



Введение
Обнаружение объектов (Object Detection) – это процесс идентификации и локализации объектов на изображении или видеопотоке с использованием методов компьютерного зрения и машинного обучения. Этот процесс включает несколько ключевых компонентов [1]: идентификацию объектов; локализацию объектов; классификацию объектов.
Малым объектом обычно считается объект, занимающий очень малую площадь на изображении.
Таблица 1
Известные модели обнаружения объектов
|
Подход |
Модели, использующие подход |
|
Стратегии увеличения объема данных |
SOD, RRNet, DS-GAN |
|
Оптимизированное назначение меток |
S3FD, EMO, DotD, RFLA |
|
Детекторы, зависящие от масштаба |
FPN, MS-CNN, SSH, ScaleMatch |
|
Иерархическое объединение признаков |
PANet, MFR-CNN, Fusion Factor, SSPNet |
|
Методы, основанные на внимании |
SCRDet, FBR-Net, MSCCA, CANet |
|
Методы контекстного моделирования |
PyramidBox, SINet, R2-CNN, CAD-Net |
Примечание: составлена авторами на основе источников [5–7]
Часто используются следующие эмпирические пороги [2]:
– Площадь в пикселях менее 32x32 пикселя (стандарт MS COCO: объекты < 322 пикселей).
– Отношение площади объекта к площади изображения (< 0,01 %).
– Объект занимает менее 10 % ширины/высоты изображения.
Object Detection – одна из ключевых задач компьютерного зрения, с успехом решаемая современными глубокими нейронными сетями (DNN), такими как Faster R-CNN, YOLO, SSD, RetinaNet. Однако, несмотря на впечатляющие успехи в обнаружении объектов среднего и крупного размера, надежное обнаружение малых объектов (small objects) остается серьезной и нерешенной проблемой [3].
Причинами такого разрыва являются следующие моменты [4].
1. Малое количество пикселей означает малое количество визуальной информации (цвет, текстура, границы). Нейросети не хватает данных для построения надежных отличительных признаков (features).
2. Операции понижающей дискретизации, критически важные для увеличения рецептивного поля и уменьшения вычислительной сложности, неизбежно агрегируют информацию и теряют мелкие детали (pooling).
3. Малых объектов на изображениях обычно значительно больше, чем крупных. Однако аннотировать их сложнее и дороже (anchor boxes).
4. Точное очерчивание малых объектов (bounding box) сложно и субъективно. Кроме того, даже незначительное смещение аннотации может привести к большой потере IoU (Intersection over Union) для малого объекта.
В настоящее время научные исследования сосредоточены на трех ключевых направлениях: улучшение архитектуры сети, модификация процесса обучения и улучшение входных данных [5–7].
В табл. 1 представлены существующие современные подходы обнаружения малых объектов и модели, реализующие эти подходы.
К сожалению, данные технологии обладают рядом ограничений при решении указанной проблемы [8]: многие методы значительно увеличивают вычислительные затраты и замедляют инференс; детекция малых объектов остается чувствительной к размытию и сильному шуму [9]; эффективность сильно зависит от качества и количества малых объектов в обучающем наборе; имеется большое число ложных срабатываний. Кроме того, методы, хорошо работающие на одном наборе данных, могут хуже работать в других доменах (спутниковые снимки, медицинские изображения, автономное вождение). Уменьшение пространственной избыточности и поиск многомерных признаков зачастую «уничтожают» представление малых объектов [10].
Цель исследования – проведение сравнительного анализа современных нейросетевых технологий и создание более совершенной гибридной модели прикладного искусственного интеллекта (ИИ) для повышения эффективности обнаружения объектов.
Материалы и методы исследования
Главная идея проекта заключается в совмещении обучения на основе данных (нейросеть) с существующими фоновыми знаниями в виде реляционных баз знаний или логических аксиом (собственно искусственный интеллект), что даст системе возможность моделировать рассуждения [11]. В представленной работе основное внимание уделено результатам применения высокоточных систем с нейросимвольной архитектурой. Подобные системы представляют собой гибридный подход в области искусственного интеллекта, объединяющий символический ИИ и нейронные сети [12]. Символический ИИ фокусируется на явных, интерпретируемых представлениях знаний, используя правила и математическую логику для обработки информации [13]. Примерами современных субсимволических систем являются такие известные проекты, как GPT (Generative Pre-trained Transformer), семейство конволюционных нейронных сетей YOLO и диффузионно-трансформерных моделей DALLE [14].
