



Введение
Проблема идентификации связей между исполнителем и задачей актуальна для организаций вне зависимости от типа организационных структур, видов экономической деятельности, организационно-правовой формы, целей деятельности и т.д. Особенно актуальна указанная проблема при рассмотрении потоковых задач, характеризующихся наличием множества возможных исполнителей со схожим квалификационным уровнем. Таким ярким примером является распределение дисциплин между преподавателями в организациях высшего образования [1; 2]. Процесс распределения задач трудозатратен по времени, а также усложняется при наличии множества сотрудников со схожими должностными обязанностями. При этом индивидуальные особенности сотрудника способствуют определению его предрасположенности к некоторым из имеющихся задач.
Для решения данной проблемы в работе [3] предложен подход, основанный на генерации разноуровневых рекомендаций возможных связей между исполнителем и задачей, а также обозначена потребность в решении задачи обработки входных данных для последующего формирования совокупности ключевых слов, являющихся основой дальнейшей генерации вариативных связей.
Источником входных данных выступают документы, содержащие в себе совокупность ключевых слов с различными весовыми коэффициентами значимости. Однако разнотипность и разнородность входного набора данных обуславливает потребность в разработке соответствующего алгоритма интеллектуальной поддержки его формирования.
В современных исследованиях рассматриваются различные методы и алгоритмы обработки текстовых данных. Работа [4] посвящена исследованию влияния предварительной обработки текстовых данных на эффективность нейросетевой модели для концептуальной разметки токенов. Кроме того, рассматривается предобработка данных с учетом лемматизации, удаления стоп-слов и разделителей предложений. В работах [5; 6] представлены особенности кластерного анализа слабоструктурированных текстовых данных, а также интеллектуальный метод и алгоритм обработки для классификации текстовых данных. Автор работы [7] рассматривает задачи и методы оптимизации состава исполнителей программ и проектов в системе стратегического планирования в условиях цифровизации государственного управления.
Однако указанные методы не ориентированы на обработку текстовых данных для последующей генерации ключевых слов и дальнейшего формирования разноуровневых связей между исполнителями и задачами, что обуславливает актуальность рассматриваемого алгоритма.
Цель исследования – разработка алгоритма, позволяющего сформировать входной набор данных с учетом их разнородности, для последующей генерации разноуровневых вариативных связей «исполнитель – задача». В рамках проводимого исследования понятие разнородности данных используется автором в контексте их различий по типу, структуре, формату, семантической значимости т.д. В качестве новизны разработанного алгоритма выступает установление синтеза между экспертами и методами интеллектуального анализа данных при формировании слабо формализованного входного признакового пространства.
Материалы и методы исследования
Источниками информации о задаче и исполнителе выступают различные как по типу (pdf, doc, почтовый формат, текстовые сообщения из используемых корпоративных систем), так и по содержанию (техническое задание, внутренний документ, резюме исполнителя и т.д.) документы. Ключевыми характеристиками для документа, на основании которого реализуется формирование входного набора данных, является формат и объем данных, принадлежность к характеризующемуся объекту, семантическая значимость, а также источник поступления, способствующий определению уровня документационной значимости. В исследовании формирование входного набора данных и последующее тестирование работы представленного алгоритма рассмотрено на примере источников информации в отношении кафедры прикладной математики Института информационных технологий РТУ МИРЭА.
Поскольку документы, характеризующие как исполнителя, так и задачу, представляют собой формализованные совокупности текстовых данных, основой формирования связи «исполнитель – задача» выступают ключевые слова. При этом в зависимости от семантической значимости ключевые слова обладают различными весовыми коэффициентами. Формирование ключевых слов целесообразно осуществлять с применением методов векторизации. При обработке текстовой информации для последующего решения задач в различных областях широко используется метод TF-IDF. Исследования [8-10], направленные на обнаружение фейковых новостей, разработку системы рекомендаций по вакансиям, а также поиск документов в медицинской карте, рассматриваются с применением данного метода.
