



В наше время интернет развивается в быстром темпе. Растет количество информации в сети и количество пользователей. В 2015 г. российская ежемесячная интернет-аудитория выросла на 9,2 % до 80,5 млн пользователей, говорится в докладе Российской ассоциации электронных коммуникаций [9].
Неструктурированные данные составляют большую часть информации, с которой имеют дело пользователи. Поэтому автоматическая кластеризация (выявление похожих по темам текстов) является одной из важнейших задач, решаемых с помощью информационных систем [1].
На рынке программного обеспечения представлено большое количество программ, реализующих классификацию текстов. Российская служба Яндекс.Новости автоматически группирует данные в новостные сюжеты и составляет аннотации этих новостных статей [4].
Для автоматического определения темы используются методы тематического моделирования, которые реализуются с помощью различных алгоритмов.
В статье описано применение методов тематического моделирования для автоматического определения темы новостных статей, взятых с сайта «РИА Новости». Рассмотрены: принцип сбора данных через веб-интерфейс новостного сайта, задача построения тематической модели, два метода латентно-семантического анализа, проведена их алгоритмизация и программная реализация.
Методика сбора данных из новостных сайтов
Веб-интерфейсы новостных статей являются источниками данных реального времени. Для взаимодействия с ними можно использовать Web браузер или специальные приложения. Из-за того что новостные сайты не предполагают возможность сбора данных, то возникает проблема – разная структура данных для разных новостных источников. С другой стороны, это никак не влияет на структуру новостного текста [6].
Изучив ряд новостных источников в сети Интернет, таких как «РИА Новости», РБК, KP.RU и других (по рейтингу их популярности [8], можно представить структуру новостной записи [10]: заголовок – отражает тему новостной статьи, состоит из небольшого набора слов, и основные факты – содержат главную тему, состоит из первых 1 или 2 абзацев текста новости. Оставшийся текст новости, как правило, содержит детали, которые только косвенно связаны с темой новости.
Для извлечения текста новости с веб-страницы новостного сайта существует множество подходов. Ниже представлены три из них, как имеющие большое практическое применение в современных технологиях:
1. Извлечение данных с использованием только html-кода документа. Этот процесс включает три этапа [5].
- Получение исходного кода веб-страницы. В разных языках для этого предусмотрены различные способы. Например, в PHP чаще всего используют библиотеку c URL или же встроенную функцию file_get_contents.
- Извлечение из html-кода необходимых данных. Получив страницу, необходимо обработать её – отделить обычный текст от гипертекстовой разметки, для этого можно использовать регулярные выражения, а также специализированные библиотеки [12].
- Фиксация результата. Полученные данные сохраняются в базе данных или в отдельных текстовых файлах.
2. Извлечение данных с использованием алгоритмов компьютерного зрения. Это точный алгоритм, однако самый сложный и ресурсоемкий. Он включает два этапа:
- Рендеринг страницы. Рендеринг (англ. rendering – «визуализация») – это термин в компьютерной графике, обозначающий процесс получения изображения по модели с помощью компьютерной программы. На этом этапе алгоритм преобразует модель, web-страницу, в изображение.
- Извлечение данных. С помощью алгоритмов компьютерного зрения (англ. Computer Vision) происходит детектирование контента интернет-страницы: текста, картинок и их расположения на странице.
3. Извлечение данных на уровне сайта целиком. С помощью формул и таблиц Google или с помощью дополнительных приложений можно найти на странице необходимый участок кода, в котором заключена необходимая информация. Эти части кода повторяются в пределах одной страницы и на других страницах, имеющих аналогичную структуру. Данный подход помогает выделить и импортировать повторяющиеся данные автоматически, существенно сэкономив время и предупредив возможные ошибки копирования этой информации вручную [7].
Задача построения тематической модели
Тематическая модель – это модель, которая определяет принадлежность документа, из некоторого набора документов к определенной теме.
