



Введение
В настоящее время в современной медицине отмечается рост распространенности хронических неинфекционных заболеваний (ХНИЗ), таких как сахарный диабет, сердечно-сосудистая патология, хроническая бронхолегочная патология и др. Эти заболевания оказывают существенное негативное влияние на продолжительность и качество жизни пациентов.
В свете повсеместной цифровизации и постоянного увеличения объемов медицинских данных методы машинного обучения (ML) представляют собой мощный инструмент для выявления лиц, входящих в группу риска развития ХНИЗ [1, 2]. Точное и своевременное определение группы риска позволяет улучшить результативность проводимых профилактических мероприятий и повысить эффективность лечебно-диагностического процесса. При этом для обеспечения точности и надежности прогнозов важно подобрать и адаптировать алгоритмы машинного обучения с учетом специфики медицинских данных, разнообразия клинических показателей и наличия пропусков и иных искажений в исходных данных.
Цель исследования – построение классификатора и оценки качества классификации пяти алгоритмов – случайного леса, градиентного бустинга, XGBoost, метода k-ближайших соседей и рекуррентной нейронной сети с ячейками долгой краткосрочной памяти (LSTM).
Материалы и методы исследования
Для решения задачи классификации в данной работе рассмотрены следующие алгоритмы: Random Forest (RF) – ансамблевый метод, способный обрабатывать нелинейные зависимости, что в свою очередь обеспечивает вывод интерпретируемых результатов через значения важности признаков [3, 4]; Gradient Boosting (GB) – продвинутый алгоритм машинного обучения для решения задач классификации и регрессии. Он строит предсказание в виде ансамбля слабых предсказывающих моделей, которыми в основном являются деревья решений [5, 6]; XGBoost (XGB) представляет собой усовершенствованный градиентный бустинг [7, 8], он достаточно эффективен на малых и несбалансированных выборках; метод K-ближайших соседей (kNN) – простой алгоритм, анализирующий расстояния между точками [9, 10], который подходит для данных с небольшим числом признаков; LSTM – это рекуррентная нейронная сеть, способная учитывать временные зависимости и сложные зависимости между признаками [11, 12] с использованием оптимизатора Adam. Для обучения моделей использован массив эмпирических данных: 1843 записи о взрослых пациентах, наблюдавшихся в ОГБУЗ «Иркутская городская клиническая больница № 3» г. Иркутска в период с 2021 по 2023 г. Собранный датасет содержит различные факторы риска (ФР), представленные в табл. 1, и целевую переменную – диагноз «артериальная гипертензия». Целевая переменная делит пациентов на три класса: Класс 0 (Здоров): пациент не имеет хронического заболевания; класс 1 (Заболевание): установлен диагноз «артериальная гипертензия»; класс 2 (Риск): высокая вероятность постановки диагноза в будущем.
Так как в датасете имеется дисбаланс классов, то в процессе обработки и анализа были использованы следующие операции:
1. Стратифицированное разбиение выборки – сохранение пропорций классов при разделении данных, при этом 70 % записей использовалось для обучения, 30 % – для тестирования.
2. Метрики, устойчивые к дисбалансу, такие как ROC-AUC и F1-мера.
3. Балансировка весов классов – автоматическое увеличение значимости меньших классов в градиентных методах.
Для проведения исследования было применено следующее программное обеспечение:
1) один из самых популярных языков программирования для машинного обучения и анализа данных – Python;
2) Google Colab – облачная среда для разработки на Python [13], которая особенно удобна для решения ML-задач.
Для нормализации данных использовался StandardScaler с целью приведения значений переменных к единому масштабу. Для модели LSTM данные преобразовывались в трехмерный формат (samples, timesteps, features), чтобы учесть сложные зависимости.
Таблица 1
Факторы риска
|
Переменная |
Описание |
|
Избыточная масса тела |
Индекс массы тела выше 25 |
|
Курение |
Наличие вредной привычки |
|
Алкоголь |
Наличие вредной привычки |
|
Гиподинамия |
Низкий уровень физической активности |
|
Нерациональное питание |
Нарушение сбалансированности рациона |
|
Гиперхолистеринемия |
Повышенный уровень холестерина |
Источник: составлено авторами.
