



Введение
В условиях современного промышленного производства существует потребность в повышении точности и автоматизации процессов учёта и отслеживания движения заготовок, полуфабрикатов и деталей на всех этапах жизненного цикла продукции. Перспективным направлением в области визуальной идентификации выступает применение систем технического зрения (СТЗ), обеспечивающих автоматизированный сбор, анализ визуальных данных и принятие решений. В машиностроении СТЗ применяются для решения широкого круга задач, включая контроль геометрии деталей, выявление дефектов поверхности, а также распознавание маркировок.
В основу подхода заложена возможность его итеративной корректировки технического зрения и дообучения по накапливаемым данным. Реализация данного подхода обеспечит не только возрастание метрики точности в ходе эксплуатации, но и адаптацию системы к новым типам маркировок и изменяющимся условиям функционирования. Разработка эффективной СТЗ для распознавания маркировок сопряжена с рядом неточностей на аппаратном и программном уровнях. Таким образом, создание надёжной СТЗ требует комплексного подхода, интегрирующего оптимизацию аппаратной конфигурации и совершенствование алгоритмического обеспечения для обработки изображений.
Цель исследования – автоматизация процесса идентификации заготовок по буквенно-цифровым обозначениям, нанесённым на их поверхность, с последующей классификацией материалов по базе данных марок стали.
Материалы и методы исследования
Предлагаемое решение разработано на базе университета НИУ БелГУ и направлено на изучение процесса идентификации заготовок в машиностроительном производстве с внедрением СТЗ для распознавания маркировок на заготовках в машиностроении. Для решения поставленных исследовательских задач был разработан и реализован комплекс взаимосвязанных функциональных модулей, образующих последовательность этапов обработки данных. Основу СТЗ составляет модуль автоматизированного захвата изображений, обеспечивающий получение исходных данных в виде изображений маркированных заготовок. Полученные изображения поступают в модуль цифровой предобработки, в рамках которого осуществляется подавление шумов, повышение контрастности целевых областей и коррекция геометрических искажений методами перспективной трансформации [1]. Ключевым этапом является модуль распознавания текста, реализованный на базе алгоритмов оптического распознавания символов (OCR). Для минимизации ошибок, присущих OCR-системам, распознанный текст подвергается процедуре нормализации, включающей коррекцию типичных опечаток и синтаксических искажений [2; 3]. Верификация полученных данных осуществляется модулем сопоставления с эталонной базой данных марок стали. Результатом работы данной подсистемы является классификация заготовки, которая передается на информационный выходной интерфейс [4].
Архитектура системы гарантирует функционирование в режиме реального времени, что обеспечивает обработку потока данных в условиях высокоскоростного производственного цикла. Интеграция указанных модулей в единый конвейер позволяет достичь поставленной цели по созданию надежной системы идентификации [5; 6].
Результаты исследования и их обсуждение
В ходе исследования была разработана и реализована модульная архитектура системы автоматизированной идентификации изделий по маркам стали, основанная на последовательном применении алгоритмов компьютерного зрения и обработки естественного языка. На рисунке 1 представлен алгоритм последовательности обработки данных в системе.
Обработка данных представляет собой последовательный конвейер: бинаризованное изображение поступает в Tesseract OCR для извлечения текста. После очистки и нормализации (исправление гомоглифов) текст сопоставляется с базой марок стали алгоритмом нечеткого поиска. Система индицирует либо найденную марку, либо ошибку классификации.
Алгоритм предобработки изображений реализуется в виде последовательности следующих шагов. На первом шаге осуществляется преобразование цветного изображения в полутоновое. Данная процедура является стандартной для систем компьютерного зрения и направлена на сокращение объема обрабатываемых данных за счет элиминации избыточной цветовой информации [7; 8].