Для проведения исследований была разработана интеллектуальная система обнаружения малых объектов (ИСМО). Ее структура представлена на рис. 1. Система имеет двухконтурную архитектуру – контур инференса и контур обучения, что позволяет решить две основные задачи исследования: оперативное выполнение процесса обнаружения объектов на основе текущих данных и совершенствование системы за счет обработки обучающих данных. Оба контура связаны через общий интерфейс, который обеспечивает согласованность в обработке данных, а также обмен параметрами между подсистемами. Это дает возможность системе оставаться актуальной и эффективной в условиях изменения внешней среды [15].
В основе ИСМО лежат три модели, которые условно обозначены как «Сверточная нейронная сеть» (CNN), «LTN-сеть с правилами» (LTN – Logic Tensor Network, логическая тензорная сеть) и «Light LTN-сеть» (упрощенная тензорная сеть). Важно отметить, что модели работают независимо друг от друга. Они могут вызываться по указанному пользователем циклу или, при наличии необходимой мощности аппаратной части, параллельно.
Сверточная нейронная сеть, реализованная в системе как ObjectDetector, является базовой аналитической моделью, предназначенной для обнаружения объектов на изображениях. Ее архитектура разработана для эффективного извлечения признаков, их обработки и выполнения задач классификации и локализации объектов.
Light LTN-сеть, реализованная в системе как LightLtnDetector, представляет собой гибридную аналитическую модель, которая наследует архитектурные основы сверточной нейронной сети и дополняет их адаптерами для извлечения дополнительных признаков, подготавливая их для логических рассуждений. Эта модель занимает промежуточное положение между базовой сверточной сетью и полноценной LTN-сетью с логическими правилами, обеспечивая баланс между вычислительной эффективностью и интеграцией элементов нейросимвольного подхода.
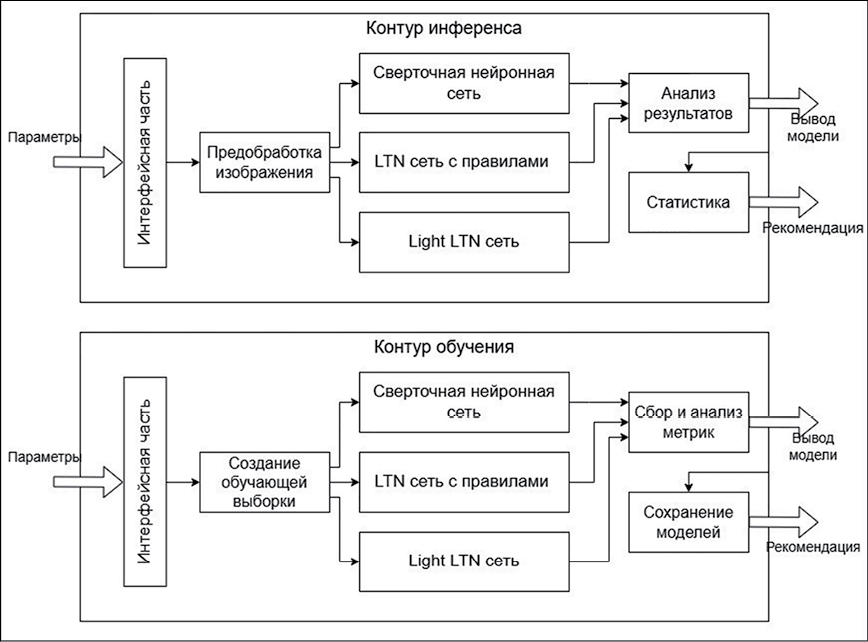
Рис. 1. Структура интеллектуальной системы Примечание: составлен авторами на основе полученных данных в ходе исследования
Математический аппарат LTN-сетей базируется на идее представления логических утверждений в виде тензорных операций, что обеспечивает их интеграцию в процесс обучения нейронной сети [16]. Модель LTN преобразует логику первого порядка в дифференцируемые функции потерь. Логические операторы (И, ИЛИ, НЕ) аппроксимируются с помощью непрерывных функций, таких как:
− логическое И:
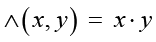 ;
;
− логическое ИЛИ:
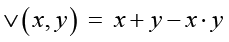 ;
;
− импликация:
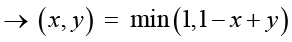 .
.
Логические правила формализуются как ограничения, добавляемые в функцию потерь модели [17]:
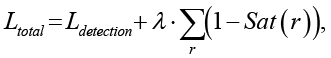 (1)
(1)
где Sat(r) – степень удовлетворения правила r, а λ – гиперпараметр, регулирующий влияние логики.
Такой подход позволяет модели совмещать обучение на данных с соблюдением логических правил, что критично для задач с ограниченной размеченной информацией, таких как обнаружение малых объектов.