Выявление семантически значимых ключевых слов из совокупности документационной базы требует многоэтапной аналитической обработки и включает в себя в том числе применение методов векторизации, позволяющих перевести текстовую информацию в числовое пространство признаков, использование метрик оценки для определения точности и полноты результатов, а также для верификации и корректировки результатов предусматривается этап экспертной оценки с привлечением специалистов соответствующей предметной области. Проведение экспертного оценивания целесообразно осуществлять с применением многоуровневой взвешенной оценки. Корректировка количества экспертных групп и их весовых коэффициентов реализуется с учетом особенностей рассматриваемой задачи.
Результаты исследования и их обсуждение
Разработанный алгоритм формирования входного набора данных, как инструмент интеллектуальной поддержки принятия управленческих решений в организационных системах, включает в себя определенную последовательность этапов.
1 этап. Осуществление выбора основного документа D в качестве входного признакового пространства.
2 этап. Реализация разделения документа на составные части: D = {d1…dn}. Данный этап направлен на осуществление дальнейшего выбора наилучшего элемента для обработки и анализа для получения содержательного результата. На рисунке 1 приведен пример разделения рабочей программы дисциплины на несколько содержательных блоков, характеризующихся различной степенью концентрации информации.
На рисунке 2 представлен разработанный алгоритм интеллектуальной поддержки формирования входного набора данных для последующей генерации связей «исполнитель – задача» с описанием этапов.
3-5 этапы. Проведение экспертной оценки каждой из составных частей документа, по результатам которой определяется необходимая для дальнейшей загрузки и обработки часть или же части основного документа. В целях улучшения достоверности и точности возможна обработка нескольких частей в рамках одного исходного документа. В случае проведения некорректной оценки осуществляется повторение цикла экспертной оценки до итогового определения оптимальной части/частей документа. Некорректной считается оценка, при которой сумма количества частей документа с равной максимальной экспертной оценкой составляет не более 50% от общего числа рассматриваемых частей документа.
На примере рабочей программы дисциплины, разделенной на четыре части, рассмотрим проведение их оценки с привлечением экспертов из трех групп, имеющих различный вес с учетом их компетенций. Оценка проводится по пятибалльной шкале, где 5 – высокая семантическая значимость, 1 – семантическая значимость отсутствует (табл. 1 и 2).
Учитывая представленные корректирующие коэффициенты значимости экспертной группы, экспертная оценка каждой из частей документа будет иметь следующий вид:
К = 0,5 ∙ х1 + 0,3 ∙ х2 + 0,2 ∙ х3 ,
где х1, х2 и х3 – средняя оценка каждой из трех представленных групп соответственно.
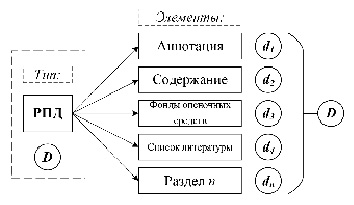
Рис. 1. Схема разделения документа рабочей программы дисциплины на составные части Источник: составлено автором
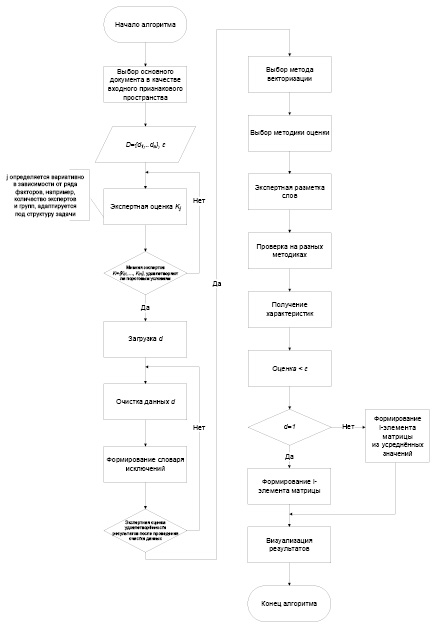
Рис. 2. Блок-схема алгоритма интеллектуальной поддержки формирования входного набора данных Источник: составлено автором
Таблица 1
Пример результатов экспертной оценки по пятибалльной шкале
|
Группа |
Коэффициент |
Эксперт |
Экспертная оценка от 1 до 5 |
|||
|
Часть 1 |
Часть 2 |
Часть 3 |
Часть 4 |
|||
|
Старшая |
0,5 |
Эксперт 1 |
1 |
2 |
5 |
4 |
|
Эксперт 2 |
2 |
3 |
4 |
4 |
||
|
Эксперт 3 |
2 |
1 |
5 |
4 |
||
|
Средняя |
0,3 |
Эксперт 1 |
4 |
2 |
3 |
5 |
|
Эксперт 2 |
2 |
5 |
4 |
3 |
||
|
Младшая |
0,2 |
Эксперт 1 |
4 |
5 |
3 |
3 |
|
Эксперт 2 |
5 |
3 |
2 |
4 |
||
|
Эксперт 3 |
1 |
5 |
3 |
4 |
||
|
Эксперт 4 |
2 |
3 |
4 |
5 |
||
Примечание: составлено автором по данным проведенного исследования.