Для моделей Random Forest, Gradient Boosting, kNN была использована библиотека Scikit-learn, улучшенный градиентный бустинг реализован с использованием одноименной библиотеки XGBoost, а LSTM (Long Short-Term Memory) реализована с помощью библиотек TensorFlow и Keras [13].
Для оценки качества классификации моделей применялись следующие метрики [14, 15]:
1. Accuracy – отражает долю правильно прогнозируемых событий относительно их общего числа:
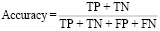 ,
,
где TP (True Positive) – количество истинно положительных предсказаний (модель правильно определила положительный класс), TN (True Negative) – количество истинно отрицательных предсказаний (модель правильно определила отрицательный класс), FP (False Positive) – количество ложно положительных предсказаний (модель ошибочно определила отрицательный класс как положительный), FN (False Negative) – количество ложно отрицательных предсказаний (модель ошибочно определила положительный класс как отрицательный).
2. Recall (Полнота) – доля корректно распознанных положительных событий для каждого класса:
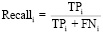 , i ∈ {0,1,2}.
, i ∈ {0,1,2}.
3. Precision (Точность) – это метрика, которая измеряет, насколько точно модель классифицирует положительные случаи. Она показывает, сколько объектов, предсказанных моделью как положительные, действительно являются положительными.
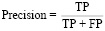 .
.
4. F1-мера: взвешенное среднее точности и полноты:
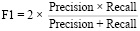 .
.
5. Метрика ROC-AUC отражает среднюю площадь под ROC-кривой [13] для классов (One-vs-Rest):
ROC-AUCс ред 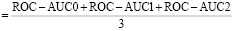 .
.
Таблица 2
Сравнительный анализ метрик оценки.
|
Алгоритм |
Accuracy |
Recall (сред.) |
F1-мера (сред.) |
ROC-AUC (сред.) |
|
Random Forest |
0,93 |
0,87 |
0,89 |
0,978 |
|
Gradient Boosting |
0,93 |
0,88 |
0,90 |
0,975 |
|
XGBoost |
0,92 |
0,86 |
0,88 |
0,973 |
|
kNN |
0,88 |
0,82 |
0,84 |
0,928 |
|
LSTM |
0,94 |
0,89 |
0,91 |
0,977 |
Источник: составлено авторами.
Результаты исследования и их обсуждение
В табл. 2 представлены результаты расчета основных метрик по всем моделям. Согласно им, наилучшая модель по пяти метрикам – LSTM, она хорошо справляется с задачами, где важно минимизировать пропуски. В качестве альтернативы высокую эффективность и стабильные результаты показывают Random Forest, Gradient Boosting, XGBoost. kNN показывает худшие результаты по всем метрикам.
На рис. 1–5 представлены графики кривой ROC-AUC, которые позволяют оценить качество срабатывания классификационной модели, где ось Х отражает FPR (False Positive Rate) – ложно положительное срабатывание, а ось Y – TPR (True Positive Rate) – истинно положительное срабатывание.
На основе матриц ошибок и значений ROC-AUC для всех моделей можно провести сравнительный анализ ошибок классификации с акцентом на FP (ложно положительные) и FN (ложно отрицательные) ошибки.
