



Правительство Мьянмы работает над достижением цифрового видения Мьянмы на будущее путем создания национальной политики в области информационно-коммуникационных технологий (ИКТ). Правительство Мьянмы признает, что развитие информационно-коммуникационных технологий является незаменимым фактором для среднесрочного и долгосрочного роста Мьянмы и представляет собой потенциал данного роста, а также является важным условием для повышения эффективности исполнения бюджета и административной эффективности посредством «электронного правительства».
Создание сети высокопроизводительных вычислительных центров в Союзе Мьянмы является сложной и важной задачей. Назначением ВВЦ (Ресурсного центра) является предоставление органам государственного управления, субъектам экономики, науки и образования качественных информационных и вычислительных услуг, а в период кризиса и в условиях недостаточности диверсификации прогнозирования и планирования социальных и экономических процессов также заключается и в альтернативной организации всесторонней информационно-вычислительной поддержки систем государственного управления Союза Мьянмы на базе высокопроизводительных вычислений особой результативности.
Ресурсный центр несёт также функции обеспечения бесперебойной работы всей иерархической корпоративной системы высокотехнологичных отраслей промышленности в целом, а также функции обеспечения связи между отдельными отраслями и их предприятиями. В функции Ресурсного центра входит, что информационно-алгоритмическое обеспечение решения ресурсоёмких научно-технологических задач [1].
Ресурсный центр должен обеспечивать информационное обслуживание пользователей. Он должен быть укомплектован экспертами и специалистами в различных прикладных областях, способных оптимизировать использование вычислительных ресурсов и предлагать новые решения преодоления возникающих проблем.
Цель работы состоит в исследовании и разработке технических решений для анализа построения и применения высокопроизводительных вычислительных систем как основы суперкомпьютерной инфраструктуры для наукчных иследование. Для достижения поставленной цели в работе необходимо решить следующие задачи:
- Разработка архитектуры, повышения производительности и параллельному управлению распределенными системами баз данных для создания многопользовательских прикладных информационных систем.
- Создание суперкомпьютеров с различным набором характеристик, сетевых и программных решений, воплотивших в себя разработанные архитектурные, сформировать на их основе интегрированную вычислительную информационно-коммуникационную среду проведения научных исследований и решения прикладных задач.
Суперкомпьютерные технологии и создание центров высокопроизводительных вычислений
В данной статье мы приведём наши предложения по насыщению создаваемого вычислительного центра компьютерными системами. На рис. 1 приведена общая, укрупнённая схема вычислительного центра. К основным компонентам центра относятся вычислительный комплекс, сети и комплекс хранения данных. Поскольку стоимость систем вычислительного кластера и необходимого программного обеспечения составляет внушительную сумму, то развёртывание центра и насыщение его необходимым оборудованием будет происходить последовательно, в течение всего срока создания Специализированного информационно-ресурсного центр СИРЦ.
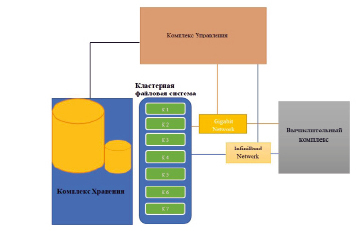
Рис. 1. Общая схема сбалансированной архитектуры суперкомпьютерного центра
Структурно-технические решения приводят к тому, что суперкомпьютерные системы быстро обновляются. Чтобы работа суперкомпьютерных центров была максимально эффективной, ориентируются на наиболее современные и быстродействующие системы.
Современный суперкомпьютер строится путем объединения большого количества серийно выпускаемых быстродействующих микропроцессоров, которые используются также и для построения обычных рабочих станций и серверов [2, 3].
В условиях современного развития телекоммуникационных технологий отпадают жёсткие ограничения географического размещения Ресурсного центра. Основополагающим условием выбора является наличие научного коллектива, способного разработать, организовать и эксплуатировать данный Центр. Наиболее целесообразным вариантом является его создание на базе научного центра (высокопроизводительных вычислений и информационных систем) в городе Най Пей До, который имеет необходимые вычислительные средства, коммуникационное оборудование и научный коллектив, способный выполнить работы по созданию Ресурсного центра в кратчайшие сроки [4].
Разместить Центр целесообразно на площадях, имеющих необходимую инфраструктуру для функционирования, как открытой, так и закрытой части Центра, прежде всего энергообеспеченность. Размещение на одних и тех же площадях открытой и закрытой части желательно, но некритично. Площадка под центр должна иметь возможности как для размещения и функционирования открытой части центра, в статусе международного центра GRID (отдельное здание с необходимыми телекоммуникационными каналами связи с международными и национальными информационными сетями), так и для закрытой части (с реализацией условий обработки и передачи закрытой информации).
Вычислительные и телекоммуникационные ресурсы создаваемого Центра позволяют обеспечить в первую очередь не только наиболее изученные потребности большой строительной промышленности, но и потребности других стратегических отраслей промышленности, в частности ТЭК, что резко повышает эффективность функционирования Центра [5].
Анализ и развитие технологий обработки больших данных в научных исследованиях
Одной из важных областей использования высокопроизводительных вычислительных центров является создание и обработка функций базы данных. Создние вычислительных средств в вычислительно-информационные узлы и организация позволит создать единый вычислительно-информационный ресурс, БД в естественных и гуманитарных науках [6].