В качестве развития рассмотренного выше LTN подхода авторами была разработана LTN-сеть с логическими правилами. Такая модель представляет собой наиболее сложную, гибридную аналитическую модель для обнаружения малых объектов с учетом априорных знаний и контекстных зависимостей. Эта модель сочетает элементы сверточных нейронных сетей и нейросимвольного подхода, расширяя возможности базовой сверточной сети и Light LTN-сети за счет интеграции логических ограничений.
В рамках проекта были добавлены два ключевых правила, формализующих априорные знания о структуре сцены: ограничение на перекрытие объектов и согласованность размеров.
Правило 1. Ограничение на перекрытие объектов. Семантика правила заключается в том, что объекты одного класса не должны значительно перекрываться. Математическая запись правила имеет вид:
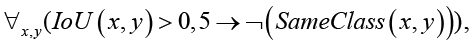 (2)
(2)
где IoU(x, y) – метрика перекрытия между боксами x и y, SameClass(x, y) – предикат совпадения классов.
Правило 2. Согласованность размеров. Семантика правила заключается в том, что размеры объектов в рамках одной сцены должны быть статистически однородными. Математическая запись правила имеет вид
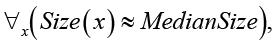 (3)
(3)
где 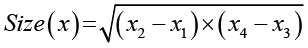 – площадь ограничивающей рамки, а MedianSize – медиана ограничивающих рамок.
– площадь ограничивающей рамки, а MedianSize – медиана ограничивающих рамок.
Интеграция этих двух правил в функцию потерь позволяет LTN-сети эффективно справляться с задачами, где визуальные признаки недостаточны для точного обнаружения. Например, в сценах с высокой плотностью объектов или шумом она может отфильтровать ложные предсказания, опираясь на априорные знания. Это делает ее наиболее продвинутым инструментом в системе, особенно для обнаружения малых объектов в условиях ограниченных данных.
Результаты исследования и их обсуждение
Для сравнительного анализа эффективности трех представленных выше модулей ИСМО был разработан программный прототип с использованием языка программирования Python и фреймворка PyTorch [18]. Для ускорения вычислений применяется GPU NVIDIA RTX 4060 8gb и набор CUDA Toolkit 12.4. Поскольку основное внимание в исследовании было уделено предлагаемой модификации – модели LTN-сети с логическими правилами, то для нее было реализовано три варианта: с весами логических правил λ = 0,1; λ = 0,25; λ = 0,5.
В качестве обучающего пакета использован общепринятый, находящийся в свободном доступе крупномасштабный датасет для обнаружения лиц WIDER Face [19]. Он содержит 32203 изображения с 393703 размеченных лиц, из которых 40 % – малые объекты (менее 32×32 пикселей). Один из тестовых примеров показан на рис. 2.
Необходимо было распознать пять малых «смазанных» объектов – лиц марширующих музыкантов. Базовая модель CNN-сети правильно распознала четыре из них, еще два лица отнесла к малым объектам, хотя их размеры превышают метрику COCO, а также «увидела» три объекта, не относящихся к лицам (рис. 2). Модель LtnDetector даже с весом λ = 0,25 правильно обнаружила все пять мелких объектов.
Результаты экспериментов «Оверфит на одной картинке» представлены в табл. 2.

Рис. 2. Инференс базовой модели (CNN) Примечание: составлен авторами на основе источника [19] и результатов исследования
Таблица 2
Результаты экспериментов «Оверфит-1»
|
Модель |
IoU |
mAP |
Precision |
Recall |
F1 Score |
|||||
|
Avg |
Max |
Avg |
Max |
Avg |
Max |
Avg |
Max |
Avg |
Max |
|
|
CNN |
0,956 |
0,993 |
0,000 |
0,001 |
0,000 |
0,016 |
0,041 |
0,290 |
0,001 |
0,022 |
|
Light LTN |
0,956 |
0,994 |
0,000 |
0,002 |
0,000 |
0,018 |
0,040 |
0,258 |
0,001 |
0,023 |
|
LTN λ = 0,1 |