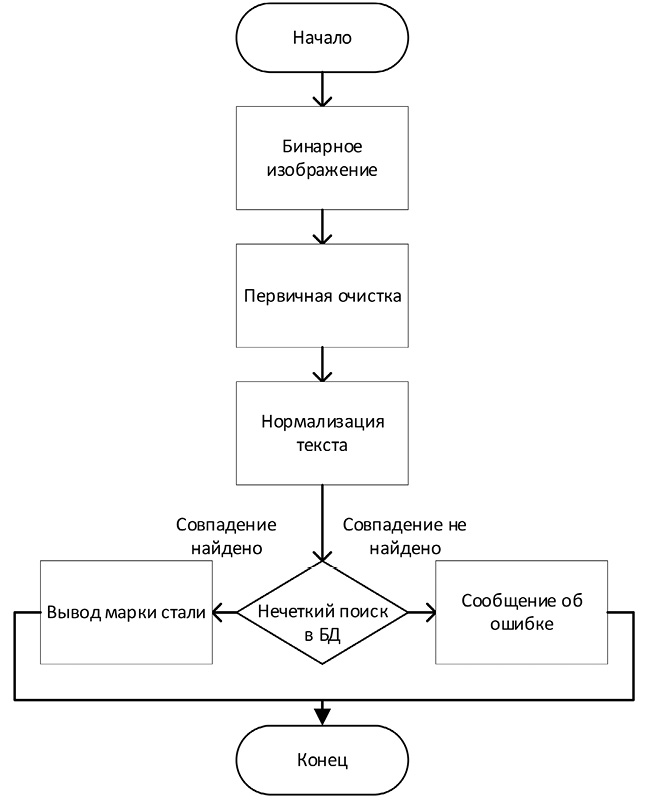
Рис. 1. Алгоритм последовательности обработки данных в системе Источник: составлено авторами
Интенсивность каждого пикселя вычисляется как взвешенная сумма значений каналов красного (R), зеленого (G) и синего (B):
I = 0.2989 × R + 0.5870 × G + 0.1140 × B, (1)
где I – интенсивность пикселя в полутоновом представлении.
Второй шаг обработки заключается в повышении контрастности изображения. Для решения проблемы недостаточного контраста, присущего производственной маркировке, в системе реализовано линейное растяжение гистограммы яркости с помощью функции cv2.convertScaleAbs (OpenCV), что усиливает различия между фоном и символами.
Третий шаг устраняет производственные шумы (например, от недостаточного освещения), которые снижают точность распознавания. Для их минимизации используется гауссовский фильтр (cv2.GaussianBlur), обеспечивающий подавление высокочастотных помех при сохранении целостности полезных контуров.
На этапе бинаризации изображение преобразуется в бинарное представление посредством пороговой обработки. Точность сегментации символов, определяемая корректностью выбора порога, обеспечивается применением функций cv2.threshold и адаптивного метода cv2.ADAPTIVE_THRESH_MEAN_C из библиотеки OpenCV [9-11].
Пятый шаг включает коррекцию геометрических искажений, вызванных неоптимальной ориентацией объекта, и нормализацию изображения. Процесс предполагает детектирование контуров символов, оценку их пространственных характеристик и углов ориентации с последующим применением линейных или перспективных преобразований для восстановления геометрии.

Рис. 2. Предобработка изображений Источник: составлено авторами
Шестой этап включает сегментацию символов методом анализа связных компонентов. На бинаризированном изображении проводится кластеризация смежных пикселей с последующей верификацией полученных областей по заданным параметрам (размер, форма). Области, соответствующие критериям, идентифицируются как символы, остальные удаляются как шум.
Таким образом, предложенный алгоритм предобработки изображения интегрирует ключевые методы обработки изображений, обеспечивающие надежную подготовку данных для последующего распознавания символов в системах технического зрения, результат показан на рисунке 2.
Для обеспечения максимального качества оптического распознавания символов (OCR) в условиях промышленной эксплуатации была выбрана конфигурация OEM 3, использующая механизм LSTM OCR и основанная на архитектуре сверточных нейронных сетей. Выбор данной конфигурации обусловлен её повышенной устойчивостью к визуальным искажениям и способностью к адаптивному анализу сложных паттернов [12].
Для сегментации текстовых областей был применён режим сегментации страниц (Page Segmentation Mode, PSM) с параметром 6, ориентированный на распознавание единого блока текста. Указанный режим является оптимальным для обработки маркировочных обозначений, которые обычно представлены в виде изолированных строк, состоящих из буквенно-цифровых символов. Выходные данные в производственной среде неизбежно подвержены ошибкам распознавания, поэтому основными факторами, детерминирующими возникновение данных ошибок, выступают: низкое разрешение и недостаточная контрастность исходных изображений, частичная деградация контуров символов, применение нестандартных типографских шрифтов, а также семиотическая близость графем различных алфавитов.
Для минимизации указанных ошибок распознавания в рамках СТЗ был разработан и интегрирован специализированный модуль постобработки, выполняющий нормализацию текстовых данных. Основная функция данного модуля заключается в анализе выходных данных первичного распознавания (OCR) и коррекции наиболее рекуррентных ошибок перед передачей текста на последующие этапы обработки, в частности в модуль классификации.
Алгоритм нормализации реализует трехшаговую обработку текстовых данных:
1) унификация регистра (приведение символов к верхнему регистру);
2) элиминация избыточных символов (удаление пробельных и управляющих символов);
3) корректировка гомоглифов (замена символов латинского алфавита на кириллические аналоги).
