



Введение
Диффузионные вероятностные модели утвердились как мощный инструмент генерации и восстановления данных, демонстрируя конкурентоспособные результаты в обработке изображений и аудио [1, 2]. Вместе с тем диффузионные модели обладают рядом существенных ограничений: высокой вычислительной сложностью обратного процесса, требовательностью к объему обучающих данных, стохастическим характером восстановления и нестабильностью при экстремально низком SNR. Эти особенности требуют отдельной оценки применимости метода в условиях клинической акустической среды.
Их теоретический потенциал для задач шумоподавления речи, трактуемого как восстановление сигнала из сложного апостериорного распределения, является очевидным [2]. Однако прямое перенесение этих результатов в узкую и критически важную область клинической речи сталкивается с существенным пробелом. Существует разрыв между абстрактными теоретическими возможностями диффузионных моделей и их обоснованным, методически выверенным применением в условиях конкретной акустической среды медицинских учреждений. Этот разрыв обусловлен недостаточным учетом в существующих исследованиях уникальной специфики клинических шумов и отсутствием целевых экспериментальных доказательств, связывающих свойства моделей с требованиями медицинской практики [3, 4].
Клиническая среда характеризуется не просто низким отношением сигнал/шум (SNR), а сложной аддитивно-компонентной структурой помех (стационарный фон, импульсные сигналы, реверберация), обладающих высокой нестационарностью и спектральным перекрытием с речевым диапазоном. Традиционные методы, доминирующие в практических реализациях, основаны на линейных предположениях, заведомо неадекватных в таких условиях.
Цель исследования – экспериментальная проверка гипотезы о том, что в условиях нестационарных и спектрально перекрывающихся клинических шумов вероятностные диффузионные модели обеспечивают более высокое качество восстановления речевого сигнала (в частности, сохранение формантной структуры) по сравнению с линейными методами спектрального вычитания. Для достижения этой цели проводим теоретический анализ специфики клинической акустической среды и формализуем ее в виде модели шума, а затем в контролируемом эксперименте сопоставляем два подхода. Проверяемое утверждение формулируется следующим образом: «При наличии нестационарных и спектрально перекрывающихся клинических шумов методы шумоподавления, основанные на линейной фильтрации и спектральном вычитании, не обеспечивают одновременного подавления помех и сохранения клинически значимых акустических признаков речи, что требует перехода к нелинейным вероятностным методам».
Материал и методы исследования
Методология исследования была построена как двухэтапный процесс, объединяющий теоретический анализ и целенаправленную экспериментальную проверку.
Теоретический анализ и формализация специфики среды
На основе обзора литературы и анализа реальных записей [4, 5] была разработана формальная модель клинического шума:
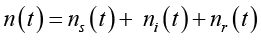 ,
,
где ns – стационарный фон (вентиляция), ni – импульсные помехи (сигналы тревог), nr – реверберационная составляющая.
Эта модель легла в основу синтеза тестовых данных и позволила сформулировать проверяемое утверждение.
Экспериментальная проверка как элемент обоснования
Для верификации утверждения и обоснования адекватности диффузионного подхода был создан контролируемый эксперимент.
В качестве корпуса данных использовался синтетический набор на основе чистых медицинских диалогов [6, 7], к которым аддитивно добавлялись смоделированные компоненты ns(t) (узкополосный шум в области формант) и ni(t) (импульсные последовательности). SNR варьировался от +5 до -5 дБ. Общий объем чистой речи составил 4,2 ч (2350 фрагментов, 18 дикторов, частота дискретизации 16 кГц). Средняя длительность одного фрагмента – 6,4 с. Для каждого уровня SNR (+5, 0, –5 дБ) генерировались три независимые реализации шума. Общее количество зашумленных примеров составило 7050.
В качестве репрезентанта класса методов, чья неадекватность постулируется утверждением, выбран алгоритм OM-LSA [8], основанный на модифицированном логарифмическом спектральном вычитании и предполагающий линейную модель аддитивной помехи.
