис. 2.
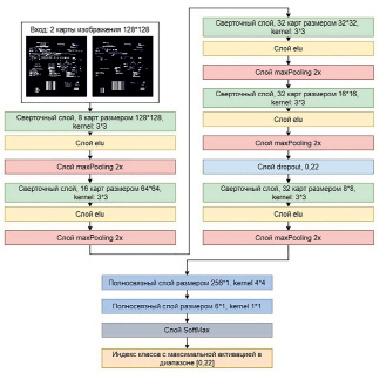
Рис. 2. Архитектура разработанной нейросети
В работах по классификации страниц часто используется значительное уменьшение размера исходного изображения. Такой подход приводит к значительной потере информации, это особенно актуально при наличии мелкого текста. Для преодоления этой проблемы ряд авторов использовали подход формирования признаков из исходного изображения, используя для этого нейросеть и, например, скользящее окно. Признаки компактно описывают модель страницы без значительных потерь информации. Однако они используют дополнительные действия, что усложняет процесс разработки и обучения. Для повышения эффективности предлагается использовать подход по созданию изображений из полученного набора текстовых полей и символов, находящихся внутри них: яркость и координаты пикселя в дескрипторе определяются значением и положением символа на странице. Результат – компактное описание скана страницы практически без потери информации.
Результаты исследования и их обсуждение
Проведено тестирование программного модуля на сканированных документах, таких как акт освидетельствования скрытых работ, акт освидетельствования ответственных конструкций, акт о результатах проверки изделий, акты заключений неразрушающего контроля (радиографический метод). Объем датасета, сформированный из этих документов, составил 9628 страниц. Доля обучающей выборки составила 7702 страницы, доля тестовой выборки – 1926 страниц. В результате обучения была достигнута точность (доля верных ответов) 99,1 % на тестовой выборке (рис. 3). Время обучения составило около 18 с на одну эпоху на видеокарте Geforce GTX 780TI. Время классификации одной страницы без учета чтения файла и копирования в GPU составляет: 2 мс на GeForce 780TI. Время классификации одной страницы с учетом всех этапов обработки документа и записи типа страницы в xml-файл составляет примерно 22,3 мс, что соответствует обработке документов в режиме реального времени.
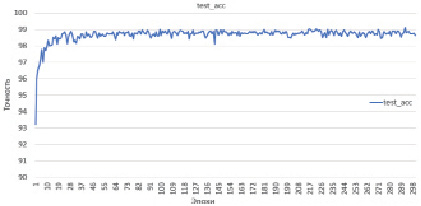
Рис. 3. Доля верных ответов на тестовом наборе в зависимости от эпохи
Заключение
Разработан порядок обработки сканированных документов, архитектура нейронной сети, выполнена программная реализация предложенного решения. Обучение и тестирование нейронной сети подтвердило увеличение точности распознавания по сравнению с представленными решениями. Оценка скорости работы программного модуля позволяет использовать систему в организациях в режиме реального времени. Дальнейшие пути развития системы видятся в следующих направлениях: оптимизация хранения данных, предварительная обработка входных данных для уменьшения количества читаемых файлов, использование базы данных.
Библиографическая ссылка
Котюжанский Л.А., Четверкин Н.В., Протасевич А.А., Кочеров Р.В., Рыжкова Н.Г. КЛАССИФИКАЦИЯ СКАНИРОВАННЫХ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ СВЕРТОЧНОЙ НЕЙРОСЕТИ // Современные наукоемкие технологии. 2021. № 6-1. С. 45-49;URL: https://top-technologies.ru/en/article/view?id=38695 (дата обращения: 10.07.2026).
DOI: https://doi.org/10.17513/snt.38695