Нормализованные данные сопоставляются с эталонными значениями из базы данных марок стали. Для минимизации ошибок, обусловленных артефактами обработки изображений (зернистость, деградация символов), интегрирован алгоритм нечеткого сравнения на основе алгоритма Левенштейна (библиотека difflib, Python). Данный подход обеспечивает идентификацию соответствий в условиях орфографических вариаций и незначительных расхождений. Ключевой элемент СТЗ – модуль классификации, осуществляющий сопоставление распознанных маркировок стали с эталонными значениями из базы данных. Формирование базы данных основано на анализе наиболее распространенных марок, применяемых на производстве, что обеспечивает оптимальный баланс между компактностью и репрезентативностью охвата материалов [13-15].
Основу программной реализации составили следующие компоненты: OpenCV для предобработки изображений, Tesseract OCR с конфигурацией OEM 3 и PSM 6 для распознавания строкового текста, а также Pytesseract для интеграции OCR-функционала в алгоритмы системы. Кросс-платформенность OpenCV и поддержка Python обеспечили эффективную разработку, пока комбинация Tesseract и Pytesseract позволила достичь оптимального баланса между точностью распознавания и гибкостью интеграции с внешними системами.

Рис. 3. Изображение с маркировкой: а) группа А; б) группа Б; в) группа С Источник: составлено авторами
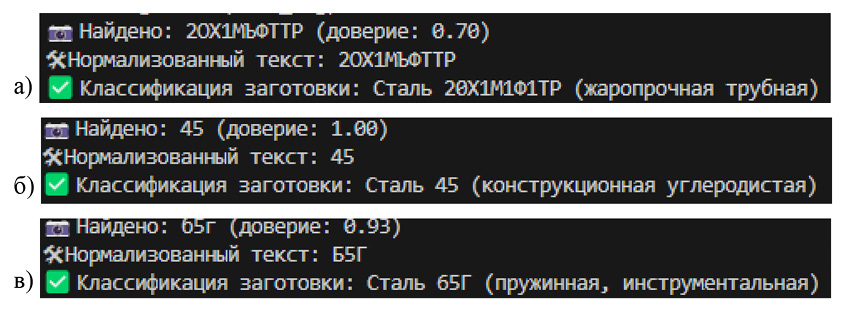
Рис. 4. Вывод классификации: а) группа А; б) группа Б; в) группа С Источник: составлено авторами
Таблица 1
Результаты проведения испытаний
|
Показатели |
Значения |
||
|
А |
Б |
С |
|
|
Точность распознавания текста |
98,7% |
94,5% |
82,3% |
|
Успешность нормализации |
99,3% |
97,1% |
89,7% |
|
Правильность классификации |
98,7% |
94,0% |
83,5% |
|
Среднее время обработки |
0,23 секунды |
0,26 секунды |
0,31 секунды |
Примечание: составлено авторами на основе полученных данных в ходе исследования.
Экспериментальные испытания проводили в условиях, максимально приближённых к промышленной среде. Наборы изображений (A, B, C) обрабатывались по очереди для последовательной оценки влияния степени сложности на результативность работы алгоритмов (табл. 1). Для каждого набора замеряли следующие показатели: доля успешно распознанного текста; число ошибок автоматического распознавания; результативность нормализации; точность классификации и длительность обработки одного изображения. Примеры изображений представлены на рисунках 3 и 4.
Результаты испытаний системы для набора A, включающего изображения, полученные в упрощённых условиях с отчётливыми, хорошо читаемыми символами, ровным освещением и незначительными помехами на поверхности, продемонстрировали практически корректную работу. Единичные ошибки, связанные со смешением латинских и кириллических символов, таких как «Х» и «X», «0» и «О», были успешно устранены модулем нормализации. Это подтвердило, что алгоритмы нормализации полностью компенсируют неточности OCR.
Испытания в усложнённых условиях (набор B) подтвердили сохранение системой высокой точности распознавания при наличии помех: загрязнений, потёртостей, неравномерного освещения и мелких повреждений знаков.
Таблица 2
Сравнительная эффективность
|
Показатель |
Стандартный OCR |
Разработанная система |
|
Точность классификации (средняя) |
77,3% |
92,1% |
|
Время обработки (среднее) |
0,19 сек. |
0,27 сек. |
|
Устойчивость к ошибкам OCR |
Низкая |
Высокая |
Примечание: составлено авторами на основе полученных данных в ходе исследования.
Типичные ошибки распознавания следующие: слияние символов, частичные пропуски и некорректное распознавание графем «Ф»/«З». Алгоритмы коррекции текста успешно компенсировали большинство ошибок, демонстрируя устойчивость к умеренным повреждениям. Время обработки соответствовало требованиям промышленной эксплуатации, что подтверждает практическую применимость системы в неидеальных условиях.