С математической точки зрения задача классификации текстов по темам сводится к задаче одновременной классификации набора документов по одному и тому же множеству тем [3].
При построении тематической модели, вводится ряд обозначений и предположений.
Пусть D это набор документов, содержащий множество документов d
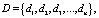
где n – это количество документов в наборе.
Каждый документ d в свою очередь представляет собой множество слов Wd.
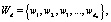
где 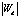 – это количество слов в документе.
– это количество слов в документе.
Каждый документ d имеет тему t, принадлежащую множеству тем T
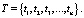
Предполагается, что существует конечное множество тем T, и каждое употребление термина w в каждом документе d связано с некоторой темой t∈T, которая неизвестна. Коллекция документов рассматривается как множество троек (d, w, t), выбранных случайно и независимо из дискретного распределения p (d, w, t), заданного на конечном множестве D×W×T. Документы d∈D и термины w∈W являются наблюдаемыми переменными, тема t∈T является латентной (скрытой) переменной [2]. Кроме этого:
- Порядок документов в наборе D не имеет значения.
- Порядок слов в документе d не имеет значения.
- Слова, встречающиеся часто в большинстве документов, не важны для определения тематики.
- Каждая тема t∈T описывается неизвестным p (w | t) на множестве слов w∈W.
- Каждый документ d∈D описывается неизвестным распределением p (t |d) на множестве тем t∈T.
Построить тематическую модель – значит, найти матрицы
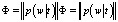
и
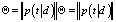
по коллекции D.
Методы латентно-семантического анализа
Метод латентно-семантического анализа LSA (англ. Latent semantic analysis, LSA)
Метод LSA был запатентован в 1988 г. группой американских инженеров-исследователей. Впервые метод был применен для автоматического индексирования текстов, выявления семантической структуры текста. Затем этот метод был довольно успешно использован для представления баз знаний и построения когнитивных моделей. В США этот метод был запатентован для проверки знаний школьников и студентов, а также проверки качества обучающих методик [13]. Метод основан на сингулярном разложении матриц SVD (англ. Singular value decomposition, SVD).
Этапы проведения метода LSA:
- Составляется общий словарь всех уникальных слов во всех документах, без учета слов не несущих смысловой нагрузки (стоп-слов).
- Для каждого слова определяется частота его вхождения в каждый документ vij.
- Составляется терм-документная матрица A. В терм-документной матрице строки соответствуют документам в коллекции, а столбцы соответствуют терминам.
Таблица 1
Представление терм-документной матрицы
|
w1 |
... |
wm |
|
|
d1 |
v1,1 |
v1,m |
|
|
... |
|||
|
dn |
vn,m |
Производится сингулярное разложение матрицы A = USVT.
Полученные в результате матрицы U и V являются искомыми матрицами
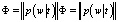
и
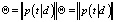
соответственно. На рис. 1 представлен алгоритм метода LSA.
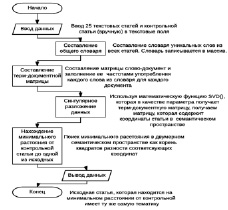
Рис. 1. Алгоритм LSA метода
Метод вероятностного латентно-семантического анализа PLSA (англ. Probabilistic latent semantic analysis, PLSA)
Данный метод является дальнейшим развитием латентно-семантического анализа. ВЛСА применяется в таких областях, как информационный поиск, обработка естественного языка, машинное обучение, и смежных областях. Данный метод был впервые опубликован в 1999 г. Thomas Hofmann [11]. Метод основан на применении EM-алгоритма (алгоритм поиска оценок максимального правдоподобия).
Рассмотрим вероятностную тематическую модель
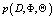 ,
,
где 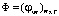 – искомая матрица терминов тем,
– искомая матрица терминов тем, 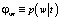 ,
,
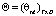 – искомая матрица тем документов,
– искомая матрица тем документов, 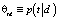 .
.
Для вычисления значений φwt и θtd используется двухшаговый EM-алгоритм.