Под большими данными понимается широкое разнообразие массивов данных, которые не могут быть обработаны традиционными приложениями из-за своего огромного объема. Анализ больших данных – сложная работа: разделение, контроль, передача, визуализация, хранение и сохранение информации [7]. Большие данные анализа часто подразумевают применение прогнозной аналитики или других передовых методов с целью извлечения из разных данных определенной информации.
В области математики на научном потенциале больших данных системы очень важна оптимизация технологии решения задач на высокопроизводительных вычислительных системах на использовании крупномасштабного моделирования [8].
Рис. 2. Высокопроизводительная серверная архитектура центра обработки данных в Союзе Мьянмы
Анализ Системы управления Большими данными и их результаты
В этой статье представлены результаты тестирования производительности баз данных. Результаты представлены для трех различных баз данных: Сassandra, Riak и MySQL. В распределенной системе базы данных должны быть установлены в кластере, который содержит несколько узлов. Производительность операций чтения, как ожидается, увеличится с увеличением фактора репликации, в то время как производительность операции записи, как ожидается, уменьшится, так как система имеет дополнительную нагрузку из-за необходимости выполнять те же операции записи в различных узлах. Кроме того, во фрагментированной MySQL не предусмотрен никакой механизм репликации. Но это выходит за рамки этой работы по оценке производительности и изучению влияния репликации на базы данных NoSQL [9].
Результаты деятельности представлены в этой статье в соответствии с двумя типами рабочих нагрузок: «в основном чтение» (read heavy) и «чтение и запись» (write heavy).
В этом тесте измерялась производительность баз данных при большом количестве операций обновления данных. В данном случае 30 процентов составляли операции обновления, а остальные 70 процентов – операции чтения. На рис. 3 можно наблюдать среднее время ожидания чтения и обновления, когда нагрузка на систему возрастает. Как показано на рисунке, для всех систем задержка операций увеличивалась при увеличении нагрузки.
Cassandra, которая оптимизирована для большого числа операций записи, имела наименьшую задержку при высокой нагрузке, как для чтения, так и для операций обновления. Riak и MySQL масштабируются в геометрической прогрессии, достигая аналогичной задержки в соответствии с нагрузкой, особенно при низких нагрузках. С другой стороны, Cassandra масштабируется линейно, хотя для операций чтения сначала и были более высокие задержки, чем у других систем. На Riak и MySQL операции обновления всегда имеют большие задержки, чем операции чтения при той же нагрузке. Тем не менее на Cassandra наблюдается обратное: операции обновления всегда были быстрее [10, с. 31–32].
Что касается операций чтения, существует не такая большая разница в результатах в отношении трех систем. Тем не менее на операциях обновления существует высокая дисперсия по трем системам, особенно при более высоких нагрузках (более 7000 операций/с). При 10000 операциях/с Cassandra достигла средней задержки 9,85 мс для операций обновления, что на 80% меньше, чем Riak (48,54), и на 71% меньше, чем MySQL (33,01).
Ожидается, что за счет увеличения доли операций обновления производительности Cassandra будет продолжать улучшаться, так как она выполняет операции записи более эффективно, чем операции чтения, в то время как другие системы будут работать хуже, увеличивая разницу в производительности между Cassandra и MySQL и Riak [11, с. 42–43].
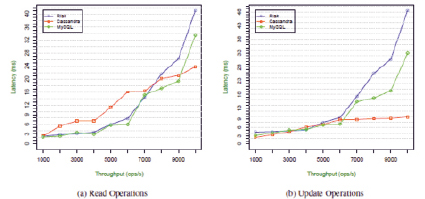
Рис. 3. Результаты тестирования с типом нагрузки вида «чтение и запись»
Выводы
Проведенные тесты показывают, что Cassandra и Riak обеспечивают производительность на уровне с реляционной базой данных. Cassandra обеспечивает гораздо лучшую производительность, чем остальные системы, если речь идет об операциях записи, но ее общая производительность снижается из-за операций записи. Производительность Riak очень похожа на шардинг MySQL.
Поддержание высокого уровня науки поможет не только сохранить научный потенциал Союза Мьянма, но и окажет позитивное влияние на дальнейшее развитие науки. В данной статье приведены наши предложения по насыщению создаваемого вычислительного Специализированного информационно-ресурсного центра (СИРЦ) для Мьянманских ученых, сохраняя и возрождая Мьянманскую научную элиту.
В Центре предусматриваются подразделения и инфраструктурные мощности, обеспечивающие следующие направления: аналитико-прогнозное, экономики жизнедеятельности, системного моделирования, ситуационного анализа, социологическое, исследовательско-конструкторское по отраслям, информационно-образовательное, развития прикладного программирования, интерфейсного обеспечения, статистического структурирования, высокоскоростной сети, удаленного обмена данными, математического моделирования и алгоритмов, использования микропроцессорной базы, конструирования микроэлектроники, архитектуры высокопроизводительных вычислений, инфраструктуры высокопроизводительных вычислений, распределенных вычислений, программирования суперкомпьютеров и др.