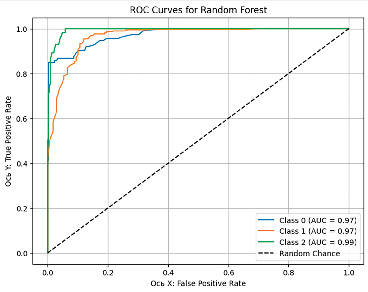
Рис. 1. ROC-AUC кривая модели Random Forest Источник: составлено авторами
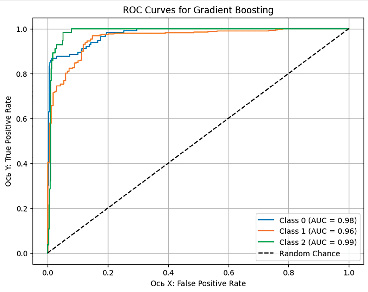
Рис. 2. ROC-AUC кривая модели Gradient Boosting Источник: составлено авторами
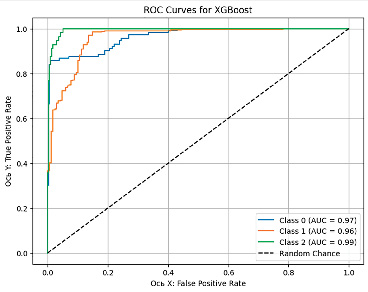
Рис. 3. ROC-AUC кривая модели XGBoost Источник: составлено авторами
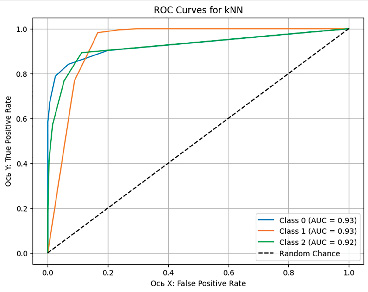
Рис. 4. ROC-AUC кривая модели kNN Источник: составлено авторами
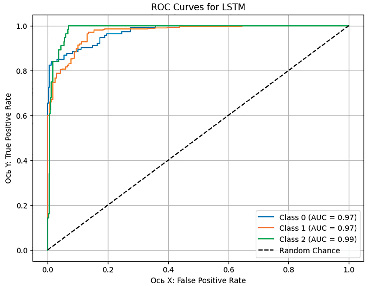
Рис. 5. ROC-AUC кривая модели LSTM Источник: составлено авторами
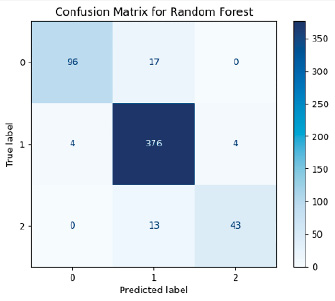
Рис. 6. Матрица ошибок модели Random Forest Источник: составлено авторами
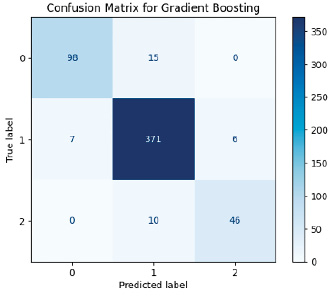
Рис. 7. Матрица ошибок модели Gradient Boosting Источник: составлено авторами
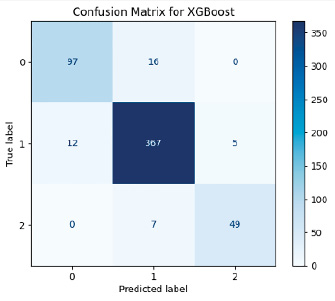
Рис. 8. Матрица ошибок модели XGBoost Источник: составлено авторами
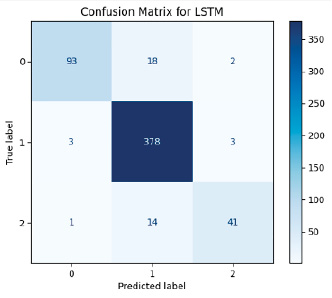
Рис. 9. Матрица ошибок модели kNN Источник: составлено авторами
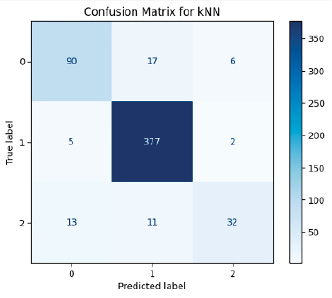
Рис. 10. Матрица ошибок модели LSTM Источник: составлено авторами
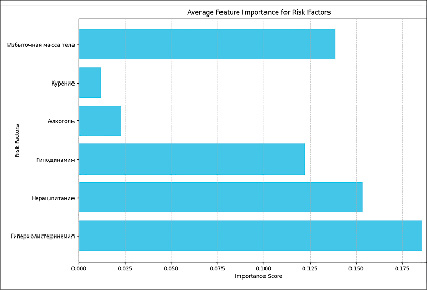
Рис. 11. Средняя важность факторов риска Источник: составлено авторами
Для решения поставленной задачи, с использованием алгоритмов машинного обучения, анализ данных метрик является важным этапом, при этом высокое значение FN более критично, чем FP, так как это ведет к пропуску диагностики пациентов, требующих внимания (высокое значение FP приводит к лишним и часто ненужным медицинским вмешательствам). На рис. 6–10 приведены матрицы ошибок, рассчитанные на основе тестовой выборки (30 % от исходного датасета).