0,835 |
0,948 |
0,000 |
0,000 |
0,000 |
0,002 |
0,013 |
0,129 |
0,000 |
0,004 |
|
LTN λ = 0,25 |
0,811 |
0,948 |
0,000 |
0,001 |
0,000 |
0,003 |
0,017 |
0,129 |
0,001 |
0,005 |
|
LTN λ = 0,5 |
0,776 |
0,936 |
0,000 |
0,000 |
0,000 |
0,003 |
0,001 |
0,065 |
0,000 |
0,006 |
Примечание: составлена авторами на основе результатов исследования
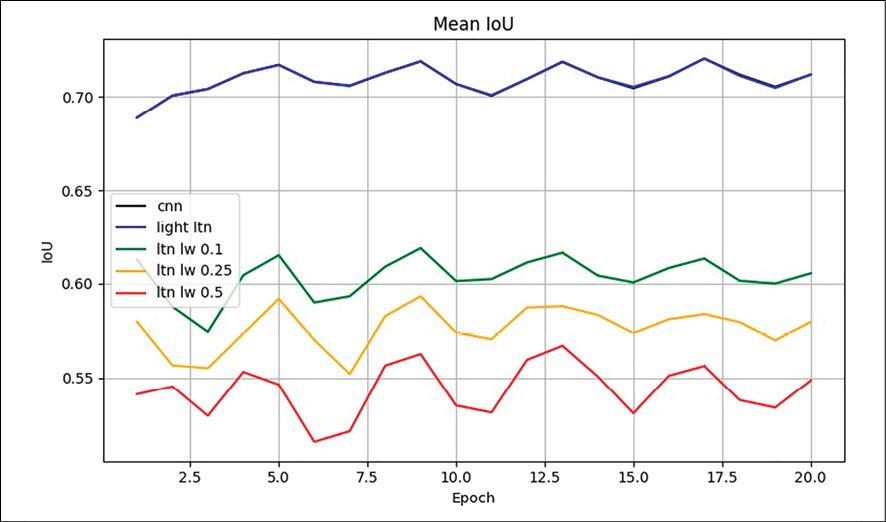
Рис. 3. Результаты экспериментов по метрике IoU Примечание: составлен авторами на основе результатов исследования
В качестве метрик для оценки эффективности моделей выбраны типовые показатели, используемые в области искусственных нейронных сетей и методов машинного обучения.
– Precision (Точность) – доля правильно предсказанных объектов.
– Recall (Полнота) – доля правильно определенных реальных объектов.
– mAP (Mean Average Precision) – средняя точность по всем классам.
– F1 Score – среднее гармоническое между Precision и Recall.
– Intersection over Union (IoU) – степень перекрытия между предсказанным и реальным ограничивающим прямоугольником.
Результаты экспериментов по метрике IoU приведены на рис. 3.
В базовой модели CNN степень расхождения между предсказанным и реальным ограничивающим прямоугольником составила более 80 % (на диаграмме не показана). Для фреймворка Light LTN расхождение обнаружено примерно в 70 % случаев. Модель LTN с весом λ = 0,5 практически в половине экспериментов (~50 %) правильно спрогнозировала наличие малого объекта на изображении. Если взять в качестве оппонента одну из самых лучших современных моделей обнаружения объектов DyHead [20], то метрика Intersection over Union для малых объектов на тестовом наборе COCO, полученная DyHead, составляет около 72 %.
Заключение
Проблема обнаружения малых объектов с помощью нейронных сетей является сложной и многогранной задачей, уходящей корнями в фундаментальные ограничения архитектуры CNN (потеря деталей при пулинге), дисбалансы в данных и сложность формирования информативных признаков из малого числа пикселей. Проведенное исследование подтвердило, что нейросимвольный подход преодолевает фундаментальные ограничения субсимвольных методов в задачах с дефицитом размеченных данных и высокой вариативностью сцен.
Предлагаемое архитектурно-структурное решение интеллектуальной системы служит основой для проведения экспериментов с различными конфигурациями, методами оптимизации и стратегиями аугментации, сохраняя при этом целостность и управляемость системы. Тестирование программного прототипа показало преимущества LTN-моделей над существующими проектами по основным метрикам прикладного искусственного интеллекта. Модифицированная версия ИСМО обеспечивает не только эффективное обучение моделей, но и прозрачность процесса, что критично для научно-исследовательских задач. Добавление в LTN-сети логических правил делает их наиболее продвинутым инструментом в интеллектуальных системах, особенно для обнаружения малых объектов в условиях ограниченности исходных данных и наличия шумов. Надежное обнаружение малых объектов критически важно для практических приложений, таких как анализ спутниковых снимков, видеонаблюдение (анализ лиц в толпе), медицинская диагностика, управление беспилотными автономными системами и т.п.
Конфликт интересов
Финансирование
Библиографическая ссылка
Долженкова М.Л., Махди М-А.Х., Мельцов В.Ю., Чистяков Г.А. ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ СОВРЕМЕННЫХ НЕЙРОСЕТЕВЫХ ТЕХНОЛОГИЙ ДЛЯ ОБНАРУЖЕНИЯ МАЛЫХ ОБЪЕКТОВ НА ИЗОБРАЖЕНИЯХ // Современные наукоемкие технологии. 2025. № 11. С. 30-36;URL: https://top-technologies.ru/ru/article/view?id=40563 (дата обращения: 01.08.2026).
DOI: https://doi.org/10.17513/snt.40563