Таблица 2
Пример групповых результатов экспертной оценки
|
Фрагмент документа |
Средняя оценка группы |
Оценка с учетом коэффициента |
||||
|
Старшая |
Средняя |
Младшая |
Старшая |
Средняя |
Младшая |
|
|
Часть 1 |
1,7 |
3 |
3 |
0,85 |
0,9 |
0,6 |
|
Часть 2 |
2 |
3,5 |
4 |
1 |
1,05 |
0,8 |
|
Часть 3 |
4,7 |
3,5 |
3 |
2,35 |
1,05 |
0,6 |
|
Часть 4 |
4 |
4 |
4 |
2 |
1,2 |
0,8 |
Примечание: составлено автором по данным проведенного исследования
Таким образом, наивысшую экспертную оценку семантической значимости имеют сразу две части – третья и четвертая (4 балла). Итоговая экспертная оценка первой и второй частей составляет 2,35 балла и 2,85 балла соответственно. Проведенная оценка считается корректной, так как сумма количества частей документа с равной максимальной экспертной оценкой составляет не более 50% от общего числа рассматриваемых частей документа.
6-8 этапы. Выполнение очистки данных, сопровождаемой экспертной оценкой, для формирования словаря исключений. На примере рабочей программы дисциплины рассмотрим выполнение данных этапов. Предварительная очистка текста включает в себя три шага: очистить строки от кодов компетенций; удалить слова, обозначающие вид занятий; удалить отдельно стоящие цифры, обозначающие номер семестра и объем часов.
В ходе эксперимента выявлена необходимость дополнительной очистки содержания дисциплины для улучшения получаемого результата. При проведении первых нескольких попыток выделения ключевых слов обнаружены слова, не отражающие содержательную часть дисциплины (рис. 3). По результатам экспертной оценки формируется список исключенных слов, который может быть дополнен при анализе содержания других дисциплин. Отрицательный результат при формировании ключевых слов без использования разработанного алгоритма интеллектуальной поддержки формирования входного набора данных подтверждает его практическую значимость.
9 этап. Выбор метода векторизации. Преимуществом TF-IDF является быстрота и простота применения, однако данный метод не учитывает семантических, то есть смысловых отношений слов [11; 12]. Word2Vec предсказывает вероятность слова по его контексту и наоборот, данная модель ограничена локальным контекстным окном, но эффективна для семантических задач [13; 14]. Выбор метода осуществляется, исходя из специфики задачи и входного набора данных.
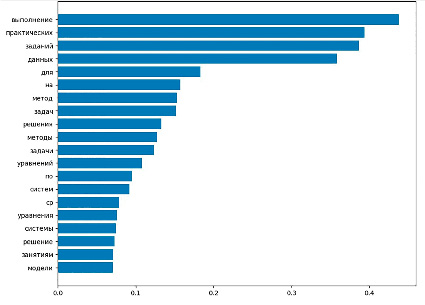
Рис. 3. Результаты выявления ключевых слов после предварительной очистки текста содержания дисциплин Источник: составлено автором
10 этап. Осуществление выбора методики оценки. Для проверки точности полученных результатов работы алгоритма целесообразно провести оценку, используя различные метрики: Accuracy, которая отражает долю верно классифицированных объектов относительно общего количества; Precision, характеризующая долю истинно положительных случаев среди всех объектов, классифицированных как положительные; Recall, демонстрирующая способность модели идентифицировать все релевантные положительные примеры; и Fβ-мера, которая представляет собой гармоническое среднее между Precision и Recall с возможностью регулировки весов [15].