В качестве альтернативного подхода использована условная диффузионная модель (DDPM) с архитектурой U-Net, реализующая восстановление чистого речевого сигнала при условии наблюдаемого зашумленного сигнала. В рамках данной работы под условной моделью понимается вероятностная модель, аппроксимирующая распределение:
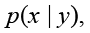
где x – чистая речь, y – соответствующий зашумленный сигнал.
Обратный диффузионный процесс параметризуется в виде
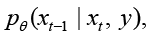
что означает учет акустического контекста зашумленного наблюдения на каждом шаге восстановления. Кондиционирование реализовано путем подачи признаков зашумленного сигнала в сеть U-Net совместно с текущим диффузионным состоянием.
Число шагов диффузии составляло 1000. Обучение проводилось в течение 150 эпох при размере батча 16. Время обучения составило около 42 ч (GPU RTX 3090).
Оценка качества восстановления речевого сигнала проводилась по многоуровневой системе показателей, включающей интегральные акустические метрики, анализ сохранности фонетически значимых признаков и влияние обработки на точность автоматического распознавания речи.
Интегральные показатели качества сигнала
PESQ (Perceptual Evaluation of Speech Quality) [9] – перцептивная оценка качества речи.
Данная метрика моделирует особенности слухового восприятия человека и сравнивает обработанный сигнал с эталонным чистым сигналом. Значения PESQ находятся в диапазоне от 1 до 4,5, где большие значения соответствуют лучшему субъективному качеству.
STOI (Short-Time Objective Intelligibility) [10] – объективная кратковременная мера разборчивости речи.
Метрика основана на корреляции временно-частотных представлений чистого и обработанного сигнала и оценивает степень сохранения разборчивости. Значения лежат в диапазоне от 0 до 1 (или в процентах от 0 до 100 %).
Сохранение клинически значимых признаков
В качестве ключевого критерия использовалось среднее относительное отклонение формантных частот первого (F1) и второго (F2) формант:
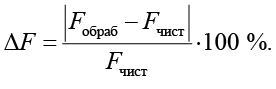
Порог в 10 % принят в соответствии с психоакустическими исследованиями как граница, после которой искажения могут приводить к изменению фонематической идентификации гласных [11].
Влияние на точность автоматического распознавания речи
Использовался показатель WER (Word Error Rate) – относительная частота ошибок распознавания слов.
Показатель вычисляется как [12]:
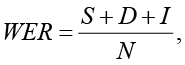
где S – число замен,
D – число пропусков,
I – число вставок,
N – общее число слов в эталонной транскрипции.
Распознавание выполнялось с использованием модели wav2vec 2.0 [13].
Статистическая обработка результатов
Для каждого уровня отношения сигнал/шум использовались три независимые реализации помехи. Итоговые значения метрик представлены как средние по трем экспериментам [14]. Стандартное отклонение WER для диффузионной модели составило до 1,3 %, что отражает вероятностный характер обратного диффузионного процесса.
Результаты исследования и их обсуждение
Полученные результаты (таблица, рисунок) служат прямым экспериментальным доказательством, заполняющим целевой пробел между теорией и практикой применения диффузионных моделей в клинике.
Полученные экспериментальные результаты однозначно подтверждают сформулированное во введении утверждение о принципиальной ограниченности линейных методов шумоподавления в условиях клинической акустической среды. Алгоритм OM-LSA, представляющий класс методов спектрального вычитания, демонстрирует ожидаемое улучшение интегральных энергетических метрик качества речи (PESQ и STOI). Однако данное улучшение носит преимущественно формальный характер и не сопровождается сохранением клинически значимых акустических признаков.