E-шаг. На этом шаге, используя текущие значения параметров φwt и θtd, по формуле Байеса вычисляется значение условных вероятностей 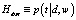 для всех тем t∈T для каждого термина w∈d для всех документов d∈D:
для всех тем t∈T для каждого термина w∈d для всех документов d∈D:
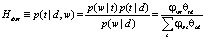 .
.
M-шаг. На этом шаге решается обратная задача: по условным вероятностям тем Hdwt вычисляются новые приближения φwt и θtd.
Величина 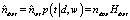 оценивает число ndwt вхождений термина w в документ d, связанных с темой t. При этом оценка не всегда является целым числом. Просуммировав
оценивает число ndwt вхождений термина w в документ d, связанных с темой t. При этом оценка не всегда является целым числом. Просуммировав 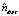 по документам d и по терминам w, получим оценки:
по документам d и по терминам w, получим оценки:
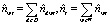 ,
,
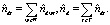
В соответствии с формулами, вычисляются частотные оценки условных вероятностей φwt и θtd:
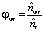 и
и 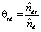 .
.
Псевдокод PLSA изображен на рис. 2 [3]:
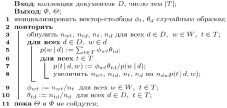
Рис. 2. Псевдокод PLSA метода
Программная реализация
Для реализации методов была разработана программа на языке программирования C#, ее графический интерфейс изображен на рис. 3.
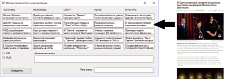
Рис. 3. Графический интерфейс программы
Программа получает на вход 25 текстов. Текстами являются новостные статьи, взятые из новостного источника в сети Интернет. На данном сайте тексты отсортированы по темам (разделам сайта). Тексты взяты из разных разделов (по 5 текстов на тему): Политика, Экономика, Спорт, Культура, Наука.
Тексты новостей извлекаются с использованием обработки html-кода веб-страницы новостного сайта. Задачей программы является определение тематики контрольной статьи.
Для проверки работоспособности программы были выбраны статьи с предопределенной темой. Из каждого раздела по одной. В табл. 2 представлены результаты работы программы для этих статей.
Таблица 2
Результаты работы программы
|
Раздел сайта |
Http-адрес новости |
LSA |
PLSA |
|
Политика |
https://ria.ru/politics/20161110/1481118723.html |
Политика |
Политика |
|
Экономика |
https://ria.ru/economy/20161110/1481125019.html |
Политика |
Экономика |
|
Спорт |
https://ria.ru/sport/20161128/1482282838.html |
Спорт |
Спорт |
|
Наука |
https://ria.ru/science/20161128/1482296195.html |
Политика |
Наука |
|
Культура |
https://ria.ru/culture/20161124/1482106648.html |
Культура |
Культура |
На рис. 4 и 5 представлены результаты работы программы, для статьи из раздела «Спорт», методами LSA и PLSA соответственно.
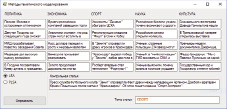
Рис. 4. Результаты работы программы LSA

Рис. 5. Результаты работы программы PLSA
Выводы
Можно констатировать, что тематики контрольных статей отобразились верно, при использовании метода PLSA, что подтверждает возможность его использования для классификации тематик новостных статей. Метод LSA допускает ошибки в определении темы, в связи с тем, вероятно, что обучающий набор слишком мал. Автоматическая категоризация текстов весьма актуальна для поисковых систем и систем обработки и извлечения знаний.
Библиографическая ссылка
Толмачев Р.В., Воронова Л.И. ТЕМАТИЧЕСКАЯ КЛАССИФИКАЦИЯ СТАТЕЙ НОВОСТНОГО РЕСУРСА МЕТОДАМИ ЛАТЕНТНО-СЕМАНТИЧЕСКОГО АНАЛИЗА // Современные наукоемкие технологии. 2017. № 3. С. 55-60;URL: https://top-technologies.ru/ru/article/view?id=36616 (дата обращения: 15.07.2026).