Анализ моделей показал, что универсального идеального алгоритма не существует, выбор метода зависит от целей применения. Для диагностики больных пациентов (класс 1) Gradient Boosting и LSTM является хорошим выбором благодаря высокой точности и минимальным FN-ошибкам. С прогнозированием группы риска (класс 2) лучше прочих справились Gradient Boosting и XGBoost, что делает их применимыми в задачах профилактической медицины. Для общей классификации Random Forest остается неплохим вариантом, однако возможная путаница между классами 1 и 2 затрудняет четкое разделение больных и предрасположенных к заболеванию пациентов. Метод kNN показал низкую эффективность и не рекомендуется для решения данной задачи.
Для моделей можно оценить значимость факторов в классификации. Важность рассчитывается различными способами для моделей: через разбиения деревьев, частоту использования признаков или путем перестановочных оценок. На рис. 11 приведена усредненная гистограмма оценки важности факторов риска.
Наиболее значимыми факторами риска оказались гиперхолистеринемия, нерациональное питание и избыточная масса тела.
Заключение
Результаты проведенного исследования продемонстрировали хорошую эффективность применения алгоритмов машинного обучения для прогнозирования групп риска ХНИЗ. В условиях цифровизации медицины и накопления большого количества медицинских данных такие методы позволяют автоматизировать процесс предварительной диагностики и прогнозирования заболеваний, а также повышать качество и скорость принятия врачебных решений.
В ходе исследования были протестированы пять алгоритмов машинного обучения: Random Forest, Gradient Boosting, XGBoost, kNN и LSTM. На основе анализа базовых метрик лидирующие позиции занимают следующие модели: Gradient Boosting и LSTM. Они демонстрируют достаточную точность для решения задач классификации. Random Forest, Gradient Boosting и XGBoost обеспечили хорошую интерпретируемость факторов риска. Метод kNN показал наихудшие результаты, особенно в отношении прогнозирования группы риска, что делает его наименее подходящим для данной задачи.
Таким образом, использование ансамблевых методов (Gradient Boosting, XGBoost) и нейросетевых подходов (LSTM) является наиболее оправданным для задач медицинского прогнозирования, а использование более объемных и разнообразных медицинских данных (например, данных лабораторной диагностики и дополнительных исследований – МРТ и КТ) позволит решать более сложные задачи скоринговой диагностики заболеваний. Внедрение технологий машинного обучения в сферу здравоохранения является перспективным направлением, способствующим повышению эффективности медицинской диагностики и улучшению качества жизни пациентов.
Конфликт интересов
Библиографическая ссылка
Королева Я.А., Родионов А.В. ПРИМЕНЕНИЕ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ОПРЕДЕЛЕНИЯ ГРУПП РИСКА ХРОНИЧЕСКИХ ЗАБОЛЕВАНИЙ СРЕДИ ПАЦИЕНТОВ // Современные наукоемкие технологии. 2025. № 6. С. 29-38;URL: https://top-technologies.ru/ru/article/view?id=40419 (дата обращения: 21.06.2026).
DOI: https://doi.org/10.17513/snt.40419