



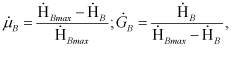
где ![]() - средняя виртуальная вербальная информационная емкость источника текста;
- средняя виртуальная вербальная информационная емкость источника текста;
![]() - средняя виртуальная вербальная эмпирическая энтропия:
- средняя виртуальная вербальная эмпирическая энтропия:
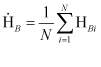
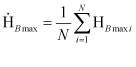
Реализация данной модели в виде программного комплекса открывает принципиально новые возможности идентификации личности по тексту. На основе созданного комплекса исследовалась идентификация текстов ряда известных русских писателей. Результаты исследования приведены в таблице:
Таблица 1
|
Автор |
|
|
|
|
|
А.А. Блок |
8,722 |
7,575 |
0,132 |
6,576 |
|
А.П. Чехов |
9,419 |
8,294 |
0,119 |
7,403 |
|
А.С. Пушкин |
10,579 |
9,161 |
0.134 |
6.463 |
|
Н. В. Гоголь |
12,133 |
10,130 |
0.165 |
5.061 |
|
И.С.Тургенев |
12,518 |
10,079 |
0.195 |
4.128 |
|
М.Ф. Булгаков |
11,633 |
9,397 |
0.192 |
4.208 |
|
М.Е.Салтыков - Щедрин |
10,602 |
9,029 |
0,148 |
5,757 |
|
С. Есенин |
11,199 |
9,286 |
0,171 |
4,848 |
|
Ф.М. Достоевский |
12,435 |
9,818 |
0,210 |
3,762 |
Анализ приведенных результатов показывает, что каждому автору соответствует вполне определенные диапазоны значений ![]() и
и ![]() , которые могут быть использованы для идентификации. Данный вывод может быть обобщен для любого индивидуума. В данном случае в качестве объекта идентификации анализа целесообразно использовать написанное им сочинение, установленного объема, на произвольную тему.
, которые могут быть использованы для идентификации. Данный вывод может быть обобщен для любого индивидуума. В данном случае в качестве объекта идентификации анализа целесообразно использовать написанное им сочинение, установленного объема, на произвольную тему.
Однако из результатов, приведенных в таблице 1, следует проблема, связанная с тем, что диапазоны виртуальной вербальной идентификации различных индивидуумов могут перекрываться. Следствием этого может являться неоднозначность идентификации. Данная проблема может быть решена путем применения подхода, основанного на определении средних значений результатов идентификации.