11-14 этапы. Выполнение экспертной разметки слов с предварительным сокращением количества результатов для уменьшения времени экспертного анализа и улучшения эффективности за счет концентрации на наиболее релевантных терминах. Затем выполнение проверки, последующее получение характеристик и переход к этапу оценки с учетом допустимого диапазона значений.
15 этап. Проверка количества обработанных частей документа. С учетом широкой вариативности задач и особенностей исполнителей источником формирования входного набора могут выступать несколько семантически важных частей одного исходного документа, в связи с чем в алгоритме предусмотрено формирование двух видов элементов матрицы.
16 этап. Визуализация результатов является заключительным этапом работы алгоритма. На рисунке 4 представлено облако слов, сформированное с применением метода векторизации TF-IDF для дисциплины «Большие данные».
Такое сочетание методов интеллектуальной поддержки и экспертного анализа способствует обеспечению высокой достоверности получаемых результатов. Результаты, полученные с применением алгоритма интеллектуальной поддержки формирования входного набора данных, в дальнейшем будут использованы для генерации разноуровневых связей в системе рекомендаций «исполнитель – задача», включающей оценку их достоверности, проведение которой выходит за рамки текущего исследования.

Рис. 4. Визуализация результатов работы алгоритма для дисциплины «Большие данные» Источник: составлено автором
Такая система рекомендаций реализует двунаправленную функциональность: с одной стороны, она обеспечивает генерацию набора возможных исполнителей для конкретной задачи, с другой – формирует перечень релевантных задач для конкретного исполнителя.
Ключевыми этапами формирования входного набора данных для последующего установления взаимосвязей «исполнитель – задача» являются: формирование многоуровневой экспертной группы; верификация входного набора данных; предобработка данных с учетом экспертной оценки; интеллектуализация формирования ключевых слов.
Основным условием применения представленного алгоритма является наличие семантически значимого документа, выступающего в качестве входного признакового пространства. В качестве незначительного ограничивающего фактора может выступать формат исходного документа, в частности его представление в виде изображения. В подобных случаях необходимо дополнение этапов работы алгоритма в части извлечения текстовых данных из графического представления для реализации дальнейшей обработки.
Заключение
Представленный в исследовании алгоритм выступает составной частью подхода, реализующего интеллектуальную поддержку принятия решения при формировании связи «исполнитель – задача» в целях повышения эффективности функционирования организационных систем, направленного на генерацию разноуровневых рекомендаций возможных связей. Стоит отметить, что проблема идентификации связей между исполнителем и задачей является актуальной для организаций вне зависимости от типа организационных структур. Основой для реализации указанного подхода выступают ключевые слова с различными весовыми коэффициентами значимости, источником формирования которых являются разнотипные документы. При этом разнородность входного признакового пространства обуславливает потребность в разработке алгоритма интеллектуальной поддержки формирования входного набора данных. В отличие от существующих решений разработанный алгоритм отличается установлением синтеза между экспертами и методами интеллектуального анализа данных при формировании слабо формализованного входного признакового пространства. Применение алгоритма позволяет улучшить качество входного набора данных в целях увеличения точности при последующем установлении разноуровневых связей между исполнителем и задачами в рамках подхода, реализующего интеллектуальную поддержку принятия решения.
Конфликт интересов
Библиографическая ссылка
Пучкова М.А. АЛГОРИТМ ИНТЕЛЛЕКТУАЛЬНОЙ ПОДДЕРЖКИ ПРИНЯТИЯ РЕШЕНИЯ ПРИ ФОРМИРОВАНИИ ВХОДНОГО НАБОРА ДАННЫХ ДЛЯ ПОСЛЕДУЮЩЕГО УСТАНОВЛЕНИЯ ВЗАИМОСВЯЗЕЙ «ИСПОЛНИТЕЛЬ – ЗАДАЧА» // Современные наукоемкие технологии. 2025. № 8. С. 29-36;URL: https://top-technologies.ru/ru/article/view?id=40461 (дата обращения: 21.06.2026).
DOI: https://doi.org/10.17513/snt.40461