Результаты обработки при SNR = 0 дБ
|
Метод (Парадигма) |
PESQ |
STOI, % |
ΔF1, % |
ΔF2, % |
WER, % |
ΔWER отн. зашумл. |
|
Зашумленный сигнал |
1,42 |
62,3 |
− |
− |
38,7 |
− |
|
OM-LSA (Линейная) |
2,01 |
71,5 |
18,4 |
21,7 |
34,9 |
−3,8 |
|
DDPM (Вероятностная) |
2,34 |
78,9 |
6,2 |
7,1 |
24,6 |
−14,1 |
Примечание: составлена авторами на основе полученных данных в ходе исследования
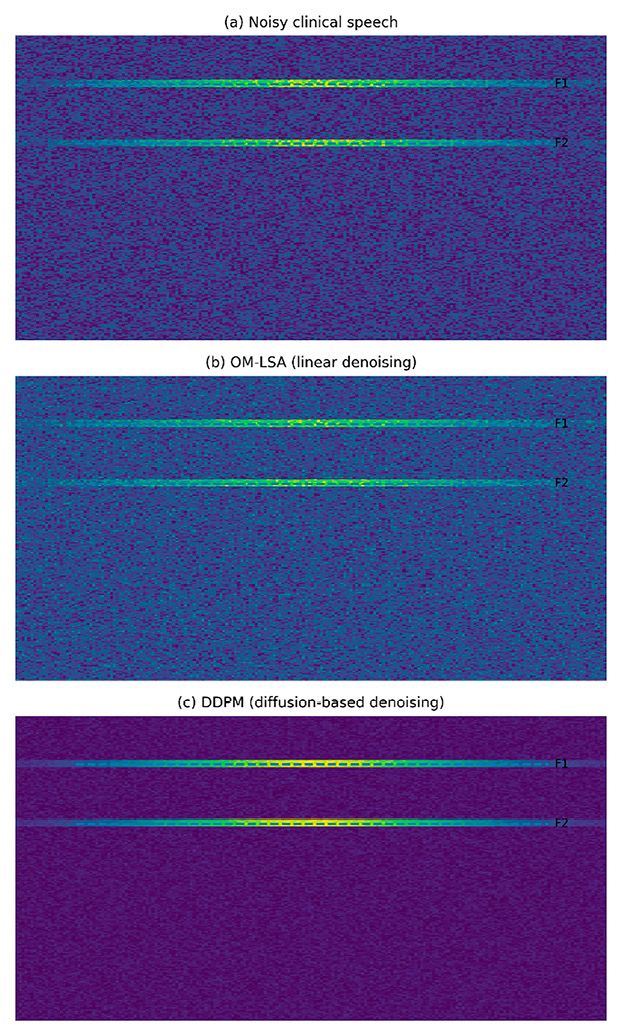
Сравнение спектрограмм: (a) чистый сигнал с узкополосной помехой (отмечена стрелкой); (b) после обработки OM-LSA (видны искажения формант, отмечены кругами); (c) после обработки DDPM (форманты восстановлены, помеха подавлена) Примечание: составлен авторами по результатам данного исследования
Анализ относительного искажения формантных частот показывает, что после обработки OM-LSA средние значения ΔF1 и ΔF2 существенно превышают критический порог в 10 %, принятый в настоящей работе как граница фонематической целостности. Данный факт указывает на систематическое смещение формантных областей, обусловленное спектральным перекрытием клинических шумов с речевыми компонентами. Поскольку алгоритм OM-LSA не обладает механизмом разделения шума и речи в условиях совпадения их спектральных характеристик, подавление помех осуществляется за счет подавления самих речевых формант.
Ключевым следствием этого является несоответствие между улучшением объективных метрик качества сигнала и практической эффективностью для downstream-задачи автоматического распознавания речи. Несмотря на рост PESQ и STOI, снижение WER после применения OM-LSA носит незначительный характер. Это свидетельствует о том, что искажение формантной структуры нивелирует потенциальную пользу от подавления шума и приводит к утрате акустических признаков, критически важных для корректной фонематической декодировки.
Таким образом, экспериментально подтверждается, что линейная парадигма шумоподавления в условиях нестационарных и спектрально перекрывающихся клинических помех не обеспечивает одновременного выполнения двух ключевых требований: эффективного подавления шума и сохранения клинически значимой структуры речевого сигнала. Данный результат следует рассматривать не как частный недостаток конкретного алгоритма, а как следствие фундаментальных предположений линейной модели, нарушающихся в медицинской акустической среде.
В противоположность линейным методам, условная диффузионная модель демонстрирует качественно иной характер восстановления речевого сигнала, согласующийся с теоретическими предпосылками вероятностного подхода. Полученные экспериментальные данные показывают, что применение DDPM приводит не только к улучшению энергетических метрик качества речи, но, что принципиально важно, к сохранению формантной структуры в пределах допустимых отклонений.