Результаты испытаний на наборе C с экстремальными условиями съёмки (значительные загрязнения, повреждения маркировок, деформации знаков, угловые искажения) показали сохранение системой удовлетворительной точности, превосходящей типовые OCR-решения. Несмотря на пропуски символов в зонах сильных повреждений и ошибки распознавания соединённых/размытых графем, обеспечена корректная классификация свыше 80% заготовок. Алгоритм нечёткого сравнения (difflib) эффективно компенсировал частично распознанные маркировки. Сбои отмечались лишь при полном уничтожении знаков, исключающем визуальную идентификацию. Производительность системы оставалась в пределах, допустимых для промышленной эксплуатации, подтвердив устойчивость алгоритмов к экстремальным условиям.
Результаты, полученные для набора А, подтвердили, что система успешно справляется с обработкой изображений, полученных в типовых производственных условиях с незначительными помехами. Положительные результаты для набора B продемонстрировали стойкость алгоритмов к незначительным загрязнениям и повреждениям, регулярно возникающим в реальной эксплуатации. Несмотря на существенные затруднения, связанные с набором C, система обеспечила точность, превышающую заданный порог (80%), что подтверждает её пригодность для эксплуатации в условиях сильной деградации качества изображений. Средняя длительность обработки одного изображения для всех наборов составила 0,27 секунды. Даже в наиболее сложных условиях (набор C) время обработки осталось в пределах 0,31 секунды, что полностью соответствует нормативам обработки в реальном времени.
Для проведения сравнительных испытаний разработанной системы был выполнен сопоставительный анализ с применением типового инструмента распознавания Tesseract, функционирующего в исходной конфигурации без проведения предварительной подготовки и доводки изображений (табл. 2). Результаты контроля точности показали последовательное снижение этого показателя у эталонного решения по мере усложнения условий: в группе A точность составила 92,5%, в группе B – 78,4%, а в группе C – лишь 61,0%. Данные подтверждают, что стандартные системы удовлетворительно справляются с изображениями хорошего качества, но их эффективность резко падает при ухудшении условий, поскольку они не способны компенсировать ошибки распознавания, характерные для смешанных алфавитов и повреждённых символов.
Существенно повысить надёжность разработанной системы позволило добавление блока нормализации, который успешно исправляет характерные ошибки автоматического распознавания, такие как неправильное соединение или разделение знаков. Результативность этого блока была измерена: в наборе A нормализация устранила 96% ошибок распознавания, в наборе B – 92%, а в усложнённых условиях набора C – 78% ошибок. Это подтверждает его существенную роль в поддержании стабильного функционирования системы при ухудшении качества входных данных.
Пусть время обработки немного увеличилось по сравнению с базовым OCR, но прирост точности на 16% компенсировал этот эффект.
Заключение
Проведенное исследование подтвердило эффективность разработанной автоматизированной СТЗ для распознавания маркировок на металлических заготовках в условиях машиностроительного производства. Реализованный комплекс алгоритмов предобработки изображений, включающий коррекцию контрастности, гауссову фильтрацию, адаптивную бинаризацию и геометрическую нормализацию, позволил достичь высокой точности распознавания даже в сложных производственных условиях. Экспериментальные результаты продемонстрировали устойчивую работу системы по всем тестовым группам: без помех достигнута точность 98,7%, в условиях умеренных помех – 94,5%, а при экстремальных повреждениях маркировок система сохранила показатель 82,3%. Время обработки не превысило 0,31 секунды, что соответствует требованиям промышленных процессов настоящего времени.
Сравнительный анализ с традиционными OCR-решениями показал существенное превосходство разработанной системы – прирост точности классификации составил в среднем 14,8%, достигая 31,3% для изображений наихудшего качества. Ключевым фактором эффективности является модуль нормализации, обеспечивающий коррекцию до 96% OCR-ошибок. Модульная архитектура системы обеспечивает возможность ее адаптации к изменяющимся производственным требованиям, что делает предложенное решение перспективным для внедрения на современных машиностроительных предприятиях.
Конфликт интересов
Библиографическая ссылка
Афонин А.Н., Лебединский Д.К., Шеметова О.М., Нестерова Е.В., Федоров В.И., Маматов А.В. АВТОМАТИЗАЦИЯ ПРОЦЕССА ИДЕНТИФИКАЦИИ ЗАГОТОВОК // Современные наукоемкие технологии. 2025. № 12. С. 10-16;URL: https://top-technologies.ru/ru/article/view?id=40599 (дата обращения: 23.07.2026).
DOI: https://doi.org/10.17513/snt.40599