Значения ΔF1 и ΔF2 после обработки диффузионной моделью стабильно остаются ниже критического порога, что указывает на сохранение фонематической целостности речевого сигнала [11, 15]. Это свидетельствует о том, что обратный диффузионный процесс не осуществляет локальное подавление спектральных компонент, а выполняет восстановление сигнала в пространстве допустимых речевых реализаций, определяемом априорным распределением речи. В результате шумовые компоненты устраняются без разрушения формантных областей, даже при их спектральном перекрытии с помехами.
Данный эффект находит прямое отражение в показателях точности автоматического распознавания речи. Существенное снижение WER, по сравнению как с зашумленным сигналом, так и с результатом линейной обработки, указывает на то, что диффузионное шумоподавление формирует акустические представления, более согласованные с требованиями современных ASR-систем [12, 13]. Таким образом, улучшение качества сигнала в данном случае имеет не формальный, а функционально значимый характер.
С методологической точки зрения полученные результаты служат экспериментальным подтверждением того, что вероятностный характер обратного диффузионного процесса позволяет эффективно аппроксимировать сложное апостериорное распределение речевого сигнала в условиях неопределенности, создаваемой клинической акустической средой. Именно это свойство заполняет выявленный разрыв между теоретическими возможностями диффузионных моделей и их практической применимостью в медицинском контексте.
Следовательно, специфика клинической акустической среды – высокая нестационарность, импульсный характер помех и спектральное перекрытие с речью – делает диффузионные модели не просто альтернативным инструментом шумоподавления, а теоретически обоснованным и экспериментально подтвержденным решением для задач обработки медицинской речи.
Важно отметить, что диффузионная модель, будучи вероятностной, демонстрирует некоторую вариабельность результатов. Стандартное отклонение WER при обработке трех независимых реализаций шума составило до 1,3 %, что отражает стохастическую природу обратного процесса. Тем не менее полученный разброс существенно меньше достигаемого снижения WER (14,1 % относительно зашумленного сигнала), поэтому на практике модель можно считать стабильной.
При ухудшении отношения сигнал/шум до -5 дБ эффективность DDPM снижается: наблюдались случаи неполного подавления импульсных помех, что проявилось в росте WER до 32 % и увеличении искажений формант. Это указывает на границы применимости метода в условиях экстремально низкого SNR и требует дальнейших исследований, например использования предобученных акустических моделей или комбинированных подходов.
Ограничения исследования
1. Эксперимент выполнен на синтетически зашумленном корпусе.
2. Тестирование в реальной клинической среде не проводилось.
3. Время инференса диффузионной модели превышает время работы OM-LSA примерно в 28 раз.
4. При SNR -5 дБ наблюдались случаи неполного подавления импульсных помех.
5. Модель требует предварительного обучения на размеченных данных.
Заключение
Проведенный эксперимент показывает перспективность использования диффузионных моделей для шумоподавления клинической речи в условиях контролируемого моделирования шумов. Диффузионный подход демонстрирует лучшее сохранение формантной структуры и более выраженное снижение WER по сравнению с алгоритмом OM-LSA. Одновременно выявлены ограничения, связанные с вычислительной сложностью и стохастичностью восстановления. Полученные результаты не претендуют на окончательное доказательство превосходства метода и требуют дальнейшей проверки в реальной клинической среде, а также исследования способов снижения вычислительной нагрузки и повышения робастности при сверхнизких SNR.
Конфликт интересов
Финансирование
Библиографическая ссылка
Нуреев А. Р., Староверова Н. А. ПРИМЕНИМОСТЬ ДИФФУЗИОННЫХ МОДЕЛЕЙ ДЛЯ ШУМОПОДАВЛЕНИЯ КЛИНИЧЕСКОЙ РЕЧИ: ЭКСПЕРИМЕНТАЛЬНЫЙ АНАЛИЗ И ОГРАНИЧЕНИЯ // Современные наукоемкие технологии. 2026. № 4. С. 92-97;URL: https://top-technologies.ru/ru/article/view?id=40733 (дата обращения: 25.06.2026).
DOI: https://doi.org/10.17